
About
Seedance 1.0 is ByteDance’s flagship bilingual video generation foundation model. It is now available on GMI Cloud inference engine. Designed to address long-standing challenges in high-fidelity video synthesis, Seedance 1.0 delivers leading performance across text-to-video (T2V) and image-to-video (I2V) tasks, combining instruction adherence, motion stability, and efficient inference into a single unified model. Check out their technical report here.
Why Seedance 1.0?
Seedance 1.0 integrates innovations across data curation, architecture design, post-training optimization, and inference acceleration, resulting in:
- High-Resolution Video Synthesis — Generates a 5-second, 1080p clip in just 41.4 seconds on NVIDIA L20 GPUs.
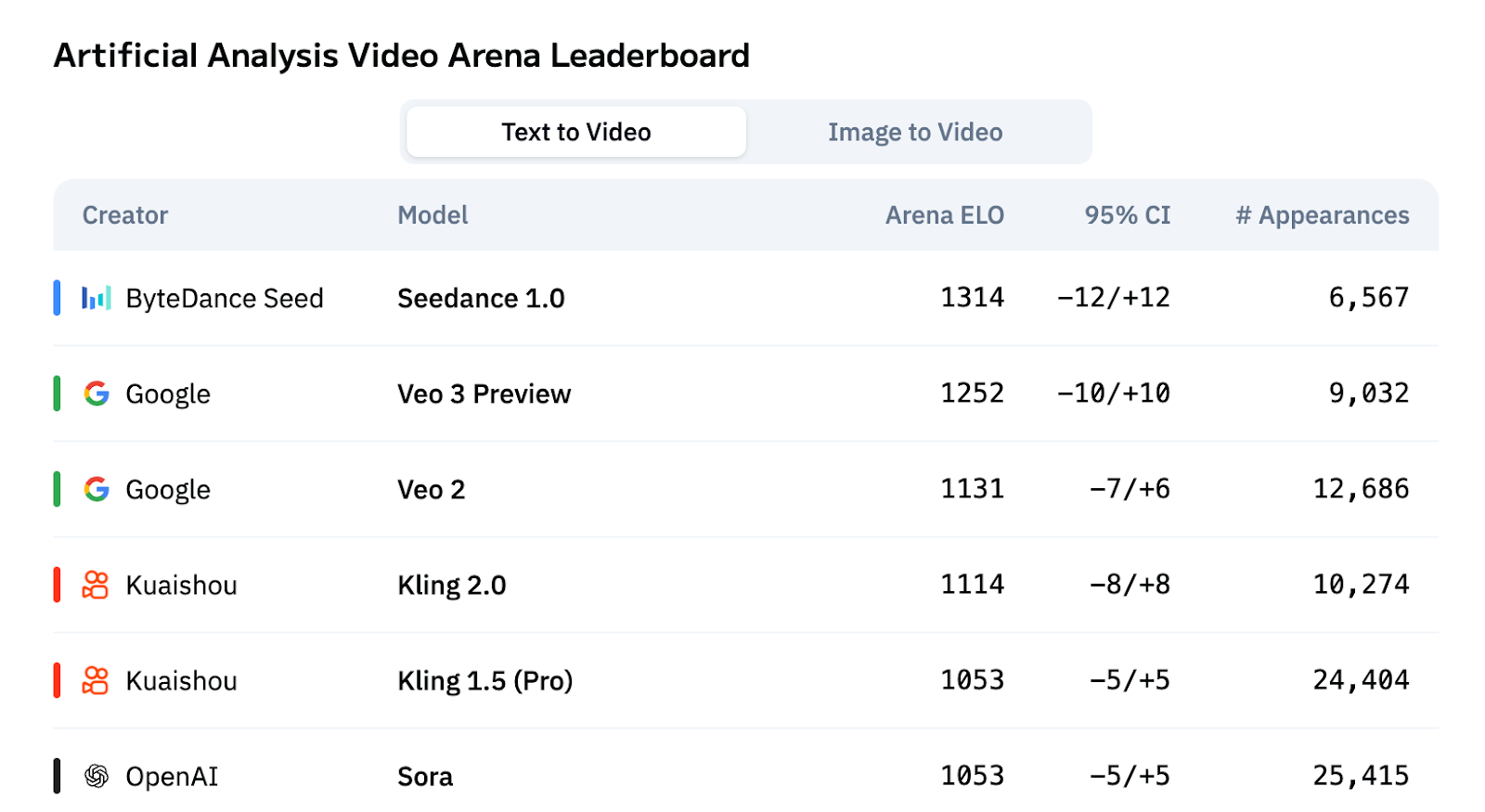
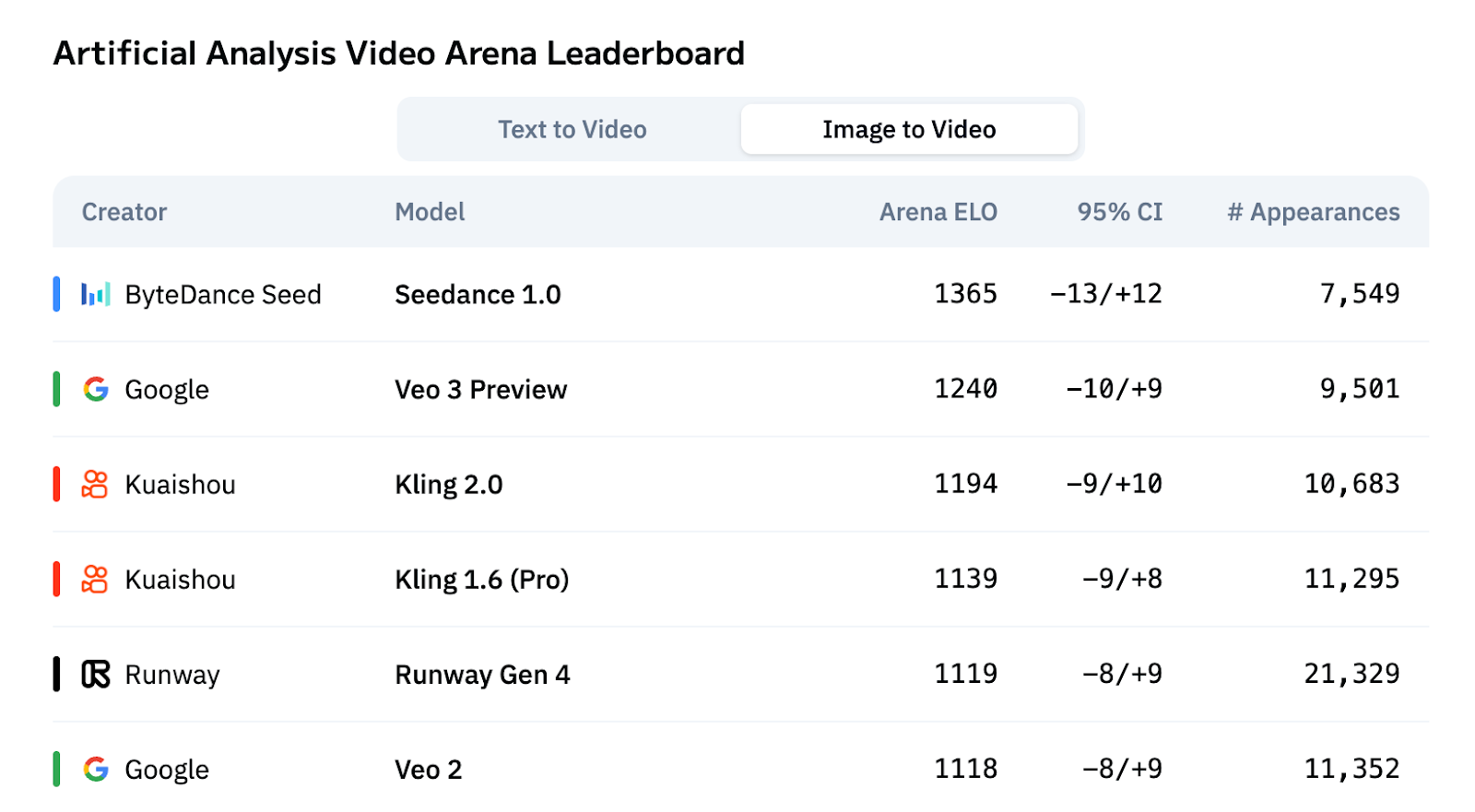
- Benchmark Leadership — Ranked #1 on Artificial Analysis Video Arena for both T2V and I2V tasks.
- Multi-Shot Narrative Coherence — Maintains subject consistency and seamless transitions across scene cuts.
- Flexible Style Alignment — Supports diverse cinematic aesthetics, from photorealistic visuals to animated sequences.
- Bilingual Generation — Natively supports both English and Chinese, expanding cross-lingual creative workflows.
Key Innovations
1. Dataset and Captioning
Seedance 1.0 is trained on a large-scale, multi-source bilingual dataset paired with dense video captions. This enables precise understanding of complex prompts and improves semantic alignment across varied scenarios, styles, and motion dynamics.
2. Unified Diffusion Transformer Architecture
The model employs a decoupled spatial-temporal attention design within a multi-modal diffusion transformer:
- Spatial layers focus on per-frame fidelity and compositional detail.
- Temporal layers ensure coherent motion trajectories and stable multi-shot transitions.
3. Video-Specific RLHF
Seedance 1.0 integrates a multi-dimensional reward framework:
- Foundational reward model improves image-text alignment and structure.
- Motion reward model enhances motion plausibility and temporal smoothness.
- Aesthetic reward model optimizes for perceptual quality using keyframe-based evaluation.
This cascaded RLHF approach improves prompt following, motion realism, and visual fidelity simultaneously.
4. Inference Acceleration
A multi-stage distillation framework and kernel-level optimizations enable 10× faster inference without compromising output quality:
- Multi-stage distillation framework uses techniques like Trajectory-Segmented Consistency Distillation (TSCD) and scores distillation to minimize diffusion steps, achieving faster inference without quality loss.
- Kernel-level optimizations applies fused GPU kernels, quantization, and memory-efficient scheduling to maximize throughput and reduce latency during video generation.
Benchmark Results
Seedance 1.0 sets a new standard in video generation benchmarks:
- Artificial Analysis Video Arena
- Text-to-Video → Top scores in motion quality, visual fidelity, and prompt alignment.
- Image-to-Video → Outperforms Veo 3, Kling 2.1, and Runway Gen4, achieving superior subject preservation and style consistency.
Get Started
Seedance 1.0 is now available on GMI Cloud. Developers, researchers, and enterprises can deploy the model today to build multi-shot, style-consistent, high-resolution videos at scale.
Explore Seedance 1.0 on GMI Cloud Playground
About GMI Cloud
GMI Cloud is a high-performance AI cloud platform purpose-built for running modern inference and training workloads. With GMI Cloud Inference Engine, users can access, evaluate, and deploy top open-source models with production-ready performance.
Explore more hosted models → GMI Model Library
Frequently Asked Questions
1. What is Seedance 1.0 and what problem does it address?
Seedance 1.0 is ByteDance’s flagship bilingual video generation foundation model, now available on the GMI Cloud inference engine. It is designed to solve key challenges in high-fidelity video synthesis by combining strong instruction adherence, stable motion, and efficient inference across both text-to-video and image-to-video tasks.
2. Why does Seedance 1.0 stand out compared to other video generation models?
Seedance 1.0 delivers leading performance in benchmarks and real-world generation. It can generate a 5-second 1080p video in 41.4 seconds on NVIDIA L20 GPUs, ranks #1 on the Artificial Analysis Video Arena for both T2V and I2V tasks, and maintains strong subject consistency, cinematic quality, and multi-shot narrative coherence.
3. How does Seedance 1.0 handle motion and multi-shot video consistency?
The model uses a unified diffusion transformer with decoupled spatial-temporal attention. Spatial layers focus on per-frame detail and composition, while temporal layers ensure smooth motion trajectories and seamless transitions across multiple shots, preserving subject identity and scene continuity.
4. What role does RLHF play in Seedance 1.0’s video quality?
Seedance 1.0 incorporates a video-specific, multi-dimensional RLHF framework that combines foundational, motion, and aesthetic reward models. This approach improves image-text alignment, motion realism, temporal smoothness, and overall perceptual quality simultaneously.
5. How does GMI Cloud enable efficient deployment of Seedance 1.0?
On GMI Cloud, Seedance 1.0 benefits from advanced inference acceleration, including multi-stage distillation and kernel-level optimizations such as fused GPU kernels, quantization, and memory-efficient scheduling. This allows developers, researchers, and enterprises to deploy high-resolution, style-consistent video generation at scale with production-ready performance.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
