
TL;DR: The excitement around DeepSeek V4 is real. While the benchmarks are still rumors, the three architectural papers DeepSeek has already published describing a new memory-centric design give us a clear picture of a model that could fundamentally change the game for long-context reasoning, agentic capabilities, and inference economics. This post breaks down the architecture, speculates on what it enables, and provides the technical context you need to understand what’s coming.
The AI builder community is collectively refreshing their feeds waiting for DeepSeek V4. The reason isn't the supposed benchmarks as those are still rumors sourced from a deleted Reddit post and a single tweet. Instead, many are excited about the expected architecture. DeepSeek has published three papers in the past two months that describe a model design unlike anything currently in production. If V4 ships with all three layers live simultaneously, it will be a genuinely different class of model we haven’t truly seen.
This post is for builders and enthusiasts who want to go deeper than the rumor mill. We’ll look at what makes V4 so exciting by breaking it down into three parts:
- The Architectural Leap: The three papers that describe V4's design and why they matter.
- What V4 Could Be (Speculation): The new capabilities this architecture might unlock.
- The Big Picture: The competitive and hardware context surrounding the release.
1. The Architectural Leap: Three Papers, One System
Between December 2025 and January 2026, DeepSeek published three papers that, read together, describe a new blueprint for large-scale models. They represent a shift from pure compute to a more balanced, memory-centric design.

- Paper: mHC: Manifold-Constrained Hyper-Connections
- Paper: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
- Paper: DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
These aren't independent research threads. The Engram paper uses mHC as its foundation, and the FlashMLA repository (DeepSeek's production attention kernel library) was updated with MODEL1 references nine days after the Engram paper was submitted. The vLLM team has already documented the serving complexity of DSA from V3.2. This three-layer stack is the reason for the hype. It's a design that makes models both smarter and cheaper to run simultaneously, not as a trade-off.
From Paper to Production: Implementing Engram-Ready Workflows
The promise of Engram is that it separates the what from the how.
- The what is the knowledge base: the corpus of documents, code, or data the model needs to internalize.
- The how is the complex machinery underneath: memory offloading, sparse attention indexing, and the serving configuration that makes it run at acceptable latency.
In practice, an Engram-ready workflow requires three things from the developer side. First, you need to structure your knowledge corpus so that static, high-frequency patterns (factual recall, common code idioms, domain terminology) can be cleanly separated from the dynamic reasoning tasks you want the GPU to handle. Second, your serving infrastructure needs to support the dual K-cache layout that DSA requires: the vLLM team's V3.2 implementation documents this clearly, noting that the indexer K cache and the MLA K cache must be managed in separate buffers. Third, prefill-decode disaggregation is not optional at scale: it's the first thing that breaks when you try to run long-context DSA requests through a naive serving stack.
The infrastructure layer is where most teams will stumble. The model weights are the easy part.
Visualizing the Memory Shift: Engram vs. Standard Transformers
The architectural shift from a standard Transformer to an Engram-based model is best understood as a rebalancing of resources. Where a traditional model keeps all its knowledge in expensive, high-speed GPU memory, Engram partitions it between the GPU and host DRAM.
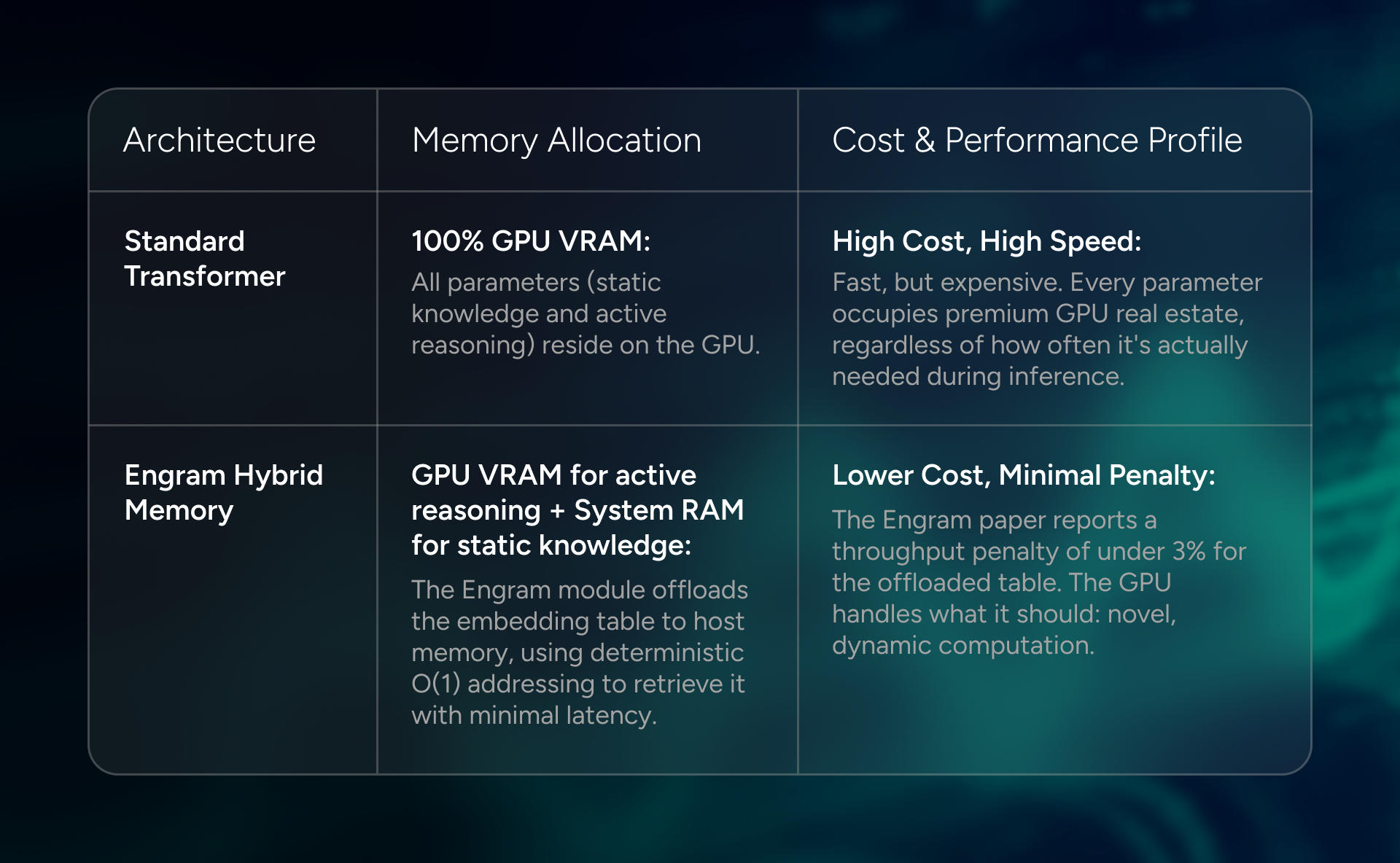
The practical implication is that a model with an Engram module can be significantly larger in terms of total knowledge capacity without a proportional increase in GPU memory requirements. That's what makes the rumored 1T+ parameter count for V4 plausible without requiring a warehouse of H100s.
2. What V4 Could Be (Speculation)
This is where we connect the architecture to the capabilities. While this section is conjecture, it’s grounded in what the new architecture enables and what the competitive landscape demands.
A Serious Agentic Upgrade
The coding benchmark race is maturing as a differentiator. Every frontier model now scores well on SWE-Bench. The new frontier is agentic capability: can a model plan, use tools, and execute complex, multi-step tasks without hand-holding? Claude Opus 4.6 launched almost entirely on its agentic improvements. Kimi K2.5 introduced a 100-agent swarm architecture that cuts complex task execution time by 4.5x. Engram's architecture is well-positioned for this. By offloading routine, high-frequency patterns to the fast-retrieval memory bank, the active compute layers are freed up for the hard parts: planning, tool selection, and error recovery. This is the architectural path from a model that can write code to a model that can build software.
The Economics of Autonomous Agents: A TCO Projection
The shift to agentic workflows is a major economic challenge. A 24/7 autonomous agent isn't a chatbot you query occasionally because it's a continuous inference workload. Run the math on current frontier model pricing and the numbers get uncomfortable for your CFO.
The table below uses a conservative baseline: a single agent processing 1 million tokens per day at a 1:2 input-to-output ratio.
- GPT-5.2 is priced at $1.75/M input and $14.00/M output.
- The DeepSeek V4 projection is based on V3.2's published pricing of $0.28/M input and $0.42/M output, with a conservative assumption that V4's architectural efficiency gains hold the price floor.
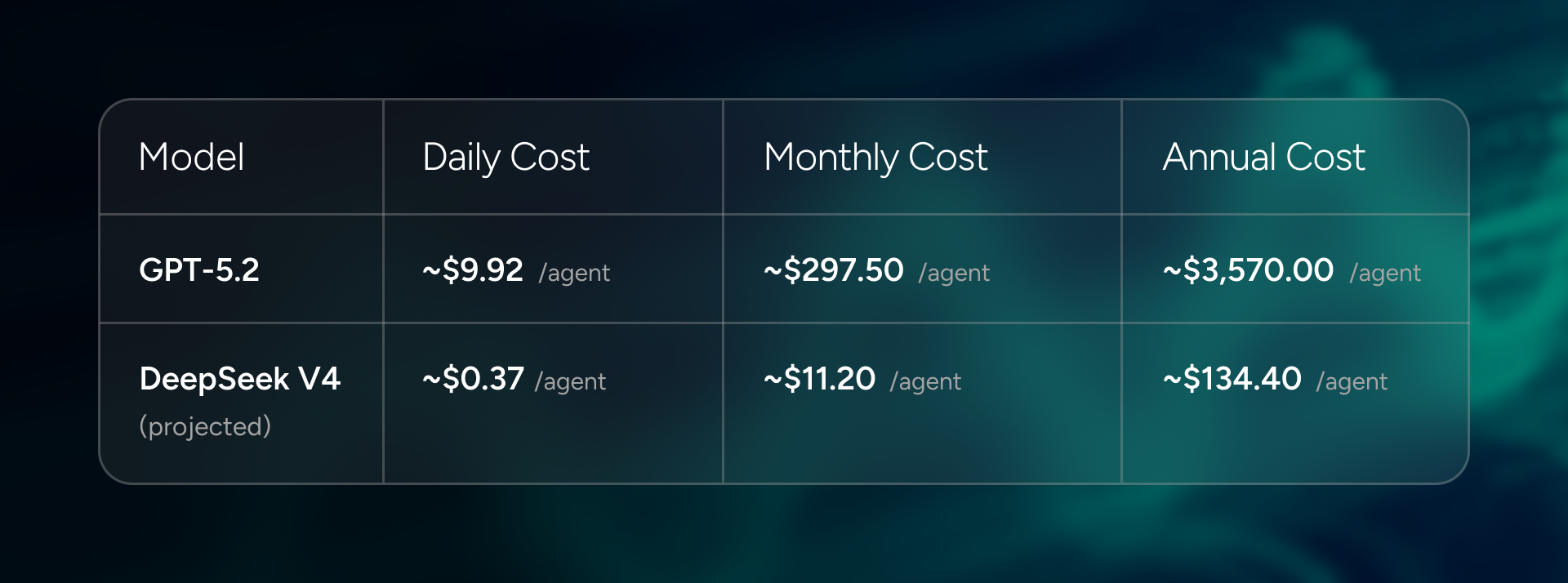
That's a ~96.2% reduction in the per-agent inference bill. At that price point, the question stops being "can we afford to run an autonomous agent?" and starts being "how many can we run?" The architecture doesn't just make agents smarter but also makes them economically viable at scale. Most businesses will treat that as a completely different conversation.
Truly Native Multimodality
The trend in early 2026 is vision baked into the base model, not bolted on. Engram’s memory hierarchy is perfect for this. A pre-computed library of visual N-grams could be offloaded to the same host DRAM tier used for linguistic patterns, allowing the model to reason about images and text in a deeply integrated way. The recent V4 Lite leak, showing strong SVG generation, points in this direction.
A Family of Models, Not a Single Flagship
The V4 Lite leak also suggests a tiered strategy, similar to Anthropic’s Opus/Sonnet/Haiku. Engram’s design makes this highly practical. A smaller model can use a proportionally smaller embedding table while still benefiting from the same knowledge-computation separation. This means we could see a V4-Lite that runs on consumer hardware, a V4-Pro for enterprise, and a V4-Ultra at the frontier.
3. The Big Picture: Competition, Hardware, and The Full Stack
No model is released in a vacuum. Three contextual points are worth noting.
First, the competitive context. On February 23, Anthropic published a report accusing DeepSeek of running an "industrial-scale" campaign to extract capabilities from Claude: allegedly, over 150,000 exchanges, using fraudulent accounts and proxy services. The accusations are serious and contested. But the technical detail worth noting is what was extracted: chain-of-thought reasoning traces and rubric-based grading data used to build a reward model. DeepSeek was not just prompting Claude; they were running a sophisticated data generation pipeline to shape their own model's behavior. Whether or not the accusations hold up legally, the sophistication of the operation is a signal about how aggressively the frontier labs are moving.
Second, the hardware frontier is moving. Reuters reported that DeepSeek may have trained V4 on NVIDIA’s next-gen Blackwell GPUs. For builders, this is a double-edged sword. It means V4 is likely optimized for hardware that will eventually become the standard, but it also means that its peak performance may not be reproducible on current-gen Hopper infrastructure.
Finally, a note on the full stack. V4 is genuinely exciting. The architecture is real, the papers are published, and the potential is significant. But every major model release in the past year has followed the same pattern: the teams that extract the most value are not the ones who are fastest to download the weights. They're the ones who had the serving infrastructure, orchestration workflows, and data pipelines ready before the model dropped. V4's architecture, with its multi-tiered memory hierarchy, dual K-cache, and complex MoE routing, is more demanding of the surrounding stack than any previous DeepSeek release. The model will be exciting. The question is whether your stack is ready to use it.
At GMI Cloud, we run production inference on sparse architectures across our NVIDIA reference clusters. Based on what we’ve seen, the prefill-decode disaggregation overhead for long-context DSA is the first thing that breaks naive serving implementations. If you're building for the full stack and want to compare notes before V4 drops, we're easy to find on Discord, or you can reach out to us.
Colin Mo
Head of Content
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
