GMI Cloud Achieves 4x LLM Performance Boost with Tensormesh
We achieved 4x LLM performance using prefix caching backed by SSD-augmented KVCache
December 30, 2025

This is a joint technical benchmark between the GMI Cloud and Tensormesh engineering teams.
This report documents a joint technical benchmark between the GMI Cloud and Tensormesh engineering teams, evaluating the real-world impact of SSD-augmented KV cache optimization on LLM inference performance. Using a realistic synthetic dataset modeled on live production traffic, the teams tested prefix caching under actual conversational load conditions - multi-turn dialogues, non-sequential request patterns, and mixed prompt lengths - to measure how cache footprint size affects Time to First Token, latency variance, and GPU efficiency.
What you'll learn in this benchmark report:
● How SSD-augmented KV caching reduced Time to First Token by 4x compared to standard vLLM
● Why RAM-only caching delivered only 1.4x improvement and what changed with SSD storage
● How prefix cache hit rate jumped from 3% to over 50% on real conversational workloads
● What synthetic dataset methodology GMI used to simulate production traffic without exposing customer data
● Why large KV cache footprints are the dominant factor in LLM serving performance
Key Results and Impact
What performance gains did GMI Cloud achieve with SSD-augmented KV caching?
SSD-backed prefix caching delivered a 4x reduction in Time to First Token, raised cache hit rates from 3% to over 50%, smoothed latency variance on long prompts, and reduced redundant GPU recomputation - all on the same hardware with no additional cost.
- 4x reduction in Time to First Token (TTFT) when prefix caching is backed by SSD-augmented KVCache.
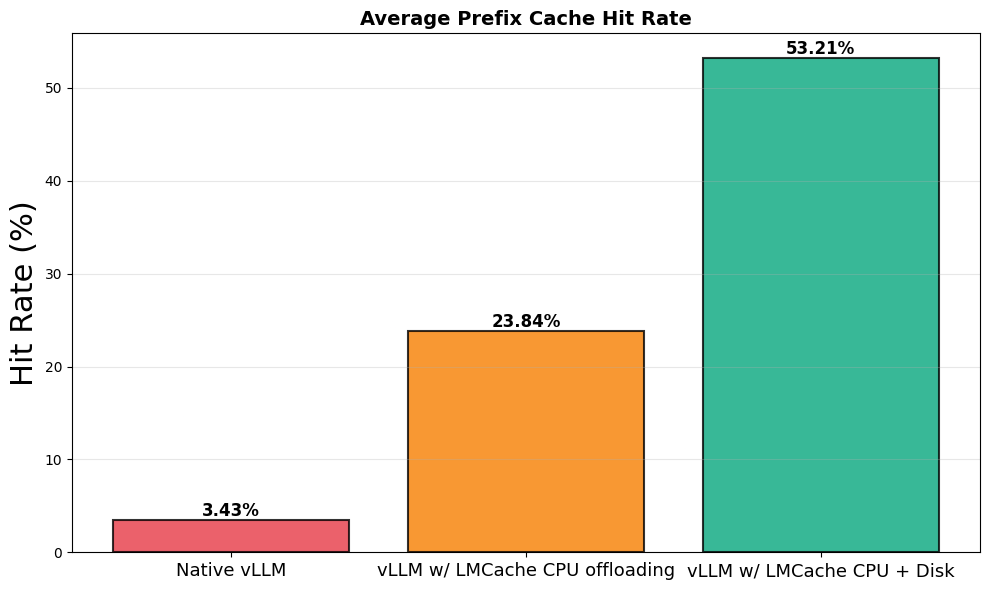
- Prefix cache hit rate increased from 3% to over 50%, demonstrating that real conversational workloads contain substantial reusable computation.
- Significant smoothing of latency variance, particularly on long prompts, improving user-facing responsiveness for multi-turn agents and AI companions.
- Reduction in redundant KV recomputation, lowering GPU cycles per request and enabling higher effective throughput on the same hardware.
These outcomes indicate that scalable KV cache optimization is a practical and high-impact optimization for real-world LLM serving, especially for AI companion, tutoring, or agentic workloads where conversational histories and context windows accumulate rapidly.
How We Arrived Here: Methodology and Technical Details
How did GMI Cloud design the benchmark to reflect real production traffic?
GMI built a synthetic dataset based on observed customer prompt patterns, covering multi-turn conversations up to 10+ turns, non-sequential request arrival, diverse linguistic styles, and mixed prompt lengths - replicating real-world inference load without using customer data.
1. Dataset Construction for Realistic Multi-Turn Traffic
Due to the critical importance of customer data privacy, real production data was strictly off-limits. GMI's solution was to analyze customer prompt characteristics to produce a highly realistic synthetic dataset that faithfully replicated the traffic patterns observed on our live inferencing service.
It included:
- Multi-Turn Conversations: A dataset specifically designed to reflect AI companion scenarios, with dialogs ranging from 1 to 10+ turns.
- Real-World Interleaving Traffic: Requests from the same conversation were not forced to arrive sequentially, accurately simulating the unpredictable, non-sequential arrival order of real-world user traffic.
- Realistic Linguistic Diversity: The prompts exhibited diverse emotional tones, casual chat, personal questions, follow-ups, and corrections.
- Load Testing Design: The test mixed short, contextual queries with longer prompts that included extensive history, providing a true measure of performance under load.
This dataset ensured that KV cache reusing was evaluated under realistic, non-ideal traffic patterns.
2. Experimental Setup
Two inference stacks were deployed:
- Baseline vLLM with standard KVCache behavior.
- LMCache-enabled vLLM with Tensormesh's caching layer integrated.
We evaluated two cache configurations:
- RAM-only KVCache, representing a constrained cache footprint.
- Hybrid RAM + high-capacity SSD, enabling a much larger KV cache datastore.
Both systems were driven with the same synthetic dataset under identical load conditions.
3. Detailed Findings
What did the benchmark find about RAM-only versus SSD-augmented KV caching?
RAM-only caching produced only a 1.4x TTFT improvement due to rapid cache eviction. Adding high-capacity SSDs expanded the cache footprint enough to sustain prefix reuse, delivering the full 4x improvement and significantly more consistent latency across prompt lengths.
Quick Summary:
RAM-Only KVCache
- Delivered only a ~1.4x TTFT improvement.
- Cache size limitations led to rapid eviction and limited impact on multi-turn workloads.
SSD-Augmented KVCache
- Produced a 4x improvement in TTFT.
- Cache hit rate climbed toward 50 percent as the cache warmed.
- Latency variance across different prompt lengths was significantly reduced.
Interpretation: Cache footprint size is the dominant factor in determining the effectiveness of KV caching for real workloads.
The game-changer came with the integration of secondary storage in the form of large SSD drives. With the vast increase in available KVCache space, the results were drastic:
- Time To First Token (TTFT): The TTFT—a critical measure of user responsiveness—improved by a staggering 4x compared to the original stack. This speedup is transformative for user experience.
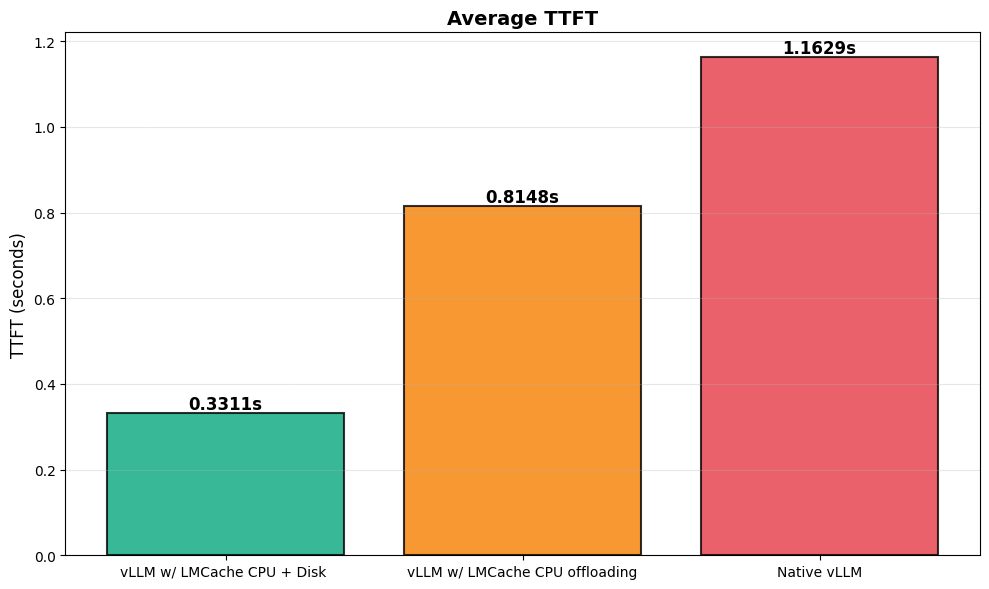
- Prefix KV Cache Hit Rate: The reason for this massive leap is clear. The cache hit rate for KV—the prompt text—soared from nearly zero to almost 50% over the duration of the test. Hitting the cache half the time drastically cuts down on redundant computation.
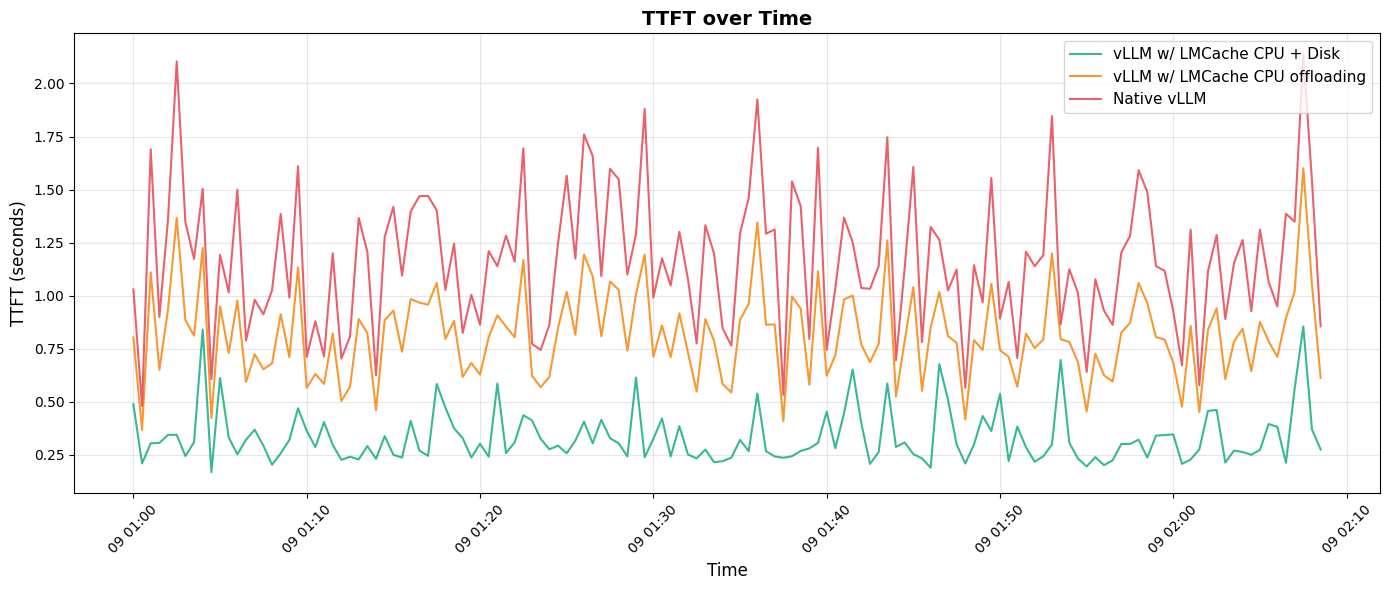
- Smoother Performance: While TTFT naturally varies with prompt length, the caching mechanism successfully smoothed out this variation once the cache was loaded, providing a more consistent and reliable latency profile for the end-user.
4. Architectural Implications for LLM Serving
What are the business implications of SSD-backed KV caching for LLM infrastructure?
The setup lowers GPU utilization per request, increases cluster throughput on identical hardware, stabilizes latency for agent loops and AI companions, and scales without expensive RAM upgrades - delivering pure performance gain at no extra infrastructure cost.
These performance gains translate directly into significant, measurable business advantages once implemented across GMI’s infrastructure:
- Better compute efficiency: Less recomputation of prefix KV lowers GPU utilization per request.
- More predictable latency: Essential for agent loops, AI companions, and interactive systems.
- Improved cluster throughput: Greater QPS on identical hardware.
- Scalable optimization: SSD-backed caching makes deployment feasible without expensive RAM scaling.
As a whole, the GMI Cloud engineers noted this no-extra cost setup resulted in “Just pure performance gain without extra cost.” We fully expect other cloud providers to gain similar efficiencies with this same solution.
5. Summary for Developers and Researchers
- Real-world conversational traffic contains ample repetition for effective caching.
- Large cache footprints (RAM+SSD) are essential for unlocking meaningful gains.
- LMCache can be deployed within existing vLLM stacks with low integration friction.
- These optimizations are directly relevant for anyone building agentic loops, AI companions, or high-volume LLM-based products.
Tensormesh Overview
Tensormesh is an AI infrastructure company pioneering caching-accelerated inference optimization for enterprise AI. Their technology is capable of reducing redundant computation during inference, cutting GPU costs and latency by up to 10x, all while ensuring enterprises retain full control of their infrastructure and data. They recently announced their public launch and a successful $4.5 million seed funding round led by Laude Ventures.
GMI Cloud Overview
GMI Cloud is a company that provides world-class GPU cloud infrastructure and model inferencing services tailored for AI and machine learning workloads. As an NVIDIA Cloud Partner, GMI offers high-performance GPU clusters, including access to cutting-edge hardware like NVIDIA Blackwell and H100 & H200 GPUs. Headquartered in Mountain View, California, GMI's mission is to make AI development and scaling accessible and efficient for its global customer base.
Frequently Asked Questions
1. What performance improvements were achieved in the GMI Cloud and Tensormesh benchmark?
The benchmark demonstrated a 4× reduction in Time to First Token (TTFT) when prefix caching was backed by an SSD-augmented KV cache. It also significantly reduced latency variance, increased effective throughput, and lowered redundant GPU computation for real-world conversational workloads.
2. Why is prefix caching especially effective for real conversational AI workloads?
The benchmark showed that real multi-turn conversations contain substantial reusable computation. With SSD-backed KV caching, the prefix cache hit rate increased from about 3% to over 50%, proving that conversational histories and long context windows can be efficiently reused instead of recomputed.
3. What role did SSD-augmented KV cache play compared to RAM-only caching?
RAM-only KV cache delivered limited gains (around 1.4× TTFT improvement) due to frequent eviction caused by small cache size. Adding SSDs dramatically expanded the cache footprint, enabling sustained reuse of prefixes and unlocking the full 4× TTFT improvement with smoother, more predictable latency.
4. How was the benchmark designed to reflect real production traffic?
Instead of using customer data, GMI Cloud generated a realistic synthetic dataset based on observed prompt patterns. It included multi-turn conversations, non-sequential request arrival, diverse linguistic styles, and a mix of short and long prompts to accurately simulate real-world inference load.
5. What are the practical implications for developers and AI platforms?
The results show that large KV cache footprints are essential for scalable LLM serving. SSD-backed prefix caching improves compute efficiency, increases cluster throughput, stabilizes latency for agentic and companion applications, and can be deployed within existing vLLM stacks with minimal integration effort.
Colin Mo
Head of Content
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
