The AI-Native inference cloud
GMI Cloud is an AI-native infrastructure platform built for production AI inference. From serverless APIs to dedicated GPU clusters, we deliver predictable performance, scalable capacity, and cost-efficient execution on NVIDIA GPU platforms.

The GMI Cloud Full-Stack Platform
GMI Cloud delivers a vertically integrated AI infrastructure stack, from inference APIs and orchestration to compute and hardware.
Inference Layer
Production-grade AI inference optimized for low latency and predictable cost.

Orchestration Layer
Kubernetes-based platform with automated scaling, load balancing, and multi-region deployment
Compute Layer
Dedicated and on-demand NVIDIA GPU compute for scalable AI workloads.
Hardware Layer
NVIDIA H100, H200, Blackwell and next-gen GPU platforms in owned data centers.
Why Our Full-Stack Infrastructure Matters for Production Inference
Production inference workloads demand infrastructure that delivers consistent performance, predictable costs, and operational reliability.
GPUs Deployed
30,000+
Platform Availability
99.99%
Strategic Alliance
NVIDIA Reference Architecture
Cloud Platform Partner
AI team customers
300+
GPU Efficiency Gains
Up to 3.7x

Supporting Teams Running AI in Production
GMI Cloud supports three production AI segments with tailored NVIDIA GPU infrastructure and deployment models.
AI Developers and Engineers
Access production-ready AI inference via intuitive APIs and SDKs. Build, test, and deploy on scalable NVIDIA GPU infrastructure with full documentation and developer tooling.
Enterprise AI Teams
Deploy mission-critical AI systems on dedicated NVIDIA GPU infrastructure with SLA-backed performance, compliance certifications (SOC 2, ISO 27001), and enterprise support.
The GMI Cloud Ecosystem
Global GPU regions across the US, Europe, and Asia-Pacific, built for production AI deployment.
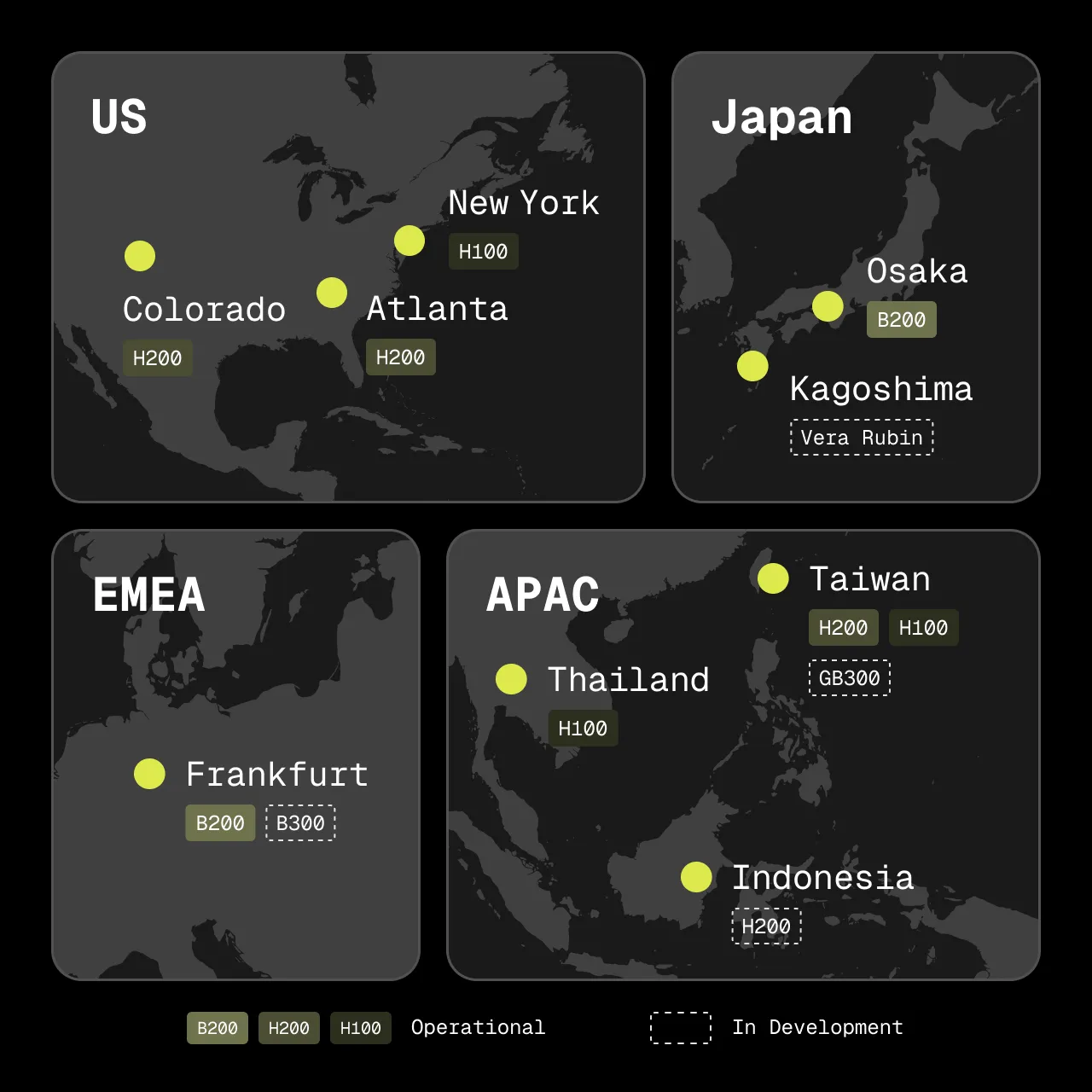
GLOBAL_REACH
GPU regions across NA, Europe, and Asia-Pacific
PERFORMANCE
< 200 ms avg cross-region latency
PARTNERSHIP
NVIDIA Reference Architecture Provider
SUPPORT
24/7 operations & global support
INTEGRATION
Leading model providers & MLOps
Trusted by AI Builders Worldwide
Hundreds of companies trust GMI Cloud for production AI inference and GPU infrastructure at scale.
Build on the AI-Native Inference Cloud
Whether you're prototyping your first AI model or scaling to millions of daily inference requests, GMI Cloud's full-stack infrastructure provides the performance, reliability, and cost efficiency to power your production inference workloads. Join hundreds of teams building the future of AI on infrastructure you can trust.