Affordable LLM Inference Services with Fast Response Times: The 2026 Engineering Guide
Achieving affordable LLM inference with sub-100ms latency is strictly a function of maximizing memory bandwidth utilization. By deploying memory-bound models like Llama 3 70B (FP8) on GMI Cloud’s Bare Metal H200 Infrastructure , engineering teams utilize 4.8 TB/s of bandwidth and
February 21, 2026
In the rapidly evolving landscape of Generative AI, the economic viability of a product hinges on the ratio of inference throughput to infrastructure cost. For CTOs, AI architects, and MLOps engineers, the challenge is to scale memory-bound workloads without incurring the latency penalties and unpredictable jitter of virtualized environments.
The market is saturated with GPU options, but low hourly rates often mask technical inefficiencies such as network contention, hypervisor steal time, and limited memory bandwidth. True affordability in LLM inference services is achieved by minimizing Time Per Output Token (TPOT) through superior hardware specifications (HBM3e) and a zero-virtualization architecture. This guide provides a comprehensive technical analysis of hardware selection (H100 vs H200), infrastructure types, kernel-level optimizations, and scaling strategies using platforms like GMI Cloud.
The Engineering Economics of Inference
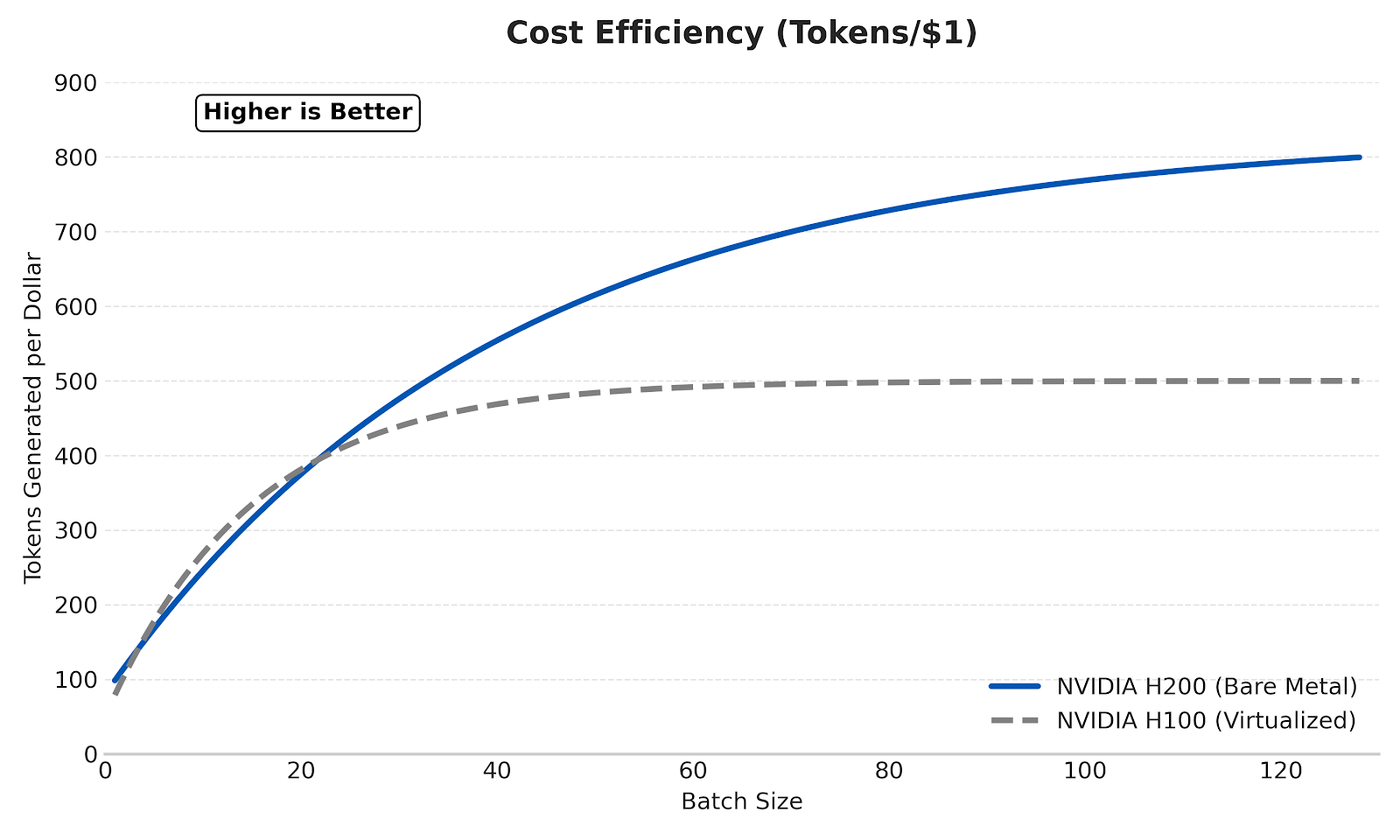
To optimize costs effectively, it is necessary to deconstruct the cost model of Large Language Model (LLM) inference. The total cost of ownership (TCO) for inference is not merely the hourly rental rate of the GPU, but the cost to generate a specific volume of tokens within a specific latency Service Level Agreement (SLA).
The Cost Per Token Formula
Engineers should evaluate providers based on the following efficiency formula:
Cost_Per_1M_Tokens = (Hourly_Instance_Cost) / (Tokens_Per_Second * 3600) * 1,000,000
Where Tokens_Per_Second is derived from the total throughput of the system. This metric is heavily influenced by two factors:
- Memory Bandwidth Utilization (MBU): The percentage of theoretical memory bandwidth effectively used during the decoding phase.
- Batch Size: The number of concurrent requests processed. Larger batch sizes amortize the cost of reading model weights from High Bandwidth Memory (HBM).
Key Insight: A more expensive GPU (e.g., NVIDIA H200) often yields a lower Cost_Per_1M_Tokens than a cheaper GPU (e.g., NVIDIA A100) because its higher memory bandwidth (4.8 TB/s vs 2.0 TB/s) supports significantly higher throughput and larger batch sizes.
Hardware Specifications: H100, H200, and Blackwell B200
For inference workloads, particularly for models exceeding 70 billion parameters, memory bandwidth is the primary bottleneck. The migration from HBM3 to HBM3e in the NVIDIA H200 offers a 1.4x bandwidth increase over the H100, directly translating to throughput gains for large batch sizes.
The following table outlines the detailed technical specifications for the current and next-generation data center GPUs available on GMI Cloud.
Table 1: NVIDIA Data Center GPU Specifications
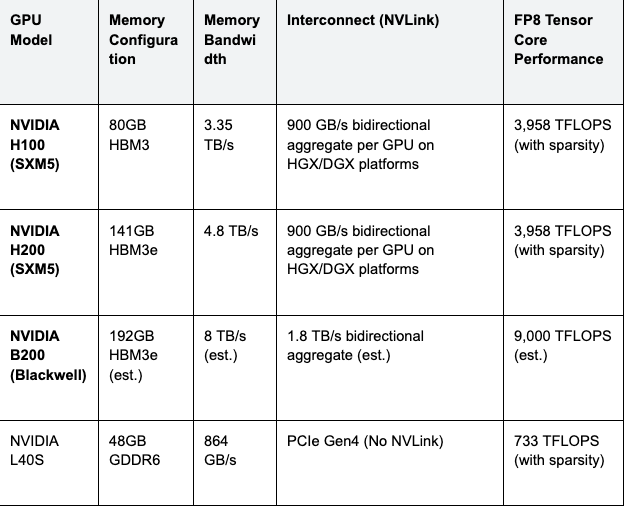
According to NVIDIA benchmarks, the H200 delivers up to 1.9x inference performance compared to the H100 when running Llama 2 70B with a batch size of 64, utilizing TensorRT-LLM and FP8 precision. This performance delta makes the H200 the preferred choice for GMI Cloud H200 Instances targeting production-grade SLAs.
Infrastructure Comparison: Bare Metal vs. Virtualized Cloud
When selecting an inference provider, the virtualization layer is a critical source of latency (TTFT) and throughput degradation. Most cloud providers utilize a Hypervisor (e.g., KVM, Xen) to virtualize physical resources. While this enables multi-tenancy, it introduces overhead.
GMI Cloud offers Bare Metal instances where the tenant has full root access to the physical server. This architecture contrasts sharply with virtualized offerings from competitors.
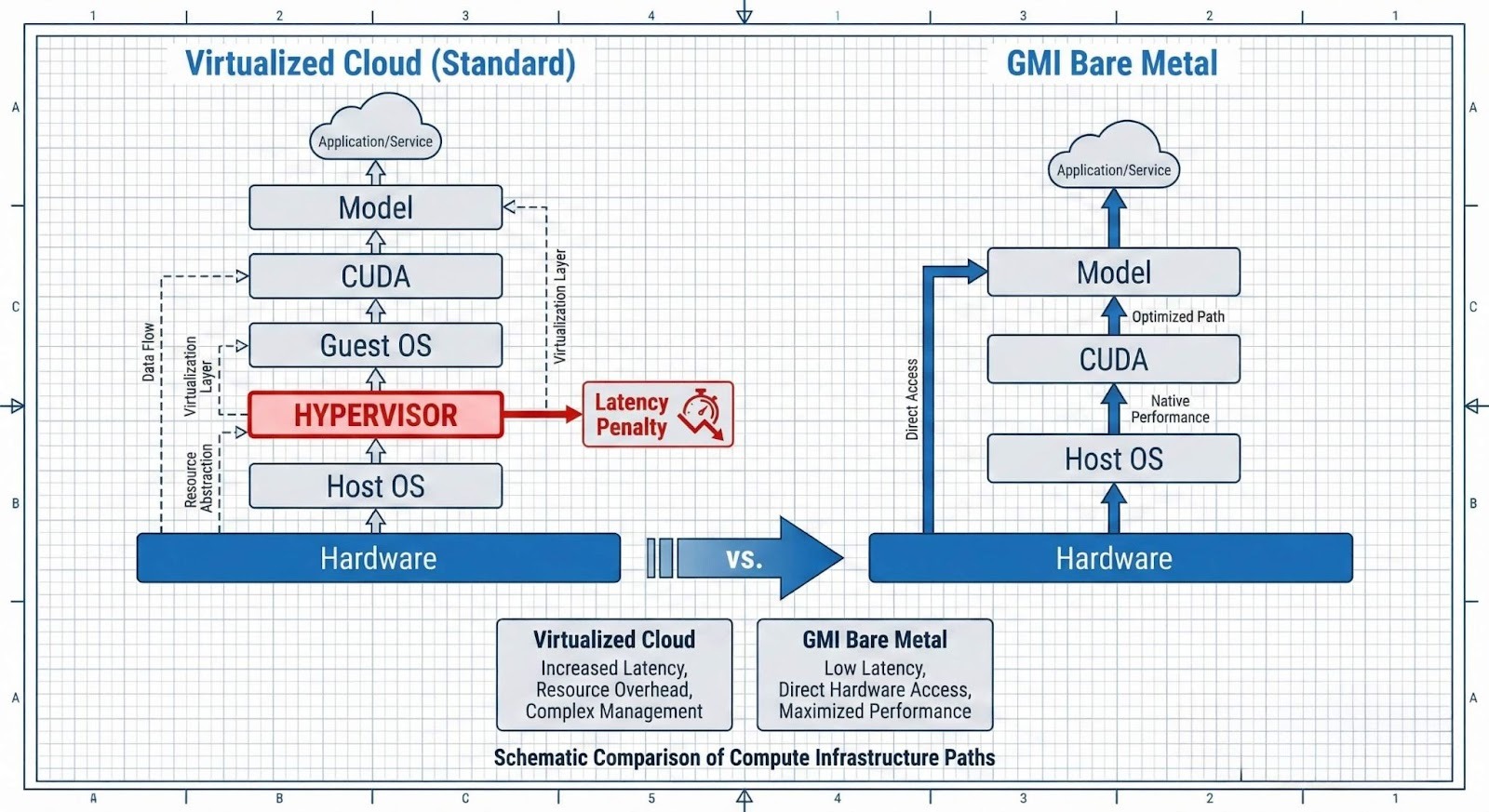
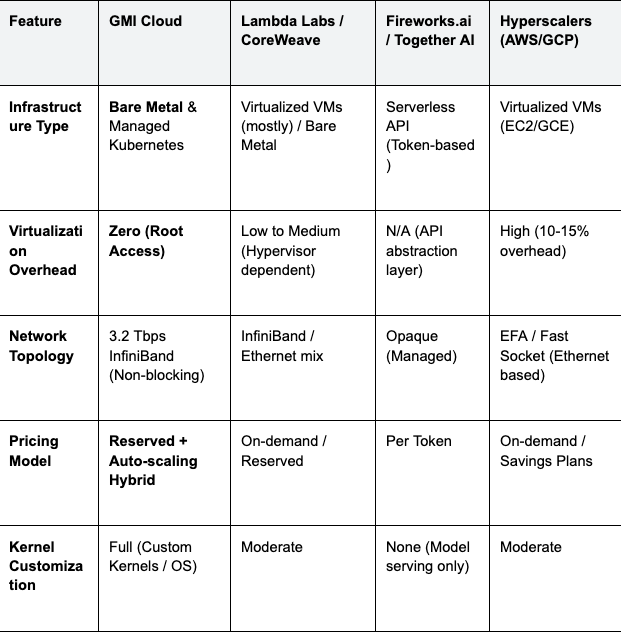
Table 2: Competitor Analysis for AI Inference
The Impact of Virtualization on Latency
In a virtualized environment, "Hypervisor Steal Time" occurs when the hypervisor allocates CPU cycles to other tenants on the same physical host. For LLM inference, specifically the CPU-intensive pre-fill phase, this results in:
- Non-deterministic P99 Latency: Unpredictable spikes in Time to First Token (TTFT).
- Cache Contention: L3 cache pollution from neighboring VMs reducing memory access efficiency.
- Interrupt Coalescing: Network packet processing delays due to virtualized I/O.
For Bare Metal deployments on GMI Cloud Cluster Engine, the absence of a hypervisor allows for direct PCIe passthrough and SR-IOV configuration. This ensures that syscall latency remains deterministic.
Technical Implementation Strategies
Achieving fast response times requires not just the right hardware, but optimal software configuration. Below are standard engineering patterns for deploying high-throughput inference on GMI Cloud.
Optimizing vLLM for H200
When deploying models like Llama 3 or DeepSeek V3 on H200 instances, configuring the `vLLM` engine to maximize GPU memory utilization is critical. We recommend the following configuration to utilize the 141GB HBM3e effectively:
# Example vLLM deployment command for Llama-3-70B on 1x H200
python3 -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-70B-Instruct \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--max-model-len 8192 \
--enforce-eager \
--quantization fp8
Configuration Notes:
- --gpu-memory-utilization 0.95: On bare metal, you can safely push memory utilization higher than on VMs, as there is no virtualization overhead claiming VRAM.
- --quantization fp8: Leveraging the H200's native FP8 Tensor Cores doubles the arithmetic throughput and reduces memory bandwidth pressure.
- --enforce-eager: For CUDA graph compatibility testing, sometimes required for experimental builds, though standard CUDA graphs are recommended for production latency stability.
Advanced Kernel Optimizations
Beyond basic configuration, leveraging advanced kernel features can further reduce latency. Bare metal access allows for the compilation of custom CUDA kernels without the restrictions often found in managed container environments.
FlashAttention-3 and PagedAttention
Standard attention mechanisms scale quadratically with sequence length. FlashAttention-3 optimizes memory access patterns to reduce HBM reads/writes. On GMI Cloud’s H200s, enabling FlashAttention is mandatory for long-context workloads (e.g., 128k context windows).
PagedAttention, utilized by vLLM, manages KV-cache memory in non-contiguous blocks, similar to virtual memory in operating systems. This significantly reduces memory fragmentation. In virtualized environments, the translation of these memory pages can incur minor overheads; on bare metal, the mapping is direct and efficient.
CUDA Graphs for CPU Overhead Reduction
For small batch sizes (e.g., batch=1 for real-time chat), the CPU overhead of launching GPU kernels can exceed the actual GPU execution time. CUDA Graphs capture a sequence of kernel launches and replay them as a single operation. GMI Cloud’s bare metal environment supports aggressive CUDA Graph capture, reducing CPU-side launch latency by up to 10-20 microseconds per step.
Multi-Node Inference with InfiniBand
For models that exceed the capacity of a single node (e.g., DeepSeek 671B), low-latency inter-node communication is required. GMI Cloud provides 3.2 Tbps InfiniBand networking.
Ensure that your NCCL (NVIDIA Collective Communications Library) topology is aware of the physical network interface cards (NICs). On GMI Cloud Bare Metal, you can inspect the topology directly:
# Check InfiniBand Link Status
ibstat
# Verify NVIDIA Topology
nvidia-smi topo -m
Observability and Monitoring
To maintain "affordable" inference, one must vigorously monitor resource utilization to right-size the infrastructure. GMI Cloud supports full export of GPU metrics via DCGM (Data Center GPU Manager).
Key Metrics to Track
- SM Occupancy: Indicates how fully the Streaming Multiprocessors are utilized. Low occupancy with high memory bandwidth usage confirms a memory-bound workload.
- PCIe/NVLink Throughput: Critical for multi-GPU pipeline parallelism. Saturation here indicates a need for optimized tensor parallelism strategies.
- KV-Cache Usage: Tracks the percentage of reserved memory used for context. Consistent 100% usage triggers eviction and re-computation, destroying latency performance.
# Example Prometheus Scraper Config for DCGM
scrape_configs:
- job_name: 'gpu-metrics'
static_configs:
- targets: ['localhost:9400']
Pricing Strategies: On-Demand, Reserved, and Hybrid Scaling
GMI Cloud offers a modular approach to pricing that suits different stages of the AI lifecycle. A purely on-demand strategy is often the most expensive way to run production inference.
- On-Demand (Prototyping): Ideal for development and testing. You pay for what you use, with no long-term commitment. Check our Pricing Page for current rates on H100 and H200 instances.
- Reserved Instances (Production Baseline): For steady-state traffic, reserving GPUs yields significant discounts. This is the foundation of affordable inference.
- Serverless/Auto-Scaling (Spiky Traffic): The GMI Inference Engine allows for automatic scaling. You can maintain a small cluster of reserved instances for baseline traffic and burst into on-demand instances during peak hours.
Future-Proofing with NVIDIA Blackwell
The next leap in inference efficiency comes with the NVIDIA Blackwell architecture. The GB200 NVL72 system connects 72 GPUs via a 1.8 TB/s NVLink switch (est.), effectively functioning as a single GPU with 13.5 TB of HBM3e memory (est.).
NVIDIA projects a 30x performance increase for real-time LLM inference on trillion-parameter models using the GB200 compared to the H100 (Source: NVIDIA GTC 2024 Keynote). GMI Cloud is currently accepting pre-orders for these systems via the GB200 Product Page to support the next generation of mixture-of-experts (MoE) models.
FAQ: Infrastructure Strategy
Q: Can I use consumer GPUs (RTX 4090) on GMI Cloud for lower costs?
No. Using GeForce cards in data centers violates the NVIDIA GeForce EULA. GMI Cloud exclusively provides enterprise-grade GPUs (H100, H200, L40S) to ensure compliance, ECC memory reliability, and 24/7 stability.
Q: Does the H200 provide a cost benefit over the H100 despite the higher hourly price?
Yes. For large models (e.g., Llama 3 70B) running at high batch sizes, the H200's 141GB memory and 4.8 TB/s bandwidth enable higher throughput. If the throughput increase (e.g., >1.4x) exceeds the price premium, the effective cost per token decreases.
Q: Is Bare Metal necessary for all inference workloads?
No. For low-traffic or non-latency-sensitive batch processing, containerized services are sufficient. However, for real-time applications requiring predictable P99 latency below 100ms, Bare Metal eliminates the variable latency introduced by hypervisors.
Q: Does GMI Cloud support DeepSeek R1 deployment?
Yes. DeepSeek R1 is supported via our Model Library. We recommend using H200 instances for the 671B parameter version to fit the model weights and KV-cache efficiently across fewer GPUs.
What's next
- Explore the GPU Instances Documentation for detailed instance types.
- Read the Utopai Studios Case Study to see bare metal performance in production.
- Ready to test performance? Contact our Solutions Engineering Team for a Proof of Concept (POC).
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
