Best Place to Rent AI Compute for LLM Inference (2026 Engineering Guide)
February 21, 2026
In 2026, the AI compute market has bifurcated. On one side are the traditional Hyperscalers (AWS, Google Cloud, Azure), offering vast but often virtualized and expensive ecosystems. On the other are the AI-Native "Neo-Clouds" (GMI Cloud, Lambda Labs, CoreWeave), offering specialized, high-performance bare metal hardware. For CTOs and AI architects, choosing the right platform is a high-stakes decision that impacts not just the infrastructure bill, but the fundamental viability of the AI product.
This guide provides a rigorous engineering framework for evaluating where to rent AI compute. We move beyond marketing claims to analyze the underlying hardware (H100 vs H200), network topology (InfiniBand vs Ethernet), and virtualization overheads that determine real-world inference performance.
The Evaluation Framework: Throughput per Dollar
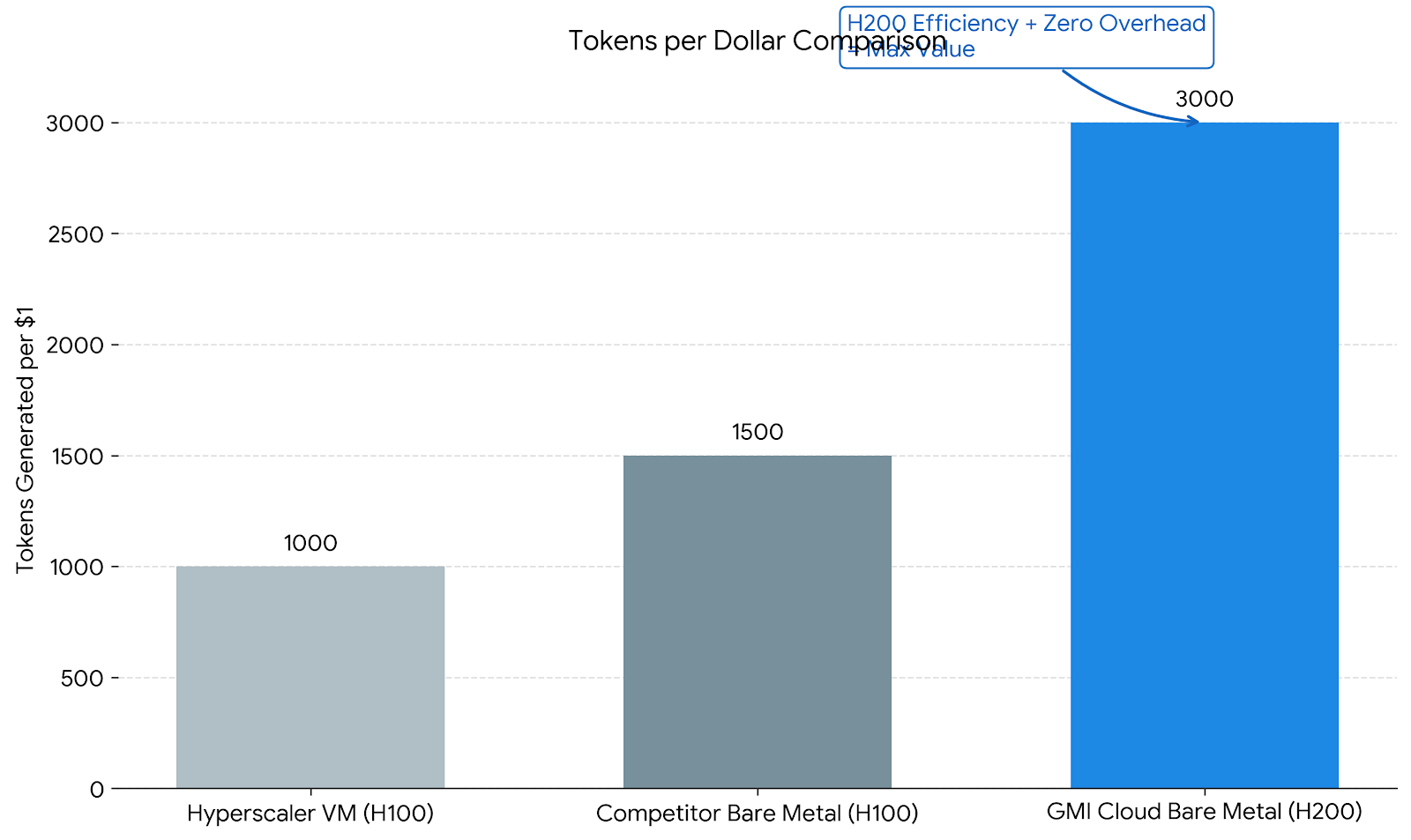
When renting compute for Large Language Models (LLMs), the primary metric is Throughput per Dollar. This is influenced by three technical factors:
- Memory Bandwidth Utilization: Can the platform saturate the 4.8 TB/s bandwidth of an H200? (Virtualization often throttles this).
- Interconnect Speed: For multi-GPU models (e.g., DeepSeek 671B), does the network support full 900 GB/s NVLink speeds and 3.2 Tbps InfiniBand?
- Availability & Start-up Time: Can you get the GPUs when you need them, and how long does it take to scale from 0 to 100 nodes?
Hardware Selection: Why H200 is the Inference Standard
Before choosing a provider, you must choose the hardware. For inference, memory is king. The NVIDIA H200 has replaced the H100 as the gold standard for renting.
Table 1: Hardware Specifications & Rental Impact
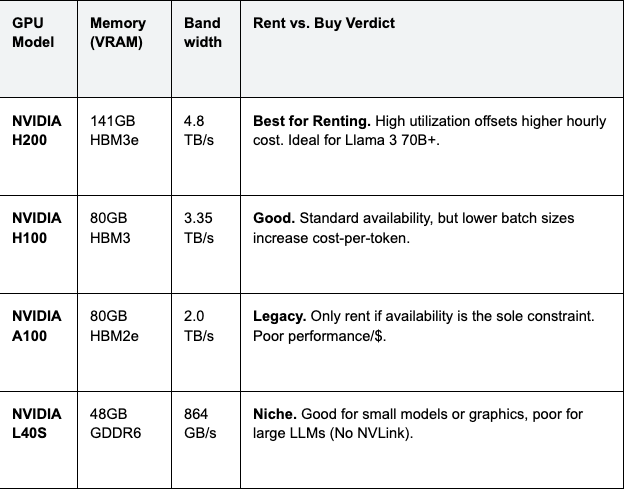
Cost Analysis: While an H200 instance might rent for $2.50/hr vs $2.00/hr for an H100, the H200's 1.4x memory bandwidth allows for significantly larger batch sizes. This increases throughput by ~50%, lowering the effective cost per million tokens by roughly 20%.
Provider Categories: Hyperscalers vs. Neo-Clouds
The market for renting compute is divided into two main categories. Understanding the architectural differences is key to making the right choice.
1. Neo-Clouds (GMI Cloud, Lambda, CoreWeave)
These providers focus exclusively on GPU compute. They typically offer Bare Metal instances, giving you direct access to the hardware without a hypervisor layer.
- Pros: Zero virtualization overhead (lower latency); Generally 30-50% cheaper than hyperscalers; Access to latest hardware (H200, Blackwell) faster.
- Cons: Fewer managed services (database, queues) compared to AWS/GCP (though GMI Cluster Engine mitigates this).
- Best For: Pure inference workloads, training clusters, and startups requiring maximum performance per dollar.
2. Hyperscalers (AWS, Google Cloud, Azure)
These general-purpose clouds offer GPUs as just one of hundreds of services.
- Pros: Deep integration with existing enterprise stacks (IAM, VPC, S3); Massive global compliance certifications.
- Cons: Significant virtualization overhead (Nitro/Titan cards); slower to adopt new GPU generations; high egress fees; complex pricing.
- Best For: Enterprises with strict regulatory requirements locking them into a single vendor ecosystem.
Deep Dive: The Bare Metal Advantage for Renting
When you rent a "GPU Instance" on a hyperscaler, you are usually renting a Virtual Machine (VM). The hypervisor managing this VM consumes CPU cycles and introduces jitter in memory access.
GMI Cloud provides Bare Metal instances. This means:
- No "Steal Time": Your application gets 100% of the CPU cycles.
- Direct PCIe Access: No translation layer for GPU commands, reducing kernel launch latency.
- Predictable Networking: Direct access to the InfiniBand NICs allows for efficient RDMA operations, critical for multi-node inference.
Benchmarking Before Renting
Never sign a rental contract without benchmarking. We recommend using GenAI-Perf (part of NVIDIA Triton Inference Server) to stress-test the provider's infrastructure.
Benchmarking Script Example
Run the following on a rented instance to determine the true throughput:
# Install NVIDIA GenAI-Perf
pip install genai-perf
# Run benchmark targeting a local vLLM server
genai-perf \
-m llama-3-70b \
--service-kind triton \
--backend tensorrtllm \
--num-prompts 100 \
--random-input-len 128 \
--random-output-len 128 \
--concurrency 10
If the Time to First Token (TTFT) variance (P99 - P50) is high (>50ms), it indicates a noisy neighbor issue common in virtualized environments. GMI Cloud's bare metal instances typically show near-zero variance.
Pricing Models: Optimization Strategy
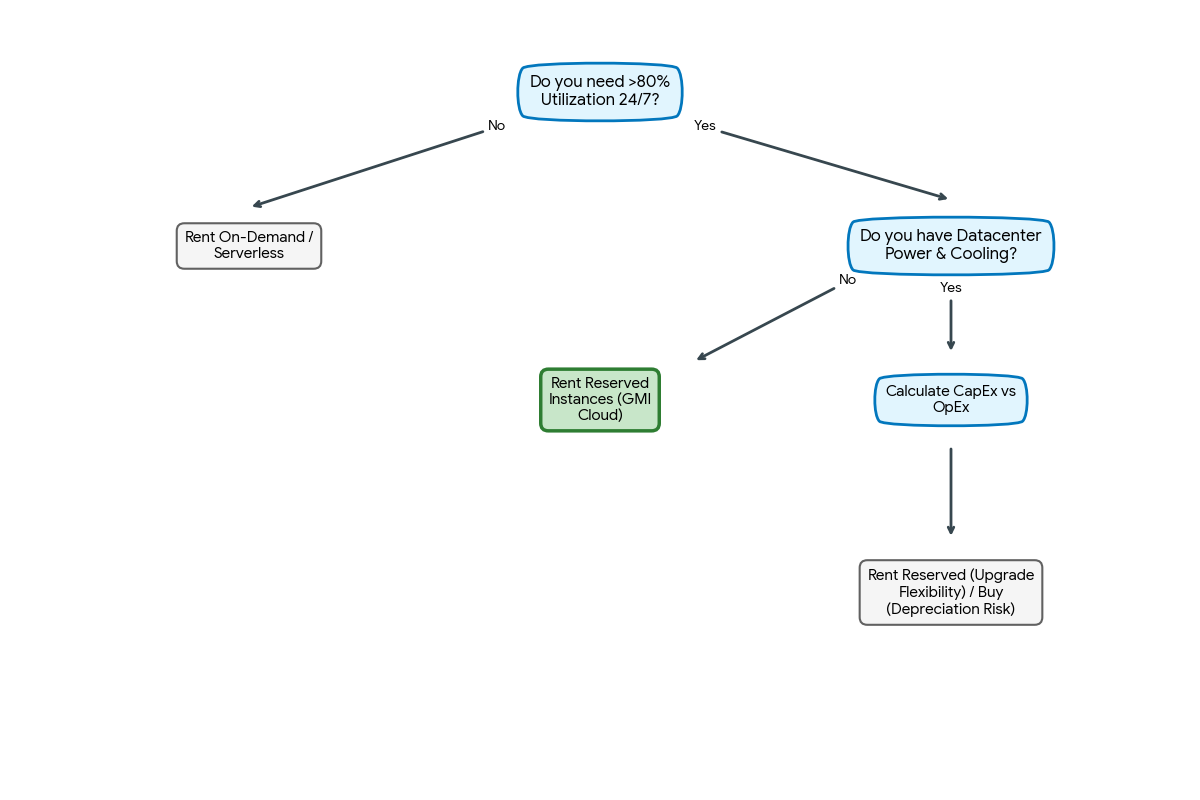
Finding the best place to rent also involves choosing the right payment model.
On-Demand (Spot)
Best for: Development, testing, and non-critical batch jobs.
GMI Cloud Strategy: Use our On-Demand Instances to benchmark your model and determine the exact number of GPUs needed to meet your latency SLA.
Reserved Instances (1-3 Years)
Best for: Production workloads with predictable baselines.
GMI Cloud Strategy: Once your baseline is established, converting to a Reserved contract typically yields a 30-50% discount compared to on-demand rates. This is the single most effective way to lower TCO.
Serverless Inference (Token-Based)
Best for: Spiky traffic where maintaining a dedicated cluster is wasteful.
GMI Cloud Strategy: Use the Inference Engine for auto-scaling capabilities. You pay a premium per compute unit, but save money by scaling to zero when idle.
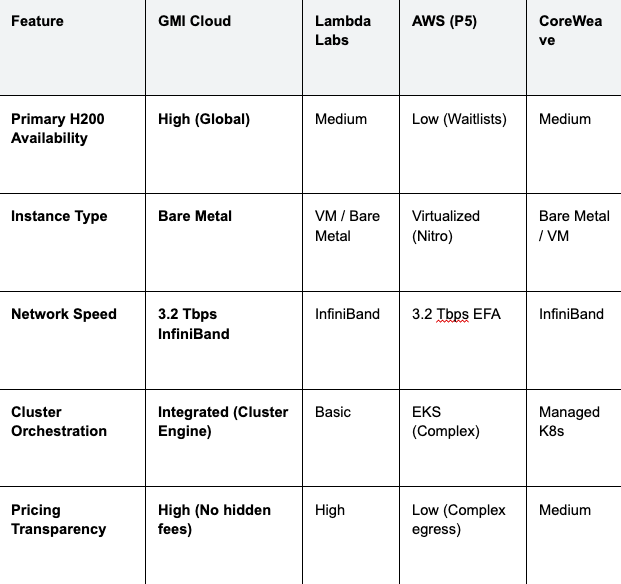
Comparison: GMI Cloud vs. Competitors
The following table provides a direct comparison of key rental parameters.
Table 2: Rental Provider Comparison (2026)
Operational Considerations: "Day 2" Concerns
Renting compute is the easy part; operating it is hard. The "best" place to rent provides tools to manage the lifecycle of your infrastructure.
Image Management
Does the provider offer pre-built images with the latest CUDA drivers, PyTorch versions, and FlashAttention libraries? GMI Cloud provides maintained "Deep Learning AMIs" that are updated weekly to ensure compatibility with the latest open-source models.
Observability
Can you see GPU-level metrics? GMI Cloud exposes full DCGM metrics (temperature, power, SM clock) via Prometheus endpoints, allowing you to integrate the rented cluster into your existing Grafana dashboards.
FAQ: Renting AI Compute
Q: Is it cheaper to build my own cluster on-premise than to rent?
Rarely for inference. Building an on-prem H200 cluster requires massive CapEx ($300k+ per node), 6-month lead times, and specialized data center power/cooling (10kW+ per rack). Renting from GMI Cloud converts this to OpEx and allows you to upgrade to Blackwell (B200) immediately upon release.
Q: How do I migrate my data to GMI Cloud?
Direct Connect or S3 Compatibility. We support high-speed data ingestion. Our storage solutions are S3-compatible, allowing you to use standard tools like `rclone` to move weights and datasets from AWS/GCP without code changes.
Q: What happens if a rented GPU fails?
Auto-Healing. Our Cluster Engine detects Xid errors and automatically cordons the failed node. If you are using our managed service, the workload is rescheduled to a hot spare instantly.
Q: Can I rent just one GPU?
Yes. While we specialize in large clusters, our On-Demand tier allows you to rent single H100 or H200 instances for testing and small-scale inference.
What's next
- Check real-time availability on the GPU Instances Page.
- Calculate your potential savings with our TCO Calculator.
- Contact Sales to discuss volume discounts for H200 clusters.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
