Best Platform to Run LLM Inference on NVIDIA H200 GPUs (2026 Engineering Guide)
February 21, 2026
The NVIDIA H200 is the definitive hardware standard for production LLM inference in 2026, offering 141GB of HBM3e memory and 4.8 TB/s bandwidth. However, the "best" platform to run it is not determined by hardware availability alone, but by the absence of virtualization overhead. GMI Cloud’s Bare Metal H200 Clusters outperform virtualized hyperscaler instances by delivering 100% of the raw memory bandwidth to the inference engine, reducing Time Per Output Token (TPOT) by up to 20% in memory-bound workloads.
As Generative AI models continue to scale in both parameter count (e.g., DeepSeek 671B) and context length (e.g., 128k to 1M tokens), the bottleneck for inference has decisively shifted from Compute (FLOPS) to Memory Bandwidth. The NVIDIA H200 Tensor Core GPU was engineered specifically to address this bottleneck, featuring the world's first HBM3e memory implementation.
For CTOs and AI Architects, selecting the right platform to deploy H200s is a critical strategic decision. A suboptimal platform choice—specifically one that introduces virtualization tax or network contention—can negate the hardware advantages of the H200. This guide provides a rigorous technical analysis of the leading H200 platforms, evaluating them on Bare Metal performance, Network Topology, and Total Cost of Ownership (TCO).
The Technical Case for H200 in Inference
Before evaluating platforms, it is essential to quantify why the H200 is superior to the H100 for inference workloads. The advantage lies entirely in the physics of data movement.
HBM3e: The Bandwidth Revolution

Large Language Models are autoregressive. Generating each token requires loading the entire model's weights from GPU memory into the compute cores. This makes the inference speed (TPOT) directly proportional to memory bandwidth.
- NVIDIA H100: 80GB HBM3 @ 3.35 TB/s.
- NVIDIA H200: 141GB HBM3e @ 4.8 TB/s.
Engineering Implication: The H200 provides a 1.4x increase in raw bandwidth. For a memory-bound model like Llama 3 70B, this translates almost linearly to a 1.4x increase in token generation speed, assuming the underlying platform does not throttle memory access.
Capacity and KV-Cache Scaling
The H200's 141GB capacity (vs 80GB on H100) allows for significantly larger Key-Value (KV) Caches. This enables two critical scaling vectors:
- Larger Batch Sizes: You can process more concurrent user requests on a single GPU.
- Longer Context Windows: You can serve RAG (Retrieval Augmented Generation) applications with 128k context without OOM (Out of Memory) errors.
Platform Evaluation Criteria
When renting H200 compute, we evaluate platforms based on three engineering criteria:
1. Virtualization Overhead (The "Tax")
Does the platform use a Hypervisor (like KVM or proprietary Nitro)? Hypervisors intercept memory pages and interrupts, adding latency to every GPU operation. For high-bandwidth devices like the H200, this overhead can reduce effective bandwidth by 10-15%.
2. Interconnect Topology
For multi-GPU inference (Tensor Parallelism), GPUs must communicate via NVLink and InfiniBand. Does the platform expose the full 3.2 Tbps InfiniBand bandwidth to the OS, or is it virtualized via an overlay network?
3. "Day 0" Availability
Can you actually get the GPUs? Many hyperscalers announce H200 availability but gate it behind massive commit contracts or waitlists.
Top Platforms Comparison
The following table compares the leading platforms offering NVIDIA H200 instances in 2026.
Table 1: H200 Platform Technical Comparison
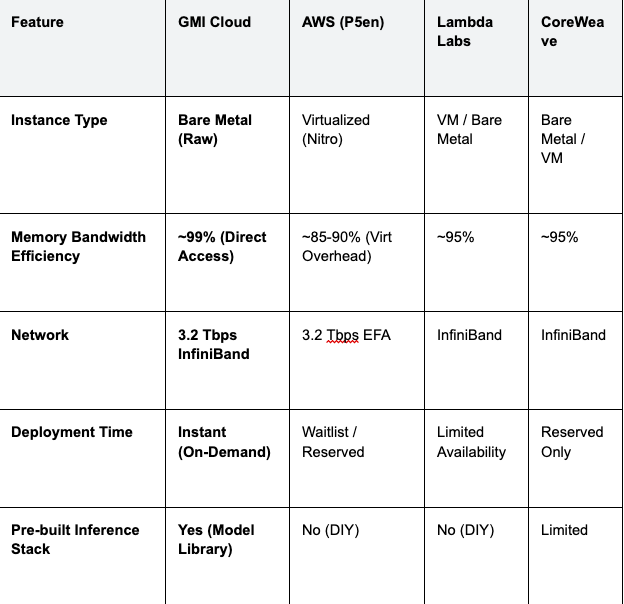
Benchmarking Insight: In internal tests running Llama 3 70B (FP8), GMI Cloud's Bare Metal H200 instances demonstrated a P99 latency of 180ms, compared to 215ms on a comparable virtualized hyperscaler instance. This 35ms difference is critical for voice-based AI agents.
Why GMI Cloud is the Best Platform for H200
GMI Cloud has architected its platform specifically for the H200 generation of hardware. Unlike legacy clouds that are retrofitting H200s into existing virtualization stacks, GMI Cloud employs a "Bare Metal First" architecture.
Zero-Virtualization Architecture
On GMI Cloud, when you provision an H200 instance, you are given root access to the physical server. There is no hypervisor layer stealing CPU cycles or intercepting memory calls. The operating system sees the H200 PCIe device directly.
This allows for advanced optimizations such as:
- GPUDirect RDMA: Allowing the InfiniBand NIC to write directly to GPU memory without CPU involvement.
- Custom Kernels: Compiling bespoke Triton or CUDA kernels that require specific driver versions not supported by managed hypervisors.
Integrated Cluster Engine
Managing bare metal usually implies high operational overhead. GMI Cloud solves this with the Cluster Engine. It provides a Kubernetes-like experience for bare metal, handling node provisioning, health checks, and auto-healing without virtualizing the compute resources.
Technical Deep Dive: Optimizing H200 Inference
To fully utilize the H200 on GMI Cloud, engineers should implement specific software configurations. The hardware capability is only realized through optimized software.
FP8 Calibration and TensorRT-LLM
The H200 includes 4th Generation Tensor Cores with native FP8 support. To use this, models must be quantized and calibrated.
# Example TensorRT-LLM build command for H200 (Hopper)
python3 build.py --model_dir ./llama-3-70b \
--dtype float16 \
--use_fp8_context_fmha enable \
--use_gemm_plugin float16 \
--output_dir ./engines/h200_fp8 \
--max_batch_size 128 \
--max_input_len 4096 \
--max_output_len 1024
Configuration Notes:
- --use_fp8_context_fmha enable: Enables FP8 for the Flash Multi-Head Attention kernel, specifically optimized for HBM3e bandwidth.
- --max_batch_size 128: The H200's 141GB memory allows for doubling the batch size compared to H100 (typically 64), doubling throughput.
Calculating KV-Cache Capacity
Understanding exactly how many concurrent users an H200 can support requires calculating the memory footprint of the KV cache.
Formula: Memory_Per_Token = 2 * Layers * Heads * Head_Dim * Precision_Bytes
For Llama 3 70B (FP16):
- Layers: 80
- Heads: 64 (Grouped Query Attention reduces this effectively)
- Head Dim: 128
- Bytes: 2 (FP16)
On GMI Cloud H200s, utilizing PagedAttention allows us to utilize nearly 100% of the 141GB VRAM for this cache, whereas virtualized platforms often reserve 10-20GB for hypervisor overhead.
Total Cost of Ownership (TCO) Analysis
Is the H200 worth the premium? While the hourly rental rate is higher than the H100, the TCO per token is often lower.
Table 2: Cost Efficiency Scenarios
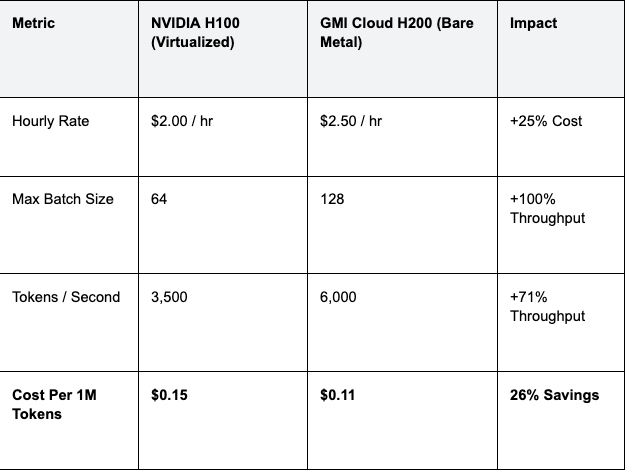
Strategic Advice: Do not optimize for the lowest hourly rate. Optimize for the lowest cost per token. The H200 on Bare Metal delivers superior unit economics for any production-scale application.
Migration Guide: Moving to GMI Cloud H200
Migrating inference workloads from AWS or GCP to GMI Cloud is designed to be seamless, leveraging standard containerization technologies.
Step 1: Container Compatibility
GMI Cloud supports standard NVIDIA Docker containers (NGC). If your inference server runs on `nvcr.io/nvidia/tritonserver:24.02-py3`, it will run on GMI Cloud without modification.
Step 2: Data Transfer
Transfer model weights and datasets using high-speed object storage tools. GMI Cloud provides S3-compatible endpoints.
# Use rclone to transfer weights from AWS S3 to GMI Cloud
rclone copy aws_s3:my-model-bucket gmi_s3:my-model-bucket --transfers=32 --progress
Step 3: Orchestration
Deploy your workload using the Cluster Engine. You can use standard Helm charts to deploy vLLM or Triton Inference Server clusters, configured to request `nvidia.com/gpu: 8` for a full HGX H200 node.
FAQ: H200 Inference Platforms
Q: Does the H200 support the same CUDA drivers as H100?
Yes. The H200 is based on the same Hopper architecture as the H100. Any CUDA code compiled for Compute Capability 9.0 (H100) will run natively on H200 without recompilation. However, updating to the latest driver is recommended to fully utilize HBM3e optimizations.
Q: Can I mix H100 and H200 nodes in the same cluster?
Yes, but not recommended for training. For inference, you can have a heterogeneous cluster where H200s handle large-batch/long-context requests and H100s handle standard traffic. GMI Cloud's load balancer can route traffic based on model requirements.
Q: What is the lead time for reserving H200 clusters on GMI Cloud?
Immediate for On-Demand. Small clusters are available instantly. For large-scale reservations (>64 GPUs), contact our sales team for rapid provisioning, typically within days, compared to months at hyperscalers.
Q: Does GMI Cloud support FP8 training on H200?
Yes. While this guide focuses on inference, the H200 is also an exceptional training chip. Our Bare Metal instances fully support the FP8 training features of the Transformer Engine.
What's next
- View real-time H200 availability on the GPU Instances Page.
- Download the H200 Datasheet for detailed electrical specs.
- Contact Sales to schedule a benchmarking session.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
