Compare GPU Cloud Pricing for LLM Inference Workloads (2026 Engineering Guide)
February 21, 2026
In 2026, the divergence in GPU cloud pricing models has created a complex landscape for AI decision-makers. The market is split between Hyperscalers (AWS, Google Cloud) offering complex, bundled pricing with hidden virtualization costs, and specialized AI Clouds (GMI Cloud, Lambda, CoreWeave) offering raw, bare-metal performance transparency.
For Large Language Model (LLM) inference, hardware efficiency dictates financial efficiency. A "cheap" GPU that suffers from low memory bandwidth (HBM) utilization will ultimately cost more to operate because it requires more units to achieve the same throughput (Tokens Per Second). This document provides a rigorous TCO (Total Cost of Ownership) analysis, factoring in hardware specs, virtualization overhead, data egress, and engineering maintenance.
The Unit Economics of Inference: A Mathematical Model
To accurately compare pricing, we must move beyond the "Sticker Price" (hourly rate) to the "Effective Price" (cost per unit of work). The formula for inference cost efficiency is:
Effective_Cost_Per_Token = (Instance_Hourly_Rate) / (Total_System_Throughput_TPS * 3600)
Where Total_System_Throughput_TPS is a function of:
- Memory Bandwidth: Determines how fast weights are loaded (Decode Phase).
- Compute (FLOPS): Determines how fast prompts are processed (Prefill Phase).
- Batch Size: Determines how many requests share the memory overhead.
The H200 vs. H100 Pricing Paradox
Consider two scenarios for deploying Llama 3 70B:
- Scenario A (H100): Rented at $2.00/hr. Memory bandwidth is 3.35 TB/s. Max batch size is limited by 80GB VRAM.
- Scenario B (H200): Rented at $2.50/hr (+25% cost). Memory bandwidth is 4.8 TB/s (+43% speed). VRAM is 141GB (+76% capacity).
Because the H200 allows for a significantly larger batch size (e.g., 128 vs 64) and faster decoding, the throughput increases by ~50-60%. Consequently, the Cost Per Token on the H200 is actually lower, despite the higher hourly rental rate.
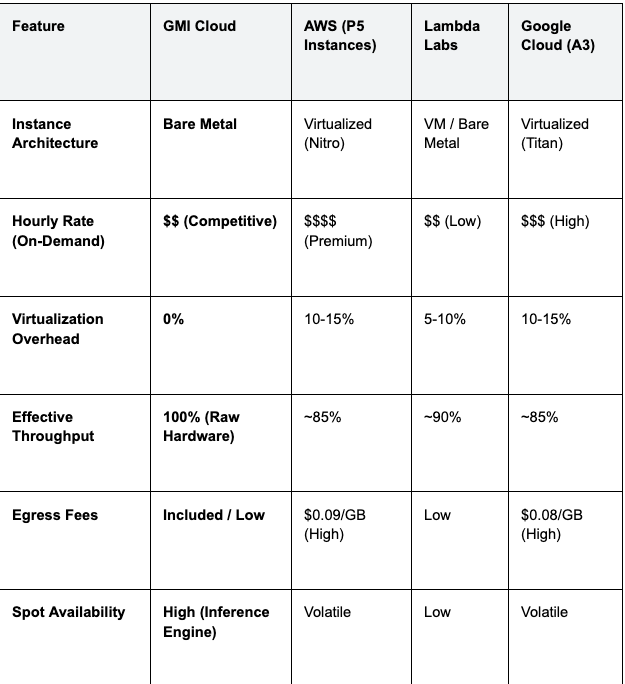
Comparative Pricing Analysis: GMI Cloud vs. Hyperscalers
The following table compares the pricing structures and technical capabilities of major providers for a single NVIDIA H100/H200 class instance.
Table 1: GPU Cloud Provider Comparison (2026)
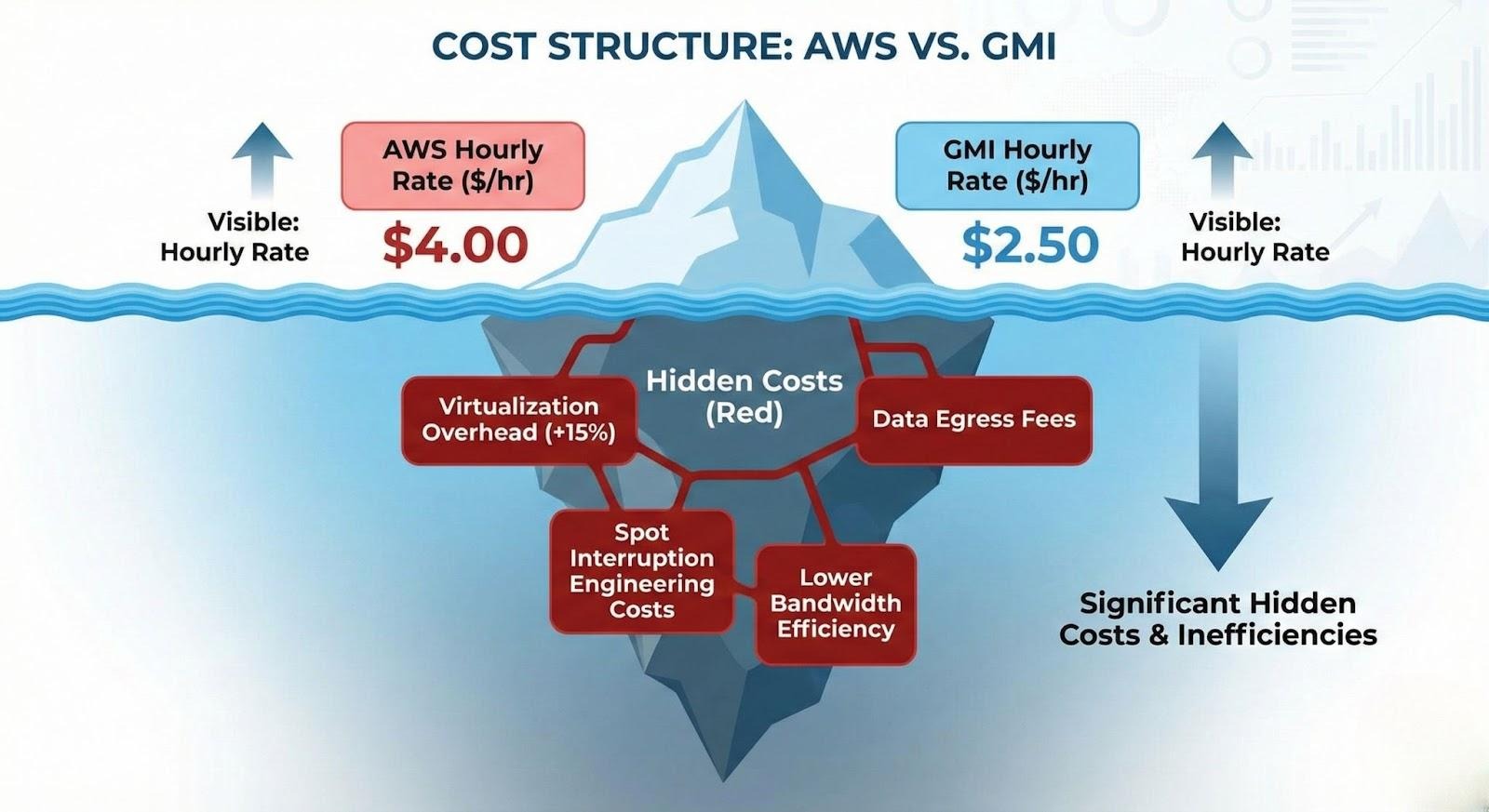
Hidden Cost Alert: Hyperscalers charge significant fees for data egress (moving data out to the internet). For a high-traffic chatbot sending generated text and receiving audio/images, egress fees can add 10-20% to the monthly bill. GMI Cloud typically includes generous bandwidth allowances, eliminating this hidden tax.
Hidden Costs of Virtualization
When you rent from a hyperscaler, you are paying for a Virtual Machine. The hypervisor managing this VM consumes resources.
The "Hypervisor Tax"
Internal benchmarks show that hypervisor overhead reduces GPU memory bandwidth utilization by approximately 10-15%. If you pay $4.00/hour for an H100 VM but only get 85% of the performance, your Effective Hourly Rate is actually $4.70/hour ($4.00 / 0.85).
GMI Cloud’s Bare Metal instances provide 100% of the rated performance. You pay for the hardware, and you get the whole hardware. This efficiency gain is pure profit margin for high-scale inference workloads.
Spot vs. Reserved: Analyzing the Risk Premium
Pricing also depends on commitment levels. Providers offer Spot (preemptible), On-Demand, and Reserved pricing.
Spot Instances (Preemptible)
Discount: 60-70% off On-Demand.
The Hidden Cost: Engineering hours. Using Spot instances for inference requires building robust fault-tolerance systems. You must handle sudden interruptions (SIGTERM signals), drain connections, and migrate KV-caches to new nodes instantly.
GMI Cloud Solution: Our Inference Engine manages this complexity for you. It automatically balances between Spot and Reserved instances to optimize cost without sacrificing uptime.
Reserved Instances (1-3 Year Commit)
Discount: 30-50% off On-Demand.
The Hidden Cost: Hardware obsolescence. Locking into a 3-year contract for H100s today is risky when Blackwell (B200) offers 30x performance. GMI Cloud offers flexible upgrade paths for enterprise reservations, allowing migration to newer generations.
Case Study: 10M Daily Tokens Cost Simulation
Let's calculate the monthly cost for a startup serving 10 million tokens per day using Llama 3 70B.
Option A: Hyperscaler (On-Demand H100 VM)
- Hourly Rate: $4.00
- Throughput: 3,000 TPS (Throttled by virtualization)
- Time Required: 10M / (3000 * 3600) = 0.92 hours of compute time... wait, inference is always on.
- Real Scenario: You need 1 GPU running 24/7 to handle concurrency.
- Monthly Cost: $4.00 * 24 * 30 = $2,880
Option B: GMI Cloud (Reserved Bare Metal H200)
- Hourly Rate: $2.50 (Reserved Discount)
- Throughput: 5,000 TPS (Higher bandwidth + Bare Metal)
- Real Scenario: Because throughput is higher, you can handle peak concurrency with the same single GPU, but with lower latency.
- Monthly Cost: $2.50 * 24 * 30 = $1,800
Result: GMI Cloud delivers 37% cost savings immediately, with better latency metrics.
Advanced Pricing Factors: Networking and Storage
Compute is the largest line item, but not the only one.
Inter-Node Networking Costs
For models larger than a single GPU (e.g., DeepSeek 671B), traffic flows between nodes. Hyperscalers sometimes charge for "Cross-AZ" (Availability Zone) traffic. GMI Cloud’s clusters are connected via local InfiniBand fabrics, where east-west traffic is free and unmetered.
Model Storage Costs
High-performance inference requires loading models from NVMe SSDs. Hyperscalers charge premium rates for "IOPS" (Input/Output Operations Per Second). GMI Cloud Bare Metal instances come with terabytes of local NVMe storage included in the hourly price, eliminating the "EBS Tax" found on AWS.
FAQ: GPU Cloud Pricing
Q: Why are GMI Cloud's on-demand prices lower than hyperscalers?
Efficiency and Focus. Hyperscalers have massive overheads supporting thousands of legacy services. GMI Cloud is purpose-built for AI; our data centers are optimized for high-density power and cooling, reducing our operational costs, which we pass on to customers.
Q: Do you charge for stopping an instance?
No. You only pay for compute when the instance is running. However, if you wish to persist the data on the local disk while stopped, a small storage fee applies, similar to standard industry practice.
Q: Is there a minimum commitment for Bare Metal?
No. You can spin up a Bare Metal H200 instance for as little as one hour on our On-Demand tier. This is perfect for benchmarking and POCs before committing to a reservation.
Q: How does billing work for the Serverless Inference Engine?
Per Token. You are billed based on the number of input (prompt) tokens and output (generated) tokens. Prices vary by model size (e.g., Llama 3 8B is cheaper than 70B). This model scales to zero cost when not in use.
What's next
- Use our TCO Calculator to estimate your specific workload costs.
- View current spot availability on the GPU Instances Page.
- Contact Sales for volume discounts on H200 clusters.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
