
Building scalable AI infrastructure in the cloud requires understanding unique resource demands and implementing cloud-native design principles for sustainable growth.
- AI workloads demand 10-100x resource scaling across lifecycle phases, requiring specialized GPU/TPU infrastructure and advanced cooling systems to handle 100-200 kW per rack power density.
- Microservices architecture with Kubernetes orchestration enables independent scaling of AI components, with 71% of Fortune 100 companies using this approach for containerized deployments.
- Monitor 95th and 99th percentile latencies rather than averages to catch worst-case performance issues and prevent model drift from silently degrading accuracy.
- Implement cost controls through GPU utilization tracking and workload schedulers to prevent spiraling expenses while maintaining near 100% resource efficiency.
- Build security and compliance from day one using frameworks like EU AI Act and NIST AI RMF, as retrofitting protection is significantly more expensive than proactive implementation.
The key to success lies in balancing performance requirements with cost optimization while maintaining robust monitoring and security throughout your AI infrastructure journey.
Building adaptable AI solutions has become one of my top priorities, especially after learning that AI workloads just need resource scaling of 10–100x across lifecycle phases, way beyond the 2–5x range of traditional systems. Traditional storage architectures built for batch processing cannot meet the scale, speed and complexity that AI requires. Data quality remains the most important factor in ensuring model performance. The rapid adoption of AI-powered applications demands effective cloud infrastructure for AI that can handle these unique challenges, and GMI Cloud is designed specifically to support high-performance AI workloads at scale. In this piece, I'll walk you through the key components of scalable AI architecture, from understanding compute-intensive processing demands to implementing practices for AI infrastructure solutions that keep performance high and costs under control.
Understanding Scalability Requirements for AI Workloads
Compute-intensive processing needs
AI workloads consume computational resources at levels that dwarf conventional applications. Training large models just needs specialized hardware like GPUs and TPUs that can handle massive parallel processing. Even fine-tuning smaller models can overwhelm standard infrastructure. The power density requirements tell the story: training workloads require 100 to 200 or more kilowatts per rack, while inference workloads operate at 30 to 150 kW per rack. These numbers reflect the reality that AI systems process unstructured data like images, text and audio in ways that standard IT infrastructure was never designed to support.
GPUs and TPUs have become non-negotiable for expandable AI solutions. Training requires high-density compute clusters with advanced cooling systems. Both workloads put immense pressure on older data center infrastructure. Energy constraints influence scalability decisions more and more, making power availability a board-level concern.
Unpredictable resource patterns across training and inference
Training and inference create different infrastructure needs. Training requires massive compute running across clusters of specialized processors. Inference runs in production environments where latency and availability matter more than raw processing power.
The move happening now changes everything. By 2030, inference workloads are projected to make up more than half of all AI compute. Data center needs for training AI are expected to grow at a CAGR of 22 percent over the next five years and reach more than 60 GW by 2030. Inference workloads will grow even faster at a CAGR of 35 percent and reach more than 90 GW by 2030.
This creates a planning challenge. Training happens offline and tolerates higher latency measured in hours or days. Inference must respond within milliseconds to keep user experiences smooth. The cumulative cost of millions of predictions can exceed initial training costs. This makes inference optimization critical for cloud infrastructure for AI deployments.
Data volume and velocity challenges
Managing larger datasets becomes harder as scale grows. Cleaning, labeling and organizing data requires time and resources. Data quality becomes harder to maintain at scale. Storage architectures must handle data pipelines spanning multiple environments that include on-premises systems, cloud platforms and edge locations.
Performance bottlenecks in traditional systems
Traditional networking systems cannot meet the high bandwidth and low latency needs of AI workloads. Bandwidth often becomes a hidden bottleneck. Distributed training depends on low-latency, high-bandwidth interconnects, but many environments fall short. This causes GPUs to starve even when hardware is available, which is why infrastructure designed for efficient data throughput, such as GMI Cloud, plays a critical role in maintaining consistent GPU utilization. Storage systems struggle to feed accelerators fast enough. Every second GPUs wait on I/O represents wasted chance.
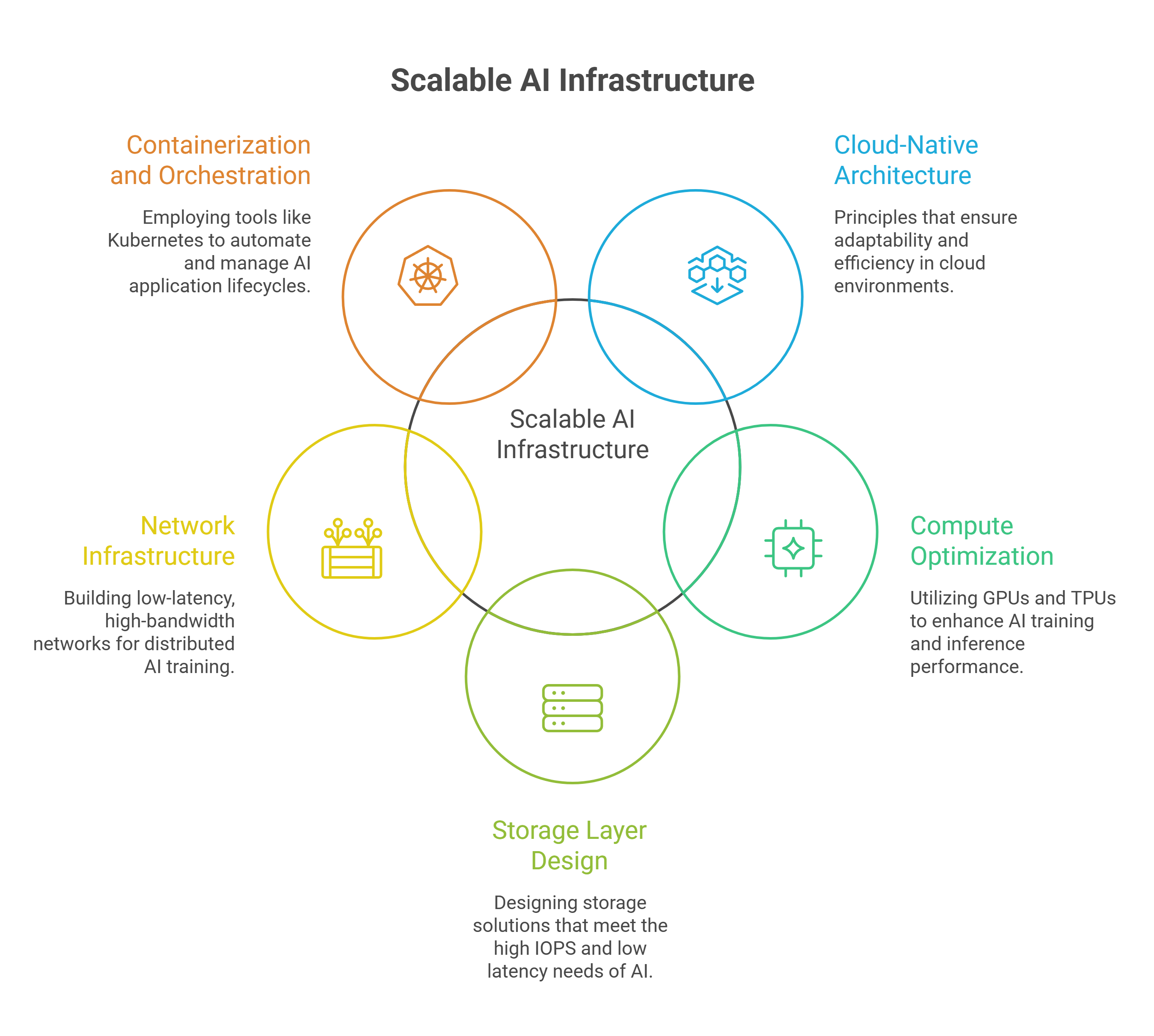
Core Components of Scalable AI Infrastructure in the Cloud
Cloud-native architecture principles
Adaptable AI solutions rest on five core principles that differ from traditional infrastructure. Automation stands first and enables systems to repair, scale, and deploy far faster than manual processes. Cloud-native designs favor stateless components wherever possible. Scaling becomes simple: add more copies to scale up, terminate instances to scale down. Managed services reduce operational overhead by a lot, though teams must balance portability against the time savings these services provide. Authentication applies between each component as defense in depth, eliminating the concept of trusted internal zones. The architecture evolves as organizational needs and cloud capabilities change.
Compute optimization with GPUs and TPUs
Cloud TPUs are application-specific integrated circuits designed for neural network tasks. They feature specialized matrix multiply units and proprietary interconnect topology. Training large language models is where they excel. They handle intensive computations with minimal power consumption. GPUs offer broader adaptability in computational tasks of all types beyond AI, with widespread compatibility in TensorFlow, PyTorch, and other frameworks. TPUs integrate tightly with TensorFlow and enhance performance but potentially limit flexibility. Assigning these accelerators based on priority, availability, and compute requirements maximizes utilization efficiently. GMI Cloud further improves this by optimizing GPU allocation and real-time resource utilization across workloads.
Storage layer design for AI workloads
AI storage just needs high IOPS and ultra-low latency, especially when you have model training and inference. Object storage excels at scale with unlimited capacity reaching exabytes, though maximizing throughput needs hundreds of threads and large files. Managed Luster serves workloads with small files under 50 MB and latency requirements below 1 millisecond. Storage tiers balance cost and performance. Frequently accessed data sits on high-speed flash, while less-critical data moves to budget-friendly slower storage.
Network infrastructure for distributed AI
Distributed training demands low-latency, high-bandwidth interconnects. Traditional off-the-shelf Ethernet with deep packet buffers introduces high latency and unpredictable jitter problematic for synchronous AI workloads. High-speed cluster networking synchronizes gradients among GPUs and reduces bottlenecks in model parallelism. Data networking connects storage to compute and ensures datasets reach cluster nodes quickly.
Containerization and orchestration tools
Kubernetes dominates container orchestration and serves as the primary tool for 71% of Fortune 100 companies. Container orchestration automates deployment, scaling, and networking throughout application lifecycles. It manages hundreds or thousands of containers at scale. AI-driven automation in Kubernetes learns traffic patterns to scale resources up or down and reduces costs during low load periods automatically.
Design Patterns for Scalable AI Systems
Microservices architecture for AI components
Microservices break AI systems into loosely coupled services. Each handles specific functions like data processing or model inference. This approach allows independent scaling based on just need. Monolithic architectures create bottlenecks in contrast. Each service can be developed, deployed and scaled on its own, which enhances fault isolation. AI agents function as microservices with decision-making logic and make autonomous behaviors possible through event-driven communication. Approximately 66% of organizations hosting generative AI models use Kubernetes for inference workloads.
Distributed training strategies
Data parallelism divides datasets into partitions that match available nodes. Each node runs a copy of the model on its data subset. Model parallelism segments the model across nodes, with each part running on the same data. Synchronous training aggregates gradients at each step to ensure consistency. Asynchronous training updates variables on its own. Pipeline parallelism processes data batches sequentially through model stages, like an assembly line.
Model serving and inference scaling
Dynamic batching processes whatever requests have arrived when ready and eliminates wait times. Single requests process right away during light load. Batching utilizes GPU parallel power during heavy load. Systems managed to keep subsecond P99 latency with 1,000 concurrent requests per pod.
Data pipeline scalability approaches
Batch pipelines process large volumes at scheduled intervals. Real-time pipelines handle streaming data for immediate analysis. Hybrid pipelines combine both approaches for flexibility and support continuous model updates as new data arrives.
Best Practices for Deploying Scalable AI in the Cloud
Monitoring and performance optimization
The right metrics separate reliable AI deployments from failing ones. Prometheus and IBM Turbonomic monitor latency, throughput, and model performance over time. Averages mislead; I focus on 95th and 99th percentile latencies to catch the worst user experiences. Model drift happens as data changes, and continuous observability is required to detect accuracy degradation before business outcomes suffer. Retraining schedules and routine maintenance reviews prevent small problems from escalating.
Cost management strategies
AI costs spiral without visibility into GPU utilization and token consumption. Workload schedulers allocate compute and prevent over-purchasing of GPU resources. Cost per unit of work must be tracked, and optimization for near 100% GPU utilization controls expenses. GMI Cloud helps reduce inefficiencies and wasted compute by improving GPU utilization and resource allocation. Cloud FinOps practices bring technology, finance, and business teams together to improve sustainable financial value.
Security and compliance considerations
Compliance built in from day one beats modernizing later. The EU AI Act and NIST AI RMF provide frameworks for responsible AI deployment. Input validation segregates data from instructions, while threat modeling hardens models against documented vulnerabilities. Encryption, multi-factor authentication, and continuous monitoring safeguard AI environments.
Automation and Infrastructure-as-Code
AI-driven IaC automates infrastructure provisioning through tools like Terraform. Version-controlled infrastructure changes follow the same testing and review processes as code deployments. CI/CD pipelines automate deployment while modular code simplifies updates.
Testing for scale
Performance testing identifies where inference pipelines break under load. The 95th and 99th percentiles reveal system stability better than averages. Concurrency tests find breaking points in inference servers before production traffic hits them.
Conclusion
Flexible AI architecture requires careful planning across compute, storage, network, and orchestration layers. Understanding the unique needs of training and inference workloads are the foundations of this approach, while cloud-native principles and automation streamline processes for long-term success. Teams that prioritize monitoring, cost optimization, and security from day one will build systems that scale well, especially when leveraging infrastructure such as GMI Cloud that is purpose-built for AI workloads. Start with the fundamentals outlined here, and your AI infrastructure will handle growth without breaking your budget or compromising performance.
FAQs
What makes AI workloads different from traditional applications in terms of resource requirements?
AI workloads require significantly more computational resources than conventional applications, demanding 10-100x resource scaling across lifecycle phases compared to just 2-5x for traditional systems. Training large models needs specialized hardware like GPUs and TPUs with power densities of 100-200 kilowatts per rack, while inference workloads operate at 30-150 kW per rack. This is because AI systems process unstructured data like images, text, and audio in ways that standard IT infrastructure wasn't designed to handle.
How should I approach building scalable AI cloud infrastructure for my projects?
Start simple with containerized workloads, autoscaling capabilities, and solid monitoring from day one. Invest early in observability and Infrastructure-as-Code so experiments can transition to production without complete rewrites. Only add complexity once actual usage proves it's necessary. Focus on cloud-native principles including automation, stateless components where possible, and managed services to reduce operational overhead while maintaining the flexibility to scale.
What are the key differences between AI training and inference workloads?
Training requires massive compute running continuously across clusters of specialized processors and can tolerate higher latency measured in hours or days. Inference runs in production environments where latency and availability are critical, requiring responses within milliseconds. By 2030, inference workloads are projected to make up more than half of all AI compute, growing at 35% CAGR compared to 22% for training workloads, making inference optimization essential for cost control.
Which metrics should I monitor to ensure my AI infrastructure performs reliably?
Focus on 95th and 99th percentile latencies rather than averages to catch the worst user experiences and identify system stability issues. Track GPU utilization, throughput, model performance over time, and watch for model drift as data shifts. Monitor cost per unit of work and aim for near 100% GPU utilization to control expenses. Continuous observability helps detect accuracy degradation before it impacts business outcomes.
Should I use GPUs or TPUs for my AI workloads?
TPUs are application-specific integrated circuits designed specifically for neural network tasks, excelling at training large language models with minimal power consumption but integrating tightly with TensorFlow. GPUs offer broader adaptability across computational tasks beyond AI with widespread compatibility across TensorFlow, PyTorch, and other frameworks. Choose based on your specific workload requirements, framework preferences, and whether you need specialized performance for neural networks or more general computational flexibility.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
