How Can I Run Large LLMs Without Managing Infrastructure? (2026 Engineering Guide)
February 21, 2026
For many AI startups and enterprise teams, the "Day 2" operations of running Large Language Models (LLMs) act as a significant barrier to innovation. Managing a fleet of GPUs involves complex tasks: patching drivers, balancing loads, handling node failures, and optimizing CUDA kernels for specific model architectures. The goal of "No-Infrastructure" AI is to decouple the model application logic from the underlying hardware operations.
This guide explores the architectural shift towards Serverless Inference and Managed Endpoints. We analyze how platforms like GMI Cloud enable developers to deploy models like DeepSeek V3 and Llama 3 with a single API call, relying on automated orchestration layers to handle the physical constraints of memory bandwidth and compute availability.
The Spectrum of Infrastructure Abstraction
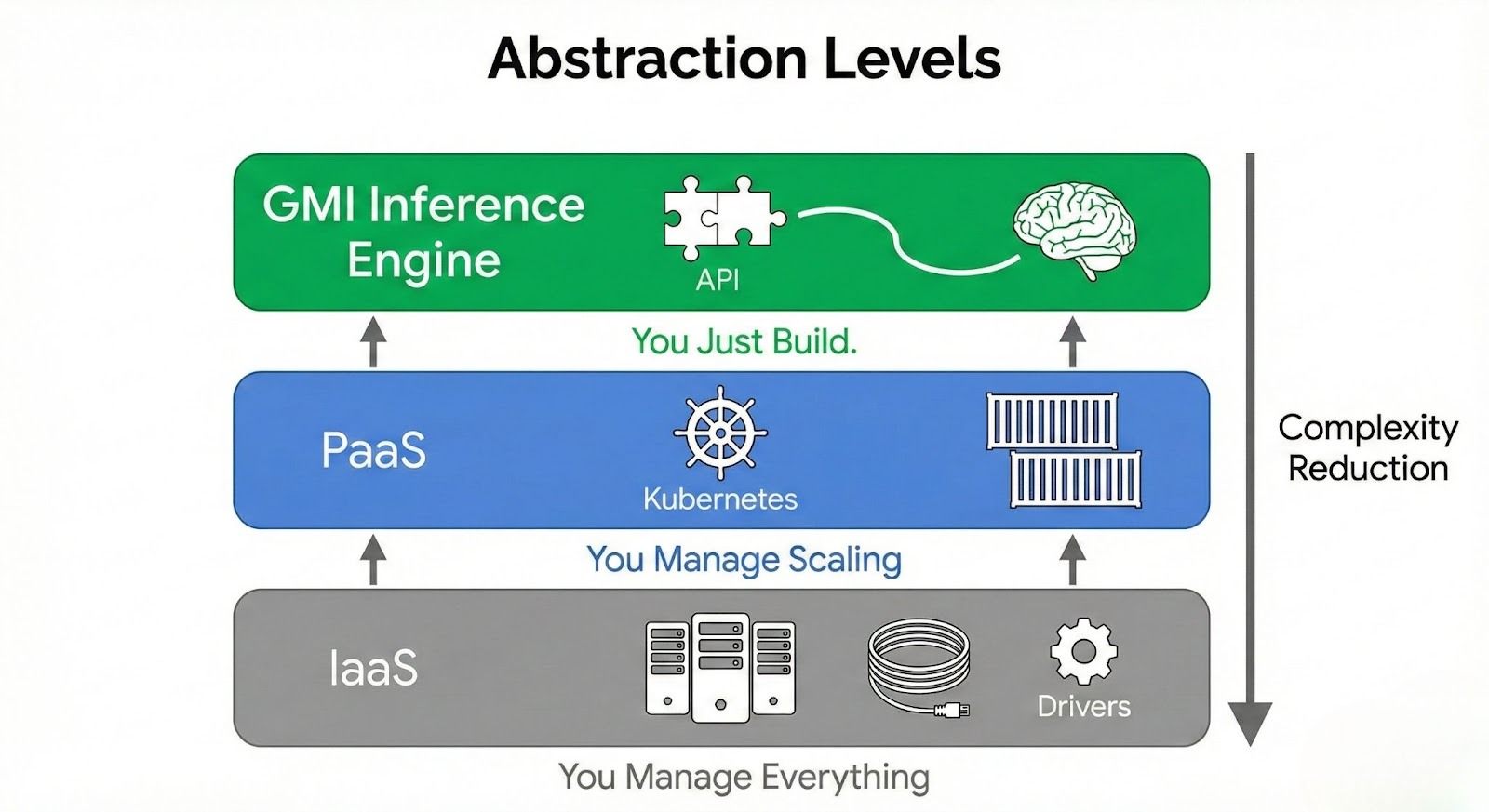
To understand how to remove infrastructure management from your workflow, it is necessary to visualize the layers of the AI stack. The higher you go, the less you manage, but typically the less control you have. The sweet spot for modern AI engineering is the Managed Inference Engine.
Level 1: IaaS (Infrastructure as a Service)
Example: Renting Raw EC2 Instances or Bare Metal Servers.
- You Manage: OS, Drivers, Docker, Kubernetes, Load Balancing, Model Weights, Auto-scaling logic.
- Pros: Maximum control.
- Cons: Massive DevOps burden. If a node fails, you wake up at 3 AM.
Level 2: Managed Kubernetes (PaaS)
Example: EKS, GKE, GMI Cluster Engine.
- You Manage: Pod definitions, Helm charts, Scaling policies.
- Pros: Automated orchestration.
- Cons: Still requires knowledge of `kubectl` and container networking.
Level 3: Serverless Inference Engines (The "No-Infra" Solution)
Example: GMI Cloud Inference Engine.
- You Manage: API Key and Model Name.
- Platform Manages: Everything else (Hardware, Drivers, Scaling, Queues, Security).
- Pros: Zero DevOps. Instant deployment. Scale-to-Zero capability.
How Serverless Inference Works Under the Hood
When you make an API call to a "No-Infra" platform, a complex sequence of automated events occurs in milliseconds. Understanding this flow helps in optimizing your application's architecture.
The Global Gateway and Router
Your request first hits a Global Load Balancer. This component terminates TLS and inspects the request headers to identify the target model (e.g., `llama-3-70b`). It then queries the Placement Service to find a region with available capacity and the lowest latency.
The Warm Pool and Cold Starts
One of the biggest challenges in serverless GPU computing is the "Cold Start." Loading 140GB of model weights from disk to HBM3e memory takes time (approx. 10-20 seconds on H200).
To mitigate this, GMI Cloud maintains a "Warm Pool" of pre-loaded models. These are GPU instances that are active but idle, holding the model in memory. When your request arrives, it is routed to a warm instance, resulting in <50ms start-up latency. If traffic surges beyond the warm pool capacity, the autoscaler provisions new nodes from the "Cold Pool," using high-speed NVMe and RDMA to load weights as fast as the hardware allows.
Multi-LoRA Serving
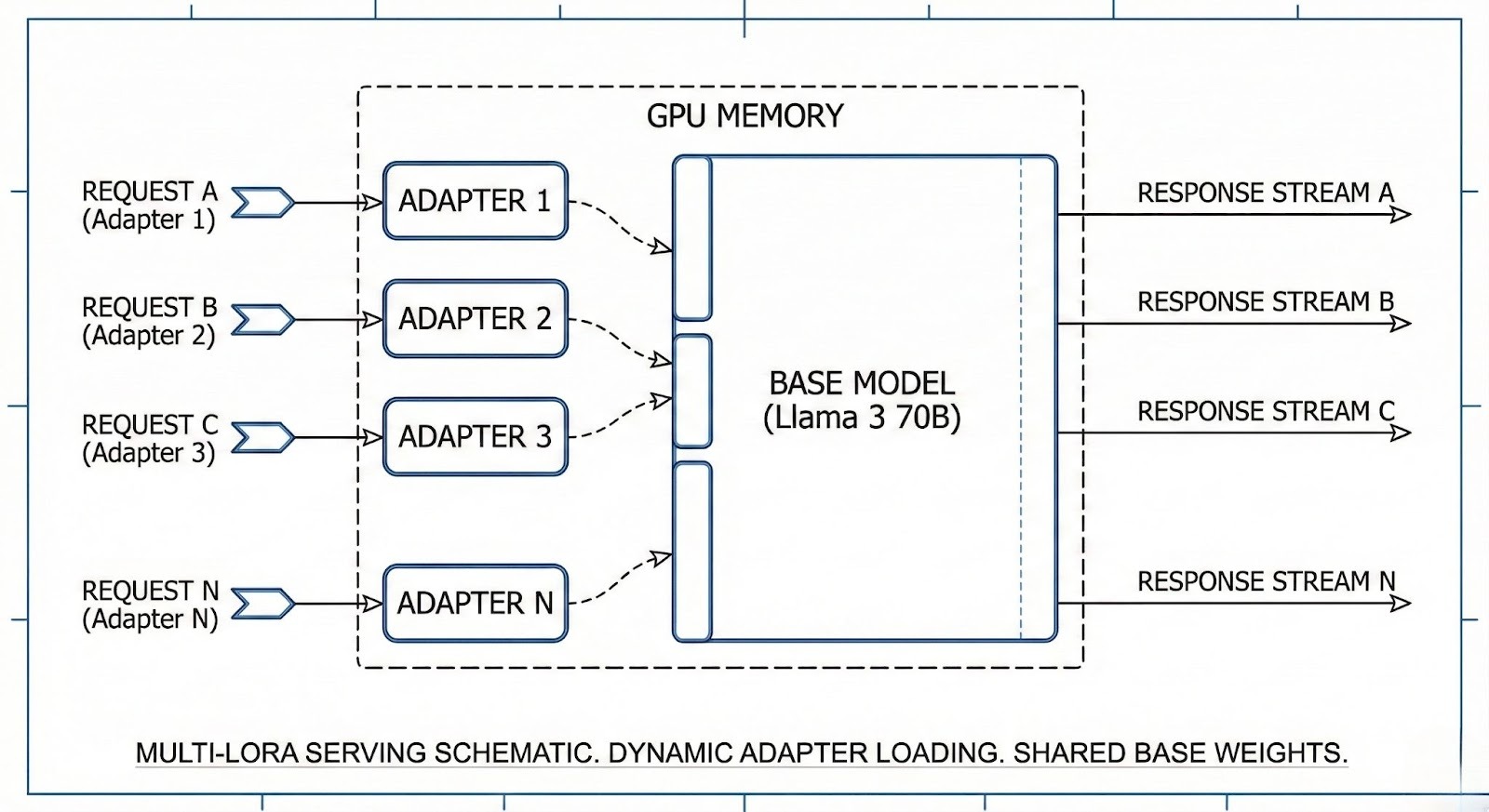
For users who need custom fine-tuned models without managing dedicated GPUs, we utilize Multi-LoRA Serving. A single base model (e.g., Llama 3 70B) is loaded into GPU memory. When a request comes in with a specific LoRA adapter ID, the inference engine dynamically loads the small LoRA weights (adapters) into the computation graph at runtime. This allows thousands of custom models to be served from a single GPU cluster, making "No-Infra" fine-tuning economically viable.
The Role of Hardware in Serverless Performance
Even though you are not managing the hardware, the underlying hardware determines your application's performance. "Serverless" does not mean "Hardware-less."
GMI Cloud's Inference Engine runs exclusively on Bare Metal H200 Instances. This offers distinct advantages over serverless platforms built on virtualized clouds:
- No Noisy Neighbors: Strict isolation ensures your TTFT (Time to First Token) is consistent.
- Fastest Decoding: The H200's 4.8 TB/s memory bandwidth ensures that token generation is blazing fast, even for concurrent users.
- High Availability: Underlying clusters are connected via InfiniBand, allowing for rapid failover if a node becomes unhealthy.
Comparison: Managing Infra vs. GMI Inference Engine
The following table illustrates the operational differences between running your own cluster and using GMI Cloud's managed solution.
Table 1: Operational Responsibility Matrix
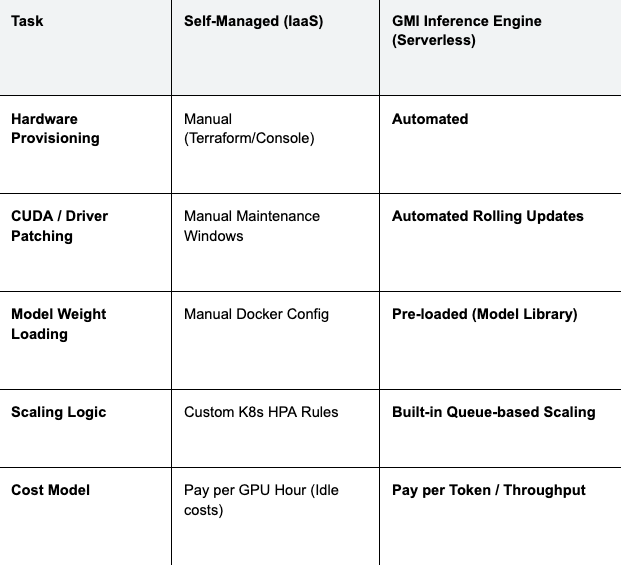
Engineering Insight: By switching to GMI Cloud's Inference Engine, teams typically see a reduction in TCO (Total Cost of Ownership) of 30-50%, primarily by eliminating the cost of idle GPUs and the salaries associated with 24/7 DevOps coverage.
Integration Guide: The OpenAI-Compatible API
The standard interface for "No-Infra" LLMs is the OpenAI-compatible REST API. This ensures that you can swap backends without rewriting your application code.
Python Example
Here is how to connect to GMI Cloud's managed infrastructure using the standard OpenAI Python SDK:
import os
from openai import OpenAI
# Initialize client with GMI Cloud Base URL
client = OpenAI(
base_url="https://api.gmicloud.ai/v1",
api_key=os.environ.get("GMI_API_KEY"),
)
# Deployment is handled by the platform. You just call the model.
response = client.chat.completions.create(
model="deepseek-v3",
messages=[
{"role": "system", "content": "You are a backend engineering expert."},
{"role": "user", "content": "Explain the advantages of serverless GPU computing."}
],
temperature=0.7,
stream=True,
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
cURL Example
For quick testing from the command line:
curl https://api.gmicloud.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $GMI_API_KEY" \
-d '{
"model": "llama-3-70b-instruct",
"messages": [
{"role": "user", "content": "Hello, world!"}
],
"temperature": 0.7
}'
Security and Compliance in a Serverless World
A common concern with "No-Infra" solutions is security. If you don't manage the server, how do you secure the data?
GMI Cloud implements a "Shared Responsibility Model" optimized for enterprise security:
- Tenant Isolation: Although the control plane is shared, the data plane (inference execution) occurs on isolated GPU instances. We use namespaces and network policies to ensure data never leaks between tenants.
- Ephemeral Processing: For inference workloads, data is processed in memory and immediately discarded. We provide a guarantee that no customer data is used for model training.
- Encryption: All API traffic is encrypted via TLS 1.3. At rest, any custom weights or LoRA adapters you upload are encrypted using AES-256.
Advanced Configurations: Rate Limits and Quotas
In a managed environment, "No-Infra" also means "No-Noise." To prevent a single tenant from monopolizing the cluster capacity, we implement intelligent rate limiting.
- RPM (Requests Per Minute): Controls the volume of incoming API calls.
- TPM (Tokens Per Minute): Controls the throughput consumption, protecting against extremely long context requests.
Enterprise customers can request Dedicated Throughput quotas, which effectively reserves a slice of the serverless cluster exclusively for their organization, guaranteeing capacity during peak hours without the hassle of managing the nodes themselves.
FAQ: Managed Inference
Q: Can I use custom models with the Inference Engine?
Yes. You can upload your custom fine-tuned weights (LoRA or full weights) to our secure model registry. Once uploaded, they become available via the API just like a standard model, with the platform handling the loading and scaling.
Q: What happens if the service goes down?
Redundancy. Our serverless backend is deployed across multiple availability zones. If one zone fails, traffic is automatically re-routed to a healthy zone. We offer a 99.99% uptime SLA for enterprise tiers.
Q: Is serverless always cheaper than dedicated?
Not always. Serverless is cheaper for spiky or low-volume traffic. If you have a constant, high-utilization workload (e.g., 24/7 processing), renting Reserved Instances and managing the cluster yourself (or using our Managed Cluster service) may be more cost-effective per token.
Q: Does GMI Cloud support function calling?
Yes. Our managed models, including Llama 3 and DeepSeek, are optimized to support tool use and function calling formats, enabling agentic workflows without infrastructure setup.
What's next
- Get your API key from the GMI Cloud Studio dashboard.
- Read the API reference in our Documentation Hub.
- Explore Supported Models to see what you can run today.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
