How to Achieve Ultra-Low Latency LLM Inference in the Cloud (2026 Engineering Guide)
Achieving ultra-low latency (sub-20ms Inter-Token Latency) for Large Language Models requires a holistic optimization of the inference stack. By migrating from virtualized containers to GMI Cloud’s Bare Metal H200 Infrastructure , employing TensorRT-LLM with C++ runtimes, and uti
February 21, 2026
In the realm of real-time AI—encompassing Voice Agents, High-Frequency Trading (HFT) Copilots, and Autonomous Robotics—latency is not merely a performance metric; it is the boundary between usability and failure. A voice assistant with a 500ms delay feels mechanical; one with a 100ms delay feels human.
Achieving this level of performance in the cloud is notoriously difficult due to the "Latency Stack"—the accumulation of delays from network hops, hypervisor interrupts, Python interpretation overhead, and memory bandwidth bottlenecks. This guide provides a comprehensive engineering blueprint for constructing an Ultra-Low Latency (ULL) inference pipeline, utilizing the latest hardware acceleration from NVIDIA H200 GPUs and bare-metal orchestration strategies.
Defining Ultra-Low Latency in 2026
Before optimizing, we must define the targets. For production LLM inference, ULL is characterized by two distinct metrics:
Time to First Token (TTFT)
Target: < 100ms (including network RTT).
This is the time from the user sending the request to seeing the first character. It is dominated by the "Prefill" phase—processing the prompt and retrieving context (RAG).
Inter-Token Latency (ITL)
Target: < 20ms (approx. 50 tokens/second).
This is the speed of generation. For voice applications, this must exceed human speech rates (approx. 150 words/minute) to allow for smooth text-to-speech (TTS) streaming without buffer underruns.
Layer 1: Hardware Selection (The Physics of Speed)
Latency in the decode phase is strictly bound by memory bandwidth. The GPU must load the entire model into the Streaming Multiprocessors (SMs) for every single token generated.
The H200 Advantage: The NVIDIA H200 features HBM3e memory with 4.8 TB/s bandwidth. Compared to the H100 (3.35 TB/s) and A100 (2.0 TB/s), this provides a linear reduction in ITL.
Table 1: Theoretical Latency Limits by Hardware
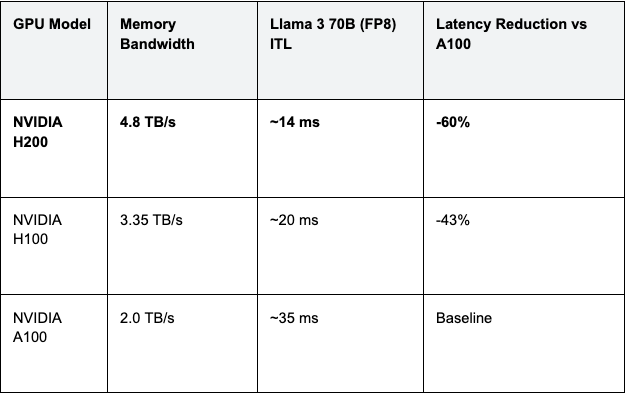
Engineering Insight: On GMI Cloud, H200 instances are available as Bare Metal. This is crucial because virtualization layers on hyperscalers can consume 10-15% of this raw bandwidth for memory translation (SLAT), effectively downgrading an H200 to H100 speeds. Check our pricing page for H200 availability.
Layer 2: Infrastructure Optimization (Killing Jitter)
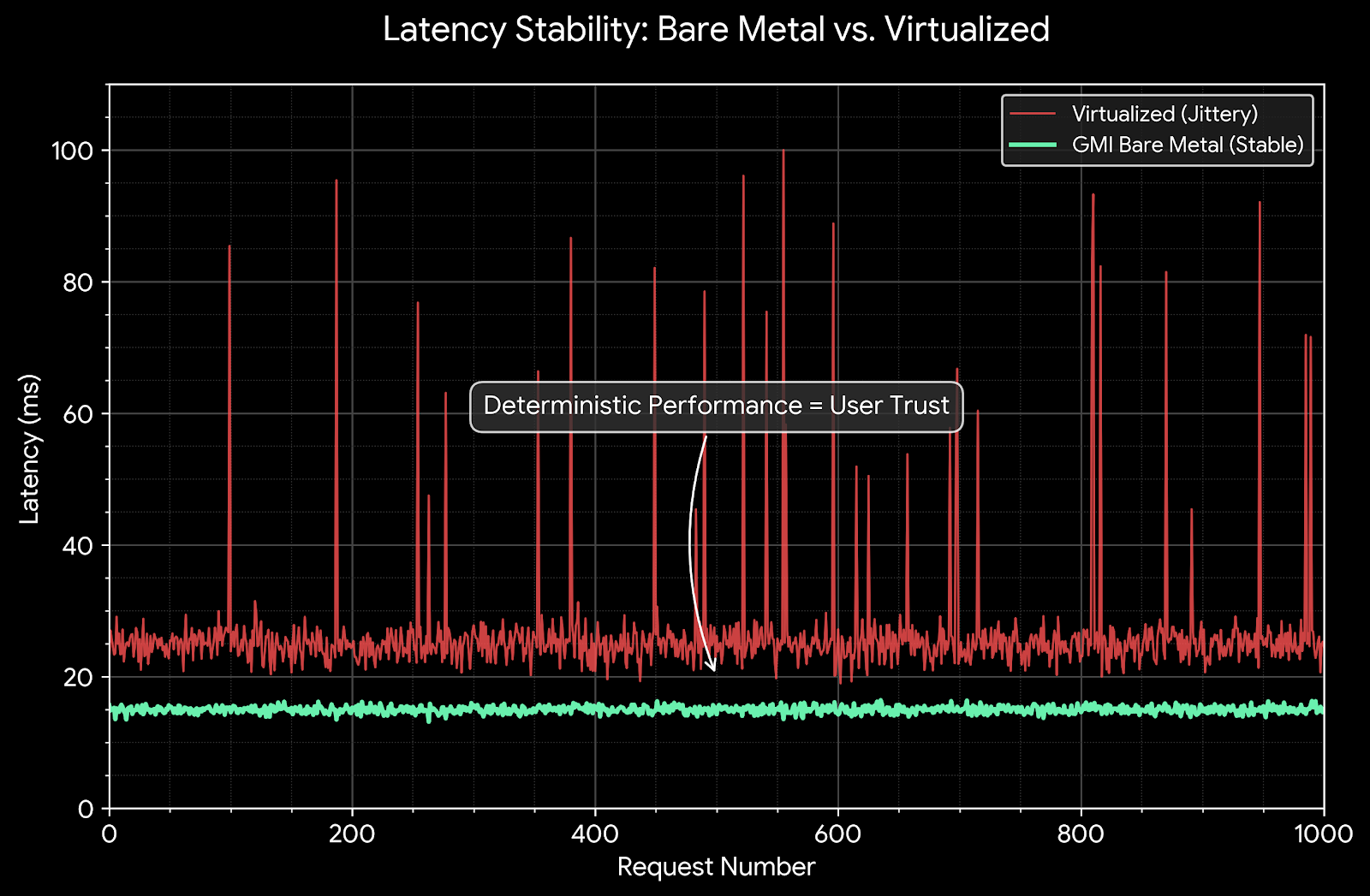
Hardware sets the speed limit; infrastructure determines if you reach it. The enemy of ULL is Jitter (variance in latency). In a shared cloud environment, jitter comes from "Noisy Neighbors" and Hypervisor interrupts.
Bare Metal vs. Virtualization
In a virtualized environment (AWS EC2, Google Compute Engine), the GPU is passed through to the VM via SR-IOV or direct path. However, the CPU interrupts generated by the GPU upon kernel completion must be intercepted by the Hypervisor and injected into the VM. This "Context Switch" adds variable latency (10μs - 500μs) to every token.
Solution: Use GMI Cloud Bare Metal Instances. The OS kernel interacts directly with the PCIe root complex. There is no hypervisor. Interrupts are handled instantly, reducing P99 latency jitter by an order of magnitude.
Network Tuning: DPDK and Kernel Bypass
For the absolute lowest latency, the standard Linux networking stack (TCP/IP) is too slow. It involves multiple memory copies between the NIC buffer and user space.
Solution: Utilize DPDK (Data Plane Development Kit) or RDMA (Remote Direct Memory Access) over InfiniBand. GMI Cloud’s 3.2 Tbps InfiniBand network allows application data to bypass the kernel entirely, landing directly in GPU memory via GPUDirect RDMA. This reduces network traversal time to microseconds.
Layer 3: Software Optimization (The C++ Advantage)
While Python-based inference engines like vLLM are popular for their ease of use, the Python Global Interpreter Lock (GIL) and interpretation overhead add latency that is unacceptable for ULL workloads.
TensorRT-LLM (C++ Runtime)
To achieve ultra-low latency, we recommend migrating to NVIDIA TensorRT-LLM. This is a highly optimized C++ library that compiles the model definition into a binary execution graph.
- Kernel Fusion: Fuses multiple CUDA kernels (e.g., MatMul + Bias + Activation) into a single kernel to reduce memory I/O and launch overhead.
- Static Memory Allocation: Pre-allocates all necessary buffers during the build phase, eliminating `malloc`/`free` calls during inference.
CUDA Graphs
For small batch sizes (Batch Size = 1 for ULL), the CPU overhead of launching kernels can exceed the execution time of the GPU kernel itself. This is known as being "CPU-bound."
Solution: Enable CUDA Graphs in TensorRT-LLM. This technology captures the sequence of kernel launches and replays them as a single graph execution. This moves the scheduling burden from the CPU to the GPU's internal Work Distributor, virtually eliminating CPU launch latency.
# Example TensorRT-LLM Config for Low Latency
builder_config = builder.create_builder_config(
name="llama-3-70b-latency",
precision="fp8",
max_batch_size=1, # Force optimization for single-stream latency
max_input_len=1024,
max_output_len=512,
use_cuda_graph=True # Critical for reducing CPU overhead
)
Layer 4: Algorithmic Optimization
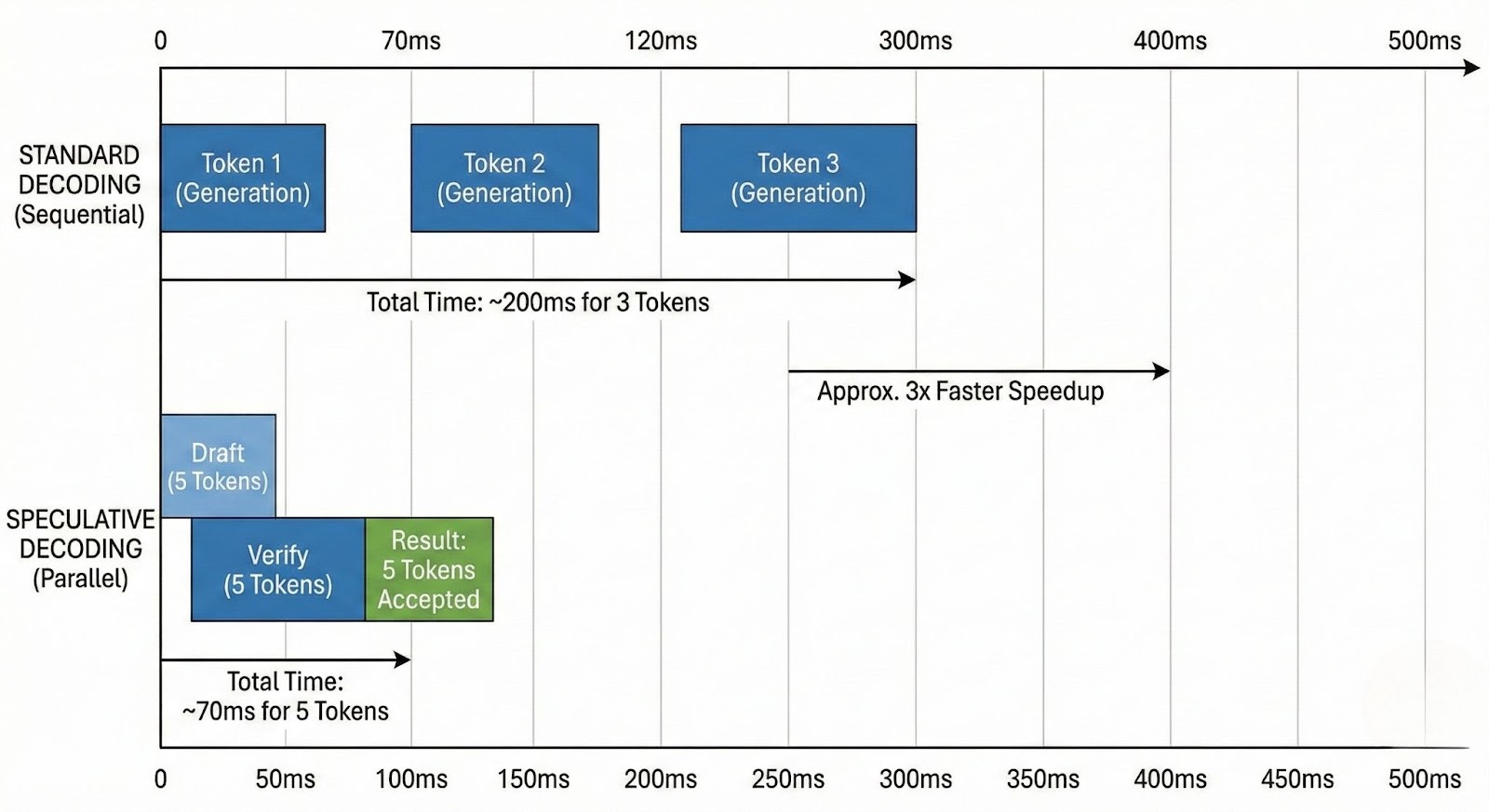
Beyond systems engineering, we can modify how the model generates tokens to cheat the latency curve. GMI Cloud's Inference Engine supports these optimizations natively.
Speculative Decoding
This technique uses a small, fast "Draft Model" (e.g., Llama 3 8B) to generate a speculative sequence of tokens (e.g., 5 tokens). The large "Target Model" (e.g., Llama 3 70B) then validates these tokens in a single parallel step.
- If the draft is correct, you generate 5 tokens for the cost of 1 verification step.
- On GMI Cloud H200s, utilizing the high bandwidth to run the draft and target models on the same GPU minimizes the communication overhead, yielding 2x-2.5x wall-clock speedups.
Medusa Heads
Similar to speculative decoding but without a separate draft model. "Medusa" adds extra heads to the LLM that predict multiple future tokens simultaneously. This requires zero changes to the inference infrastructure but requires a specific fine-tuning of the model weights.
The "Single-Stream" Architecture
Achieving ULL requires a paradigm shift in deployment architecture. Instead of maximizing throughput (Tokens/Sec) via large batches, you must optimize for Latency (Time/Token) via single-stream processing.
Dedicated Instances vs. Serverless
Serverless APIs (like OpenAI or Fireworks) use continuous batching to interleave requests from hundreds of users. While efficient, this introduces queuing delays. For ULL, you must use Dedicated Instances.
On GMI Cloud, you can reserve a single H200 and configure the serving engine (Triton Inference Server) with max_batch_size=1. This ensures that when a request arrives, it has exclusive access to the entire GPU's compute and bandwidth, guaranteeing the lowest possible deterministic latency.
Case Study: High-Frequency Trading (HFT) Copilot
A financial firm needed an LLM to analyze news headlines and execute trades within 200ms.
- Initial Setup (AWS P4d): Llama 3 8B on A100. TTFT was 150ms, but P99 jitter spiked to 400ms due to virtualization.
- Optimized Setup (GMI Cloud H200):
- Hardware: Bare Metal H200.
- Software: TensorRT-LLM with CUDA Graphs enabled.
- Network: Direct fiber connection to the exchange (Direct Connect).
- Result: Stable TTFT of 45ms. ITL of 8ms. Total transaction time < 100ms.
FAQ: Ultra-Low Latency Inference
Q: Can I achieve ULL with Python/vLLM?
It's difficult. While vLLM is fast, the Python overhead is noticeable at batch size 1. For sub-20ms latency targets, C++ backends like TensorRT-LLM or TGI (Text Generation Inference) on Bare Metal are superior.
Q: Does FP8 quantization affect latency?
Yes, positively. FP8 reduces the model size by half, effectively doubling the available memory bandwidth. Since decoding is bandwidth-bound, FP8 directly halves the Inter-Token Latency (ITL).
Q: Why is Bare Metal better than Kubernetes for latency?
Resource Contention. Kubernetes introduces overlay networks (CNI) and sidecar proxies (like Envoy in Istio) which add micro-latencies. For extreme ULL, running the inference binary directly on the Bare Metal OS removes these intermediate hops. Learn more about our Bare Metal Solutions.
Q: How do I measure latency accurately?
Client-side metrics. Do not trust server logs alone. Measure "Time to First Byte" (TTFB) and "Inter-Token Arrival Time" at the client application to account for network traversal. Use GMI Cloud's localized regions (e.g., Taipei for Asian users) to minimize speed-of-light delays.
What's next
- Deploy an optimized TensorRT-LLM engine using GMI Cloud's Model Library.
- Benchmark H200 performance vs A100 using our Interactive Demo.
- Contact Engineering Support for help tuning CUDA Graphs on Bare Metal.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
