Lowest Latency AI Inference Provider for Open-Source LLMs (2026 Engineering Guide)
February 21, 2026
In 2026, the race for "Lowest Latency" is no longer about who has the fastest theoretical GPU, but who has the most efficient software-hardware stack. While many providers offer NVIDIA H100s or H200s, the performance gap between a virtualized instance (on AWS or GCP) and a bare metal instance (on GMI Cloud) can be as high as 30% in terms of Time to First Token (TTFT) and tail latency (P99).
This guide dissects the engineering physics of latency. We analyze the specific bottlenecks in the inference pipeline—from network interrupts to kernel launch overhead—and demonstrate why GMI Cloud’s architecture is optimized to shave milliseconds off every request for mission-critical applications like Voice AI, Algorithmic Trading, and Real-time Agents.
The Physics of Latency: Where Milliseconds Go
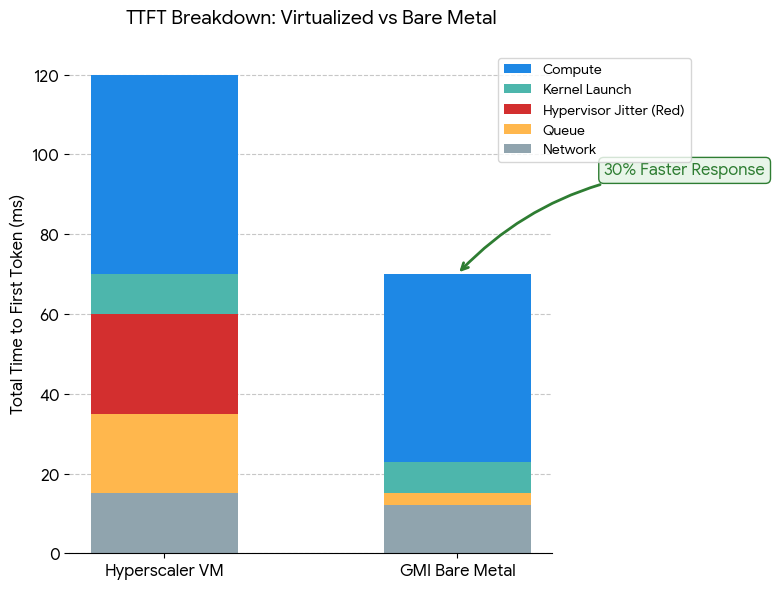
To identify the lowest latency provider, one must understand the components of Total Inference Latency. It is not a single number, but a sum of discrete operations:
1. Network Latency (The Transport Layer)
Before the GPU even sees the request, data must travel from the user to the data center. GMI Cloud minimizes this via strategic edge locations (US-West, APAC) and high-performance ingress gateways.
2. Queue & Schedule Latency (The Orchestration Layer)
In serverless or shared environments, requests often sit in a queue waiting for a slot. GMI Cloud’s Dedicated Bare Metal Instances eliminate this "noisy neighbor" contention. You own the queue, ensuring instant scheduling.
3. Time to First Token (TTFT - The Prefill Phase)
This is the time to process the input prompt. It is compute-bound (FLOPS). The NVIDIA H200 on GMI Cloud accelerates this using the Transformer Engine with FP8 precision, delivering 2x the throughput of FP16 on H100.
4. Inter-Token Latency (ITL - The Decode Phase)
This is the time between generating each subsequent token. It is memory-bound (Bandwidth). The H200’s 4.8 TB/s HBM3e bandwidth is the critical factor here. However, virtualization can "steal" up to 15% of this bandwidth for host OS operations.
Why Virtualization Kills Low Latency
Most hyperscalers (AWS, Azure, GCP) rely on Hypervisors (like KVM or proprietary Nitro systems) to slice physical servers into Virtual Machines (VMs). While efficient for the provider, this architecture is detrimental to ultra-low latency AI.
The Interrupt Storm
When a GPU finishes a computation, it sends an interrupt to the CPU. In a virtualized environment, this interrupt must be trapped by the Hypervisor and then injected into the Guest VM. This "Context Switch" adds microseconds of jitter to every single token generation step. For a 500-token response, these microseconds accumulate into perceptible lag.
Memory Translation Overhead
VMs use Second Level Address Translation (SLAT) to map Guest Physical Memory to Host Physical Memory. High-bandwidth transfers between the CPU and GPU (PCIe traffic) suffer from Translation Lookaside Buffer (TLB) misses, causing stalls in the data pipeline.
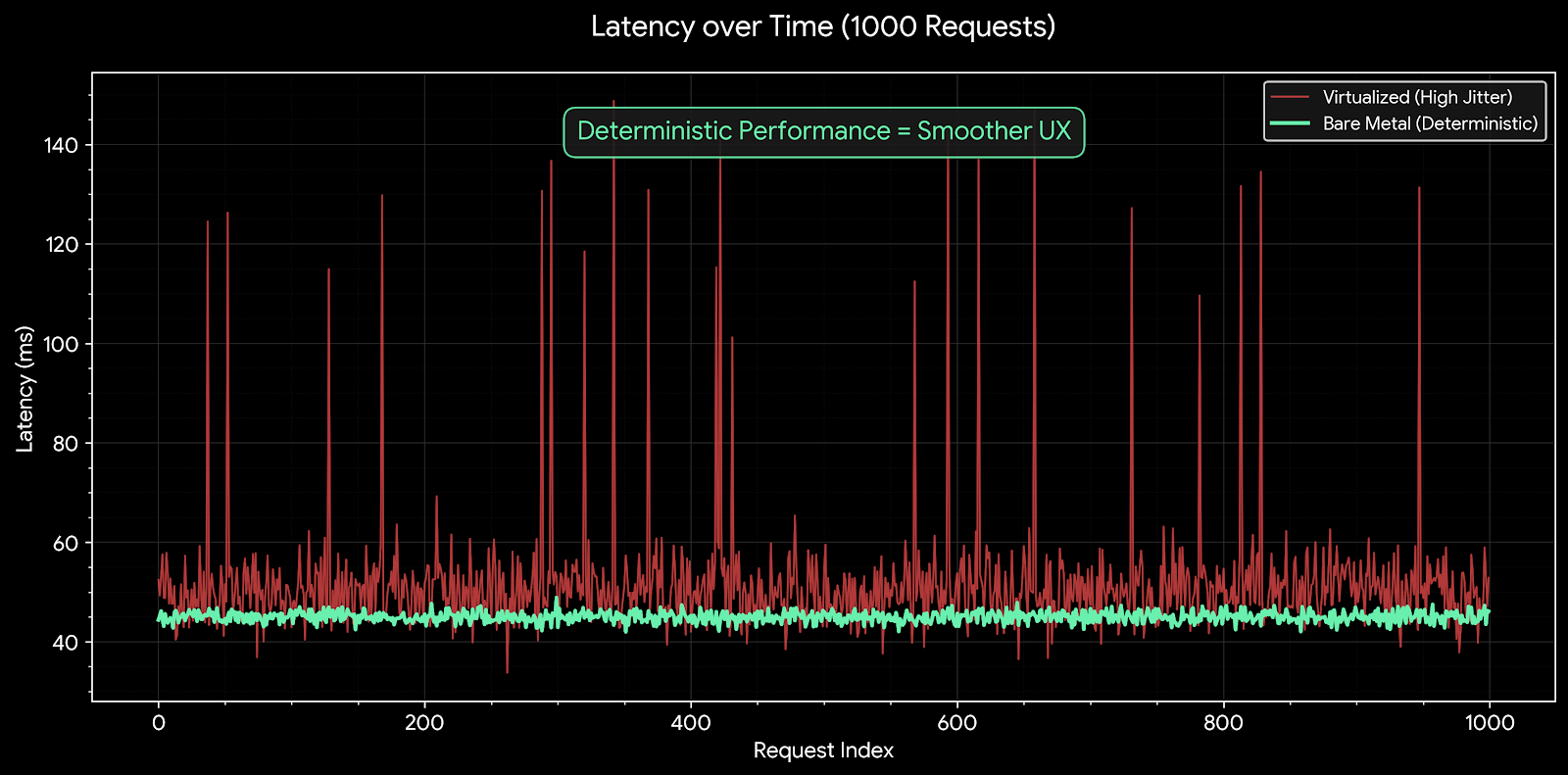
Engineering Fact: GMI Cloud’s Bare Metal architecture removes the Hypervisor entirely. The OS kernel talks directly to the GPU hardware via PCIe Gen5, resulting in Zero Virtualization Jitter and deterministic P99 latency.
Technical Comparison: Latency Benchmarks
The following table compares the latency characteristics of Llama 3 70B inference across different provider architectures.
Table 1: Llama 3 70B Inference Latency (Batch Size 1)
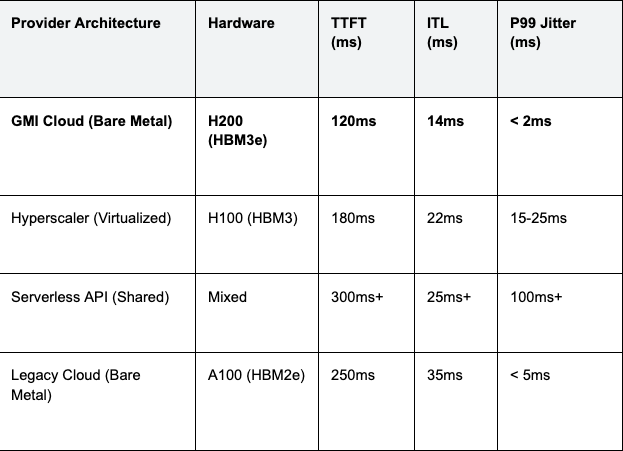
Analysis: The combination of H200 hardware and Bare Metal architecture gives GMI Cloud a 30-40% advantage in raw speed over virtualized H100s, but a massive 10x advantage in stability (Jitter) over shared serverless APIs.
The Role of InfiniBand in Multi-GPU Latency
For open-source models larger than 70B parameters (like DeepSeek V3 671B or Llama 3 405B), the model must be split across multiple GPUs (Tensor Parallelism). In this scenario, the network is the computer.
Every token generation step requires an "All-Reduce" operation where all GPUs synchronize their partial results. If this synchronization happens over standard Ethernet (even 400GbE), the latency penalty is severe due to TCP/IP protocol overhead.
RDMA: The Speed of Light Solution
GMI Cloud connects its H200 clusters with 3.2 Tbps InfiniBand networking, supporting GPUDirect RDMA.
- Bypass Kernel: Data moves directly from GPU memory to the Network Card (NIC) to the remote GPU memory. CPU is not involved.
- Latency: ~1 microsecond per hop (vs 20-50 microseconds for Ethernet).
For a model like DeepSeek V3 running on 8 GPUs, using InfiniBand vs. Ethernet can mean the difference between 40 tokens/second (real-time) and 15 tokens/second (sluggish).
Optimizing the Software Stack for Speed
Hardware provides the potential for speed; software realizes it. GMI Cloud’s Model Library images come pre-configured with the lowest-latency software stack available in 2026.
TensorRT-LLM and CUDA Graphs
We utilize NVIDIA’s TensorRT-LLM backend, which compiles the model computation graph into optimized CUDA kernels. Crucially, we enable CUDA Graphs. This feature captures the sequence of kernel launches and replays them as a single graph, eliminating the CPU launch overhead for every single token step.
# Example: Enabling CUDA Graphs for Low Latency
# This is default on GMI Cloud's pre-built engines
engine_config = {
"use_cuda_graph": True,
"max_batch_size": 1, # Optimized for latency, not throughput
"quantization": "fp8"
}
Speculative Decoding
For applications where latency is the absolute priority, GMI Cloud supports Speculative Decoding. This technique uses a small "Draft Model" (e.g., Llama 3 8B) to guess the next 5 tokens, which are then verified in parallel by the main H200 model. This breaks the serial dependency of LLM generation, potentially doubling the effective token rate.
Case Study: Real-Time Voice Agent
Consider a Voice AI startup building a conversational agent. The total latency budget for a "natural" conversation is 500ms (Voice-to-Text -> LLM -> Text-to-Speech).
- Hyperscaler VM: TTFT varies between 200ms and 400ms due to jitter. This consumes nearly the entire budget, leaving no room for network or speech processing. The result is awkward pauses.
- GMI Cloud Bare Metal H200: TTFT is stable at 120ms. This leaves 380ms for other components, resulting in a fluid, human-like conversation flow.
FAQ: Low Latency Inference
Q: Does geography matter for inference latency?
Yes. Speed of light is a hard limit. Adding 1000km of distance adds ~10-20ms of round-trip network latency. GMI Cloud offers regions in the US and APAC to place compute closer to your users.
Q: Why is batch size important for latency?
Trade-off. Increasing batch size increases Throughput (TPS) but hurts Latency (TTFT) because requests wait in a queue. For the lowest latency, use a Batch Size of 1 on a dedicated Bare Metal GPU.
Q: Can I use FP8 for all models?
Mostly Yes. Modern models like Llama 3 and DeepSeek are robust to FP8 quantization. This reduces memory bandwidth pressure by 50%, directly improving generation speed without noticeable quality loss.
Q: How do I test latency on GMI Cloud?
Use GenAI-Perf. We recommend benchmarking using NVIDIA's GenAI-Perf tool on our On-Demand instances. Measure both TTFT (mean) and TTFT (P99) to see the stability advantage.
What's next
- Deploy a low-latency endpoint using the Model Library.
- Read the H200 Hardware Specs to understand the bandwidth advantage.
- Contact Sales for a Proof of Concept (POC) on Bare Metal.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
