
We sent two prompts, a concept question and a multi-step reasoning problem, to Kimi K2.6, Qwen3.6-Max, DeepSeek-V4-Pro, and GPT-5.5 at the same time via a single GMI Cloud endpoint. All models got the right answer. The real differences showed up in latency, reasoning depth, and cost. Here's the full breakdown.
Why Two Prompts
A single-prompt comparison tells you something. Two prompts start to show you a pattern. We chose prompts that stress-test different model behaviors:
- Test 1, Knowledge/Conciseness: "Explain MoE architecture in 2 sentences." Short expected output, technical topic, tests how well models compress information.
- Test 2, Structured Reasoning: "A company has 3 servers. Each handles 240 requests/min. If traffic spikes 4x, how many servers are needed, assuming linear scaling? Show your reasoning." Tests step-by-step problem solving and whether models add useful context beyond the literal answer.
Each model ran 3 times per prompt. All metrics are the median across those runs. Every call went through https://api.gmi-serving.com/v1, one endpoint, one API key, four models.

The Models
| Model | Provider | License | Output Price/1M |
|---|---|---|---|
| Kimi K2.6 | Moonshot AI | Open Source | $3.60 |
| Qwen3.6-Max-Preview | Alibaba Cloud | Open Source | $7.80 |
| DeepSeek-V4-Pro | DeepSeek | Open Source | $2.784 |
| GPT-5.5 | OpenAI | Proprietary | $30.00 |
Three open-source, one proprietary. That $30 vs $2.784 output price gap matters more the longer these runs get.
Test 1: Explain MoE Architecture in 2 Sentences
| Model | TTFT | TTFA | Total | Tok/s | Out Tokens | Reasoning Toks | Est. Cost |
|---|---|---|---|---|---|---|---|
| Kimi K2.6 | 1,387 ms | 7,272 ms | 8.31s | 49/s | 458 | 479 | $0.0016 |
| Qwen3.6-Max | 2,026 ms | 23,884 ms | 25.52s | 32/s | 816 | 736 | $0.0064 |
| DeepSeek-V4-Pro | 1,784 ms | 5,072 ms | 7.52s | 24/s | 187 | 109 | $0.0005 |
| GPT-5.5 | 1,746 ms | 1,746 ms | 2.56s | 31/s | 90 | 12 | $0.0027 |
Median across 3 runs. TTFT = time to first token of any kind. TTFA = time to first answer token.


GPT-5.5 answered in 2.56 seconds total. It barely reasoned (12 reasoning tokens) before writing. Clean, accurate, thin. Kimi K2.6 spent 479 reasoning tokens on a 2-sentence question, which sounds excessive until you read the output: it was the most technically precise of the four. DeepSeek-V4-Pro was the cost winner at $0.0005, delivering a solid answer in 7.5 seconds. Qwen3.6-Max took 25 seconds because its thinking mode ran 736 reasoning tokens, by far the deepest reasoning for this prompt, and the most expensive at $0.0064.
All four answers were factually correct on MoE. The variation was in depth and framing, not accuracy.
Test 2: Multi-Step Reasoning Problem
| Model | TTFT | TTFA | Total | Tok/s | Out Tokens | Reasoning Toks | Est. Cost |
|---|---|---|---|---|---|---|---|
| Kimi K2.6 | 1,664 ms | 7,804 ms | 10.95s | 45/s | 536 | 327 | $0.0019 |
| Qwen3.6-Max | 2,382 ms | 28,239 ms | 35.00s | 35/s | 1,153 | 892 | $0.0090 |
| DeepSeek-V4-Pro | 1,397 ms | 8,935 ms | 15.27s | 28/s | 427 | 209 | $0.0012 |
| GPT-5.5 | 2,575 ms | 2,575 ms | 3.33s | 46/s | 159 | 61 | $0.0048 |
Median across 3 runs.
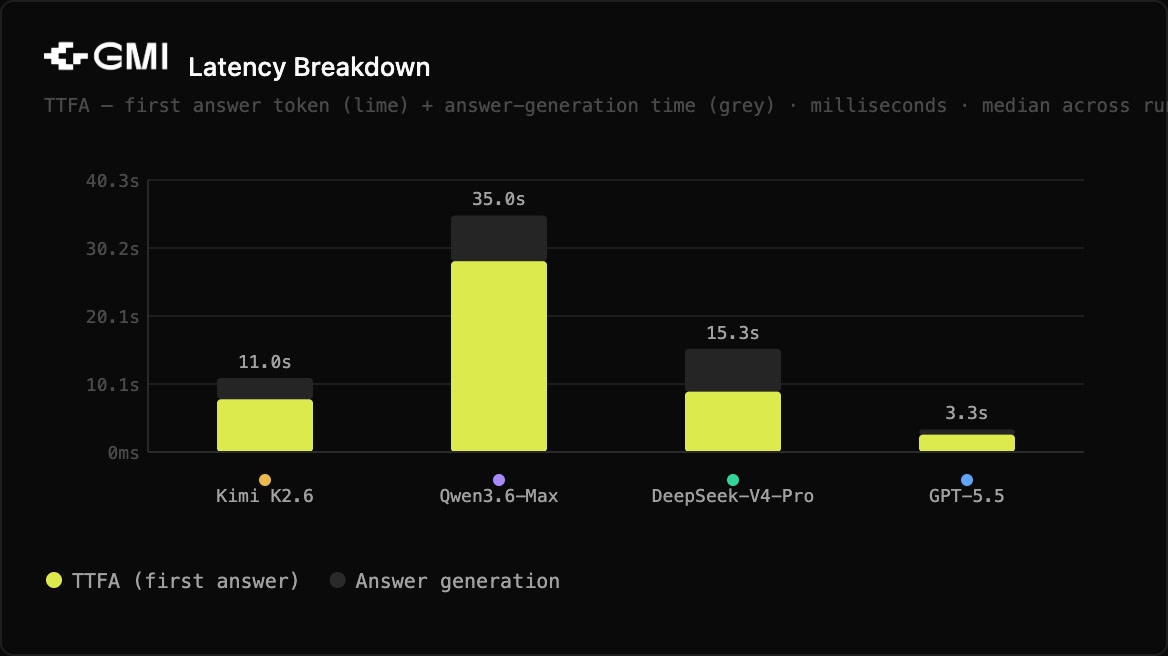
Every model got 12 servers as the correct answer. The differences were in how they showed the work, and one model went meaningfully beyond the question.
GPT-5.5 was again the fastest (3.33s TTFA), but it did something no other model did: it calculated how many additional servers were needed (9), not just the total. That's a small but real signal of contextual reasoning. The model inferred what a person actually asking this question would want to know.
Kimi K2.6 gave the cleanest structured breakdown: numbered steps, a shortcut verification method, concise. Took 10.95 seconds. Cost $0.0019.
DeepSeek-V4-Pro was the most direct. Three sentences, correct answer, done, at $0.0012. Fastest TTFT of the group at 1,397ms. For applications where you need the right answer fast and cheaply, this is the efficiency leader.
Qwen3.6-Max produced the most thorough reasoning (892 reasoning tokens, 1,153 total output tokens) and added a caveat about real-world assumptions (load distribution, no overhead, sustainable capacity). That's useful context for an engineer, but it took 35 seconds and cost $0.0090, the highest of any model in either test.
The Speed vs. Cost Picture
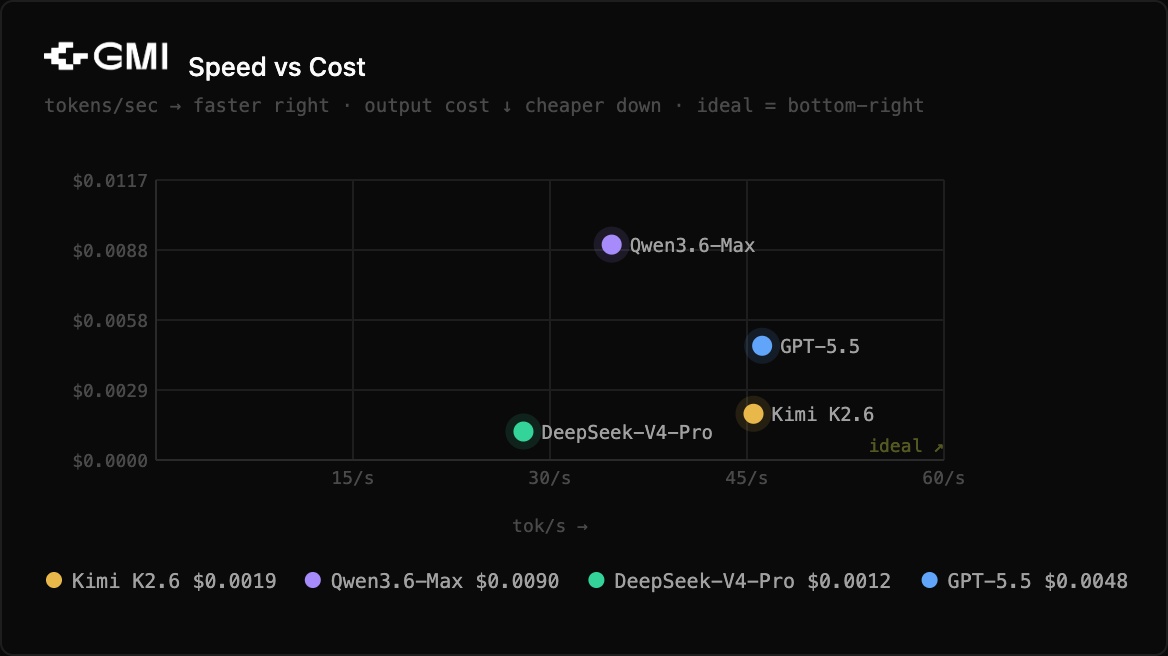
The scatter chart tells the full story. The bottom-right corner is the ideal zone: fast and cheap. Here's where each model lands across both tests:
- Kimi K2.6 sits in the upper-right cluster. Fast throughput (45 to 49 tok/s), mid-cost. Good speed, not the cheapest.
- DeepSeek-V4-Pro is bottom-center. Slowest throughput but consistently the cheapest. If cost is the primary constraint, this is your model.
- GPT-5.5 lands right-center. Fast at 46 tok/s with a TTFA under 3.5 seconds in both tests. But at $30/M output tokens, it costs 10x more per token than DeepSeek-V4-Pro.
- Qwen3.6-Max is upper-left. Slowest to first answer (28 seconds on Test 2), highest cost per run. The depth of reasoning is real, but the latency profile rules it out for anything interactive.
What Each Model Actually Produced
This matters more than the numbers for most builders. The same question, four genuinely different approaches.
Kimi K2.6 wrote structured, numbered reasoning with a shortcut verification at the end. Dense, efficient, developer-friendly formatting. Best if you want structured outputs by default without a system prompt.
Qwen3.6-Max added an engineering caveat (load distribution assumptions) that nobody asked for, but that an experienced SRE would immediately think about. If your use case involves generating documentation or technical explanations where completeness matters more than speed, this depth is valuable.
DeepSeek-V4-Pro gave three clear sentences and the right answer. No extra framing, no caveats. For automated pipelines where the output feeds into another process rather than being read by a human, this is exactly what you want.
GPT-5.5 answered the literal question and inferred a follow-up (how many additional servers to add). That inference was not in the prompt. It's a sign of the model treating the question as a task rather than a fill-in-the-blank exercise.
Cross-Test Patterns
A few things held consistent across both prompts.
GPT-5.5's TTFA advantage is real and repeatable. 1,746ms in Test 1, 2,575ms in Test 2. Everything else was in the 5,000 to 28,000ms range for TTFA. If user-facing latency is a hard requirement, nothing else in this test comes close.
Qwen3.6-Max's thinking overhead scales with problem complexity. 736 reasoning tokens on the concept question, 892 on the math problem. Its TTFA went from 24 seconds to 28 seconds as the task got harder. That's predictable behavior, but you should design around it. Don't use this model in a real-time chat context.
DeepSeek-V4-Pro's cost advantage compounds. $0.0005 in Test 1, $0.0012 in Test 2. Compare that to GPT-5.5 at $0.0027 and $0.0048 for the same two prompts. At scale, millions of calls per day, that difference becomes significant budget.
Kimi K2.6 is the most consistent all-rounder. Not the fastest, not the cheapest, but it delivered the best formatting by default, the highest throughput in Test 1 (49 tok/s), and competitive quality in both tests. For agentic or coding workloads where output structure matters, it has a real edge.
Quick Reference
| Need | Pick |
|---|---|
| Fastest response, user-facing product | GPT-5.5 |
| Scale at minimum cost | DeepSeek-V4-Pro |
| Best structured output and throughput | Kimi K2.6 |
| Maximum reasoning depth, latency-tolerant | Qwen3.6-Max |
One More Thing
All of this ran from one endpoint. Switching between these four models was a one-line change in the request body. No different SDKs, no different auth flows, no re-architecting your client code. That's not a small thing when you're building a system that needs to route different task types to different models based on cost, latency, or quality thresholds. It's the whole premise of using a unified inference layer.
Tests run May 12, 2026. All models called via https://api.gmi-serving.com/v1. Metrics are median across 3 runs per model per prompt. No system prompt, no temperature set, stream_options.include_usage = true.
Roan Weigert
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
