The Hidden Costs of Running AI Models in Production (and How to Reduce Them)
April 24, 2026

Running AI models in production involves significant hidden costs that can derail budgets, but strategic optimization can reduce expenses by 40-80% while maintaining performance.
- Hidden costs dominate AI budgets: Idle infrastructure burns $500-$23,000 monthly, while model retraining and compliance overhead often exceed initial hardware investments.
- Right-size models for maximum ROI: Most business tasks don't need frontier models, a 7B parameter model achieving 92% accuracy costs significantly less than GPT-4's marginal 3% improvement.
- Start with cloud APIs before building infrastructure: Pre-trained models and fine-tuning cost 10-15% of custom development while achieving 85-95% of performance.
- Implement compression and automation: Model optimization techniques like quantization and pruning can reduce computing costs by 40-80% with negligible accuracy loss.
- Monitor usage in real-time: Automated scaling and resource tracking prevent the idle infrastructure waste that catches 70% of organizations off guard.
The key to sustainable AI deployment is balancing performance requirements with cost optimization, understanding that the most expensive model isn't always the most effective for your specific use case.
The cost of generative AI is climbing faster than most organizations predicted, with average computing expenses expected to surge 89% between 2023 and 2025. Generative AI serves as a critical driver of this increase according to 70% of executives. Every executive surveyed has canceled or postponed at least one AI initiative due to cost concerns.
How much does AI cost to run? The question goes beyond obvious hardware expenses. Hidden factors like idle infrastructure and poor resource use often catch teams off guard. Operational overhead adds another layer of complexity. Is AI expensive to run? The answer depends on how well you manage both visible and concealed expenses.
This piece breaks down the real AI development cost components and shows you practical strategies to optimize your AI infrastructure spending.
The Real Cost of Running AI Models in Production
Hardware investments are the foundations of AI infrastructure expenses. A single NVIDIA H200 NVL GPU costs over $25,000, while an 8x H200 NVL server configuration runs upwards of hundreds of thousands of dollars. The financial burden extends beyond original procurement, since the amortized hardware and energy cost for frontier models has grown at a rate of 2.4x per year since 2016. Hardware and interconnect components make up 47-67% of total development costs, with R&D staff accounting for 29-49% and energy consumption representing 2-6%.
Infrastructure and hardware expenses
Production-ready AI infrastructure requires substantial capital allocation. High-performance GPUs like NVIDIA A100 or H100 can cost $25,000-$40,000 each, and clusters easily reach millions in total investment. Beyond GPU procurement, organizations must budget for high-speed networking infrastructure such as InfiniBand or NVLink and advanced cooling systems. Storage solutions that can handle petabyte-scale datasets add to the cost. GMI Cloud provides flexible infrastructure options that help teams right-size their GPU resources based on actual workload requirements, avoiding unnecessary upfront investment.
Energy consumption and cooling costs
Power consumption drives ongoing operational expenses at scale. A single H200 GPU consumes 600W of power, while an 8x GPU server node can draw 5-7kW or more under full load. Large model training amplifies these costs. GPT-3's training run consumed approximately 1,287 megawatt-hours of electricity, equivalent to the annual consumption of over 120 average US homes. Cooling systems compound the problem and contribute to over half of the total energy usage in data centers. Heat densities increase with newer GPU generations. Liquid cooling solutions become essential and add another layer of infrastructure investment and operational complexity.
Personnel and maintenance requirements
Specialized talent represents a major ongoing expense that often exceeds hardware costs. AI at scale requires ML engineers, DevOps specialists and MLOps experts whose salaries surpass hardware expenditures. Organizations must budget 10-15% annually for hardware repairs and upgrades, while teams require constant training to keep pace with tooling and best practices that evolve faster.
Storage and data transfer fees
Data management costs accumulate across AI operations. API request fees emerge when storage platforms ingest data from external sources. Moving a terabyte can trigger tens of thousands of individual charges. Egress fees apply when data exits storage to reach AI solutions, which is problematic for iterative training workflows. Cross-regional data transfers add another expense layer, with AWS charging $0.09 per gigabyte for processing data across regions.
Hidden Costs That Catch Organizations Off Guard
Beyond upfront expenses, several operational costs emerge that few teams anticipate during planning phases.
Model update and retraining expenses
Retraining creates an unavoidable trade-off between model freshness and computing costs. Training new models can cost millions of dollars and emit hundreds of tons of CO2. Organizations face two competing expenses: model staleness cost (performance loss from outdated training data) and model retraining cost (resources spent training on new data). Too frequent retraining guides teams toward unnecessary computing expenses, while infrequent updates result in stale models with degraded performance. Only about 10% of AI R&D spending goes toward final training runs. The majority gets allocated to scaling, synthetic data generation and research.
Idle infrastructure and resource waste
Idle AI endpoints burn $500 to $23,000 monthly and often go unnoticed for weeks. A SageMaker GPU endpoint can exceed $1,000 per month. Vertex AI endpoints with high-memory accelerators reach $23,000 monthly while sitting idle. These endpoints never scale to zero. Billing continues at full price even with zero traffic. GPU utilization for AI inference workloads hovers around 20-40%, substantially lower than training tasks. On-prem AI clusters often run below 15% utilization. Modern AI nodes idle at roughly 25-45% of peak power, which means a 25kW rack can still burn 8-10kW doing nothing.
Compliance and security overhead
Security controls around Gen-AI models add substantial costs beyond licensing fees. Fine-tuning models using enterprise data runs expensive, with costs depending on parameters tuned and training iterations. Security assessments, vulnerability testing and re-deploying AI tools consume high costs for talent and infrastructure. Organizations implementing Gen-AI need five layers of protection across data, model, user, application and perimeter layers.
Operational complexity and downtime
Unplanned downtime costs manufacturers $50 billion annually in the U.S.. Therefore, 83% of industry leaders confirm a single hour of downtime costs at least $100,000, with many reporting costs above $500,000 per hour. GMI Cloud helps teams optimize resource allocation and reduce operational risk by improving infrastructure efficiency and minimizing downtime across AI workloads.
How to Reduce AI Infrastructure Costs
Reducing AI infrastructure expenses just needs strategic decisions in model selection, deployment architecture and operational practices.
Right-size your models for the task
Frontier model capabilities aren't necessary for most business tasks. Models with a fraction of GPT-4's parameters can handle document classification, customer service routing and data extraction. A 7B parameter model might achieve 92% accuracy on your specific task while GPT-5 achieves 95%. The marginal improvement rarely justifies the exponential increase in cost and complexity. Running a 7B model locally might cost $0.00 per query versus $0.02-0.06 for GPT-4 API calls. This translates to millions in annual savings at enterprise scale. Strategic AI model selection can prevent 40% lower accuracy and 60% higher operational expenses compared to optimal model choices.
Use hybrid cloud and multi-environment strategies
Hybrid cloud environments combine on-premise and cloud resources. This provides flexibility and scalability. 68% of hybrid cloud adopters have already established formal, organization-wide policies to direct their approach to generative AI. AI-powered workload distribution in hybrid clouds will make tasks run in the most cost-effective locations. The system considers latency, cost and availability. Organizations can achieve cost savings by adjusting resource allocation based on demand and predictive analytics dynamically.
Implement model optimization techniques
Model compression addresses computational requirements while maintaining accuracy. Pruning removes redundant parameters and creates sparse, lightweight models that just need less computation and memory. Quantization reduces precision from 32-bit floating-point to 8-bit integers or lower. This substantially decreases memory footprint. Knowledge distillation compresses large teacher models into smaller student models without substantial performance loss. Combining multiple compression techniques can reduce FLOPs by over 50% with negligible accuracy loss. Model compression can reduce cloud computing costs by 40 to 80%.
Automate resource allocation and scaling
Scaling to zero will make you pay only for what you use when resources are idle. Organizations can save thousands monthly by scaling down unused resources automatically. Providence saved $2 million in 10 months using AI for cloud management.
Monitor and track usage immediately
Prometheus and Grafana collect and visualize metrics from servers and distributed systems. Tools like MLflow track experiments and training metrics. Production monitoring tools detect data drift and model performance degradation. GMI Cloud provides built-in infrastructure capabilities that help teams track and optimize GPU utilization, making it easier to identify inefficiencies and reduce waste.
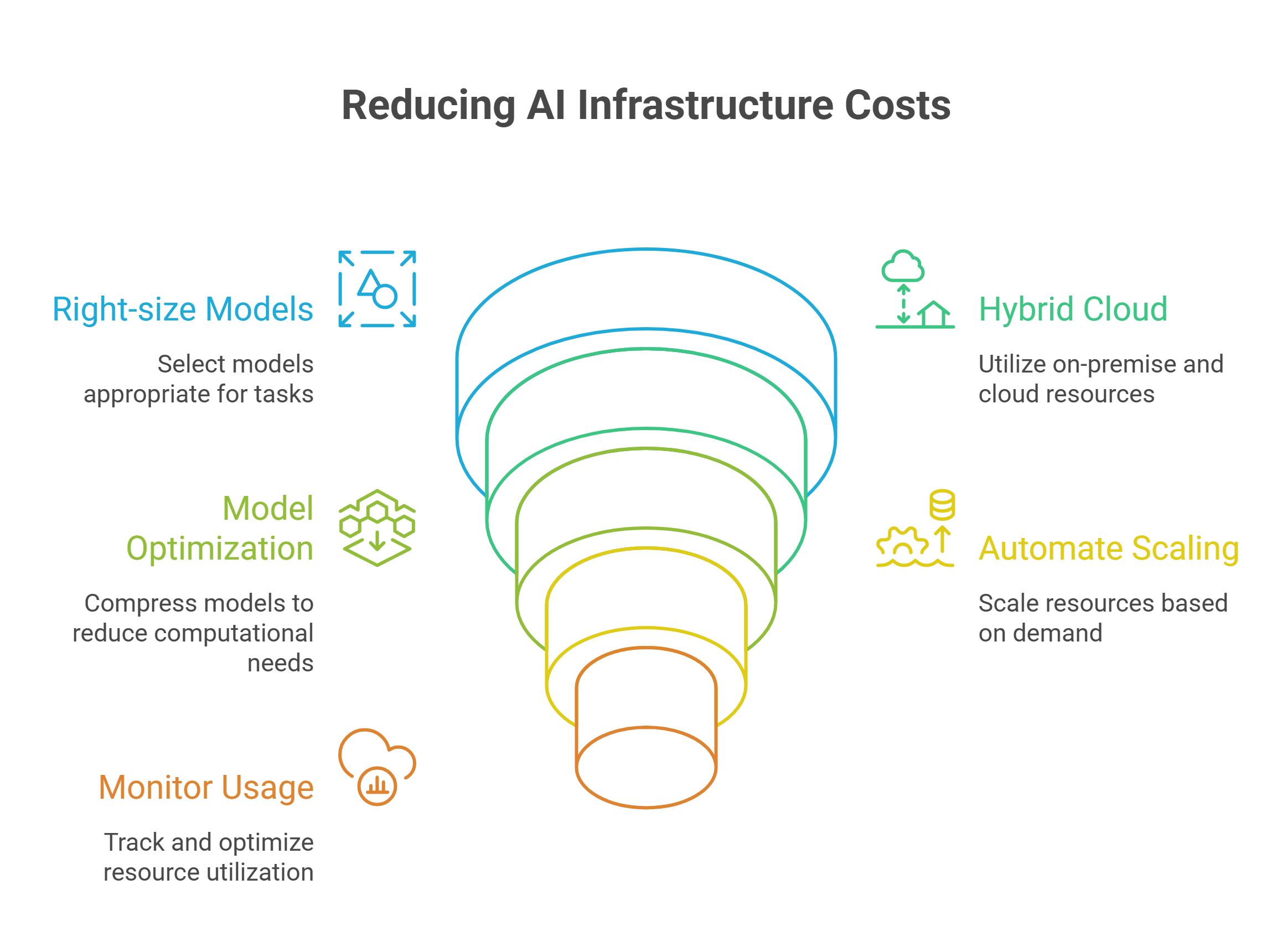
Cost-Effective Deployment Strategies for AI Models
Deployment choices determine whether AI initiatives remain financially sustainable or spiral into budget overruns.
Start with cloud APIs before building local infrastructure
Cloud AI provides access to pre-built APIs and SDKs. You get ready-to-deploy models without building costly systems from scratch. These solutions improve time to market and reduce what could be months of testing into a few short weeks. Hyperscalers offer flexible pricing models that allow businesses to handle everything from experiments to large-scale deployments on a pay-as-you-go basis. Cloud deployment prioritizes scalability and speed. This makes it the simplest starting point for teams deploying models through APIs without managing infrastructure. In stark comparison to this, cloud costs can jump faster with heavy volume, while on-premise often becomes more budget-friendly at scale.
Choose the right deployment model for your use case
Serverless GPU inference suits experimentation and unpredictable bursts, with costs accumulating only when models run. Dedicated clusters provide consistent latency for steady workloads. Analyzes show eight GPUs costing $1.60M on demand versus $250k when dedicated over five years. GMI Cloud offers infrastructure that adapts to different deployment patterns, from bursty serverless inference workloads to fully dedicated GPU clusters.
Utilize pre-trained models and fine-tuning
Pre-trained models typically cost 10-15% of developing comparable custom solutions. Transfer learning reduces enterprise AI costs dramatically and cuts development time from months to weeks while achieving 85-95% of custom model performance. Fine-tuning costs typically range from $50,000 to $300,000, by a lot less than building from scratch. About 56% of companies now use hybrid approaches and invest in custom capabilities only for their most critical applications.
Conclusion
You need to understand both visible expenses and hidden budget drains to control AI infrastructure costs. Start with right-sized models and cloud APIs before you commit to expensive infrastructure. Implement optimization techniques like quantization and automated scaling as your needs grow. These keep costs in check. GMI Cloud provides flexible infrastructure that adapts to your requirements, helping teams balance performance, scalability, and cost more effectively.
FAQs
What are the main hidden costs of running AI models in production?
The primary hidden costs include idle infrastructure that can burn $500-$23,000 monthly even with zero traffic, model retraining expenses that can reach millions of dollars, compliance and security overhead requiring multiple protection layers, and operational downtime that costs manufacturers $50 billion annually in the U.S. Additionally, GPU utilization often hovers around only 20-40%, meaning organizations pay for resources they're not fully using.
How much does it actually cost to run AI infrastructure at scale?
AI infrastructure costs vary significantly based on deployment choices. A single NVIDIA H200 GPU costs over $25,000, while an 8-GPU server configuration can run hundreds of thousands of dollars. Beyond hardware, energy consumption is substantial, GPT-3's training consumed approximately 1,287 megawatt-hours of electricity. Personnel costs often exceed hardware expenses, with specialized ML engineers and DevOps specialists commanding premium salaries. Computing expenses are expected to surge 89% between 2023 and 2025.
Should I build my own AI infrastructure or use cloud APIs?
Starting with cloud APIs is generally more cost-effective before committing to local infrastructure. Cloud solutions offer pre-built models, flexible pay-as-you-go pricing, and faster time to market, reducing deployment from months to weeks. Implementing pre-trained models typically costs only 10-15% of developing custom solutions while achieving 85-95% of performance. However, for high-volume, steady workloads, dedicated infrastructure can become more economical at scale.
How can I reduce AI model operating costs without sacrificing performance?
You can reduce costs by 40-80% through several strategies: right-sizing models for specific tasks (a 7B parameter model often suffices instead of GPT-4), implementing model compression techniques like quantization and pruning, automating resource allocation to scale down unused resources, and using hybrid cloud strategies. Most business tasks don't require frontier model capabilities, and choosing appropriately-sized models can save millions annually at enterprise scale.
What is the real difference between open-source and closed AI models in terms of costs?
While open-source AI models offer free access to model weights, the real costs emerge during deployment. Running these models at scale requires massive compute resources, substantial electricity, and proper cloud infrastructure, investments that take years to establish. True control in AI belongs to whoever owns the data centers and power supply, not just whoever releases the weights. Unlike traditional open-source software that could run on regular laptops, modern AI models are too complex and resource-intensive for casual deployment.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
