We Built a 3D Space Game with GLM-5.1. Here's What It Revealed About Agentic Coding
April 21, 2026

What does it actually look like when an AI model builds a complete application? Not a snippet. A full, running, interactive piece of software with game physics, a custom audio engine, particle explosions, post-processing shaders, and a working HUD.
We decided to find out. The result is GMI Inference Universe, a browser-based 3D space game built entirely by GLM-5.1, the latest open-weight flagship model from Z.AI. The build process taught us more about the current state of agentic coding than any benchmark table alone could.

Why GLM-5.1?
GLM-5.1 is Z.ai's next-generation flagship model for agentic engineering, built specifically for long-horizon coding tasks with significantly stronger capabilities than its predecessor GLM-5.
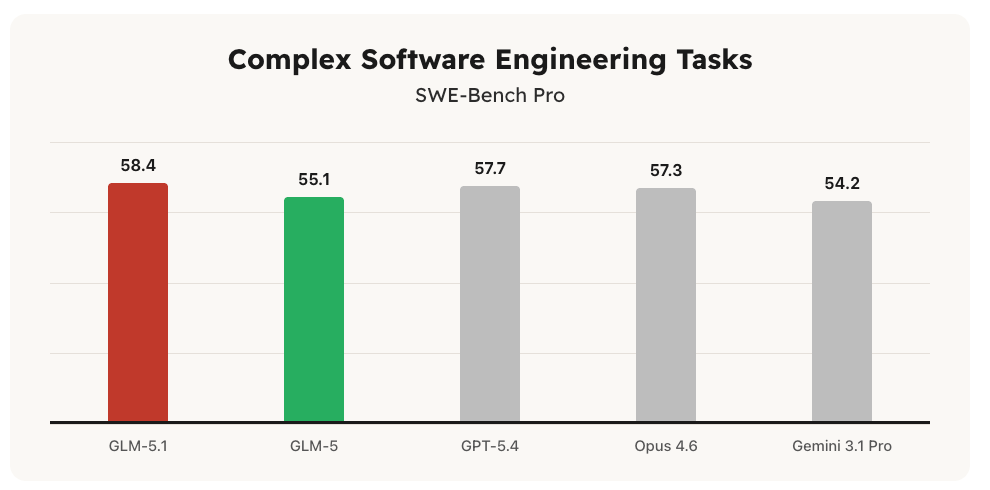
On SWE-Bench Pro, GLM-5.1 scores 58.4, outperforming GPT-5.4 (57.7), Claude Opus 4.6 (57.3), GLM-5 (55.1), and Gemini 3.1 Pro (54.2). It leads its predecessor by a wide margin and sits at the top of Z.ai's SWE-Bench Pro evaluation across all tested models. The model is open-weight and released under the MIT license, making it the strongest openly available model on this benchmark. Source: z.ai/blog/glm-5.1
GLM-5.1 also leads GLM-5 by a wide margin on NL2Repo (repo generation from natural language specs) and Terminal-Bench 2.0 (real-world terminal tasks). On KernelBench Level 3, it achieves a 3.6x geometric mean speedup on real machine learning workloads, significantly surpassing the 1.49x achieved by torch.compile in max-autotune mode. Source: docs.z.ai/guides/llm/glm-5.1
The model's design orientation matters here. It was built specifically for long-horizon agentic tasks. In Z.ai's own evaluation, it ran 655 iterations on a vector search problem to reach 21.5k QPS, and spent 8 hours building a functional Linux desktop from a single natural language prompt, autonomously planning, executing, and iterating across more than 1,200 steps. This model was designed for agentic engineering, not general-purpose chat.
The Game
GMI Inference Universe turns the AI inference landscape into something you can fly through.
gave GLM-5.1 one goal:
— Roan Weigert (@roangws) April 21, 2026
build a browser 3D space game where AI inference providers are planets, it shipped:
- 6-axis flight controls
- laser bolts + explosions
- real benchmark data on each planet
- procedural audio engine
- full game loop
Powered by @gmi_cloud pic.twitter.com/jNHDOeo5h2
Gameplay features include full 6-axis flight simulator controls (W/S throttle and reverse, A/D roll, arrow keys for yaw, Q/E pitch), laser bolts on Spacebar that destroy planets in 3 hits triggering a mega explosion for +50 score, collectible Token Orbs near each planet, a live HUD with throttle level and ship coordinates, and a procedural audio engine with engine hum that scales with throttle speed. The entire 3D scene runs on Three.js with a post-processing pipeline including bloom and vignette.
What Building It Revealed
The development process was iterative and debugged step by step. GLM-5.1 held a complex multi-system architecture in context across long sessions. Here is what the build taught us.
GLM-5.1's strength lies in staying oriented across hundreds of iterations. The model performed best when given explicit, numbered fix sequences rather than vague instructions. When prompts were specific and sequential, the model converged reliably. This matches its design: the model plans, executes, and identifies blockers through sustained iterative reasoning rather than single-turn generation.
The planets are rendered as grey or nearly invisible under the dark ambient lighting of the space environment when using MeshStandardMaterial or MeshPhysicalMaterial. The fix required switching to MeshBasicMaterial, which renders color independent of scene lighting. The model had to understand the cause of the bug, not just its symptom. This is precisely the category of situated engineering judgment that SWE-Bench Pro is designed to evaluate.
A known characteristic of GLM-5.1 is that it sometimes produces code or structured output where a plain text answer would suffice, because its post-training reinforced coding behavior so strongly. In a pure code-generation context like this project, that tendency is an asset: the model stays in execution mode rather than explanation mode.
The 3D scene architecture, ship physics, planet hit detection, audio engine, particle systems, and game loop were all generated and debugged by GLM-5.1. This is what agentic coding looks like in practice: not a single impressive generation, but sustained, correctable, goal-directed engineering across a complete software system.
Running GLM-5.1 on GMI Cloud
GLM-5.1 is available for deployment on GMI Cloud via serverless inference or dedicated endpoints at console.gmicloud.ai. The API is OpenAI-compatible, so existing tooling works without changes:
curl --request POST \
--url https://api.gmi-serving.com/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer *************' \
--data '{
"model": "zai-org/GLM-5.1-FP8",
"messages": [
{"role": "system", "content": "You are a knowledgeable AI assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement in simple terms."}
],
"temperature": 0.7,
"max_tokens": 800
}'
Try It Yourself
To run GLM-5.1 against your own agentic coding workflow, start at the GMI Cloud Console.
Join the conversation on Discord at discord.gg/mbYhCJSbF6 or tag us on X @gmi_cloud.
Academic References
- Yang, J., et al. (2024). "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" arXiv preprint arXiv:2310.06770. The foundational paper for the SWE-Bench benchmark family used to evaluate GLM-5.1's software engineering capabilities. Available at: https://arxiv.org/abs/2310.06770
- Hamari, J., Koivisto, J., & Sarsa, H. (2014). "Does Gamification Work? A Literature Review of Empirical Studies on Gamification." Proceedings of the 47th Hawaii International Conference on System Sciences, pp. 3025-3034. IEEE. The most-cited academic review of gamification effectiveness, directly applicable to using interactive experiences to communicate technical data in developer engagement contexts.
Roan Weigert
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
