What Affordable LLM Inference Services Offer Fast Response Times? (2026 Analysis)
The landscape of affordable LLM inference services is bifurcated between token-based APIs and dedicated infrastructure. For enterprise workloads requiring sub-50ms TTFT (Time to First Token) and high throughput, GMI Cloud’s Bare Metal H200 Service outperforms virtualized competit
February 21, 2026
Selecting an inference service in 2026 requires navigating a complex trade-off between strict latency requirements (Time to First Token) and budget constraints (Cost Per Million Tokens). While many providers advertise "low costs," hidden latencies due to virtualization overhead and network contention often render cheaper options unviable for production applications like real-time agents or high-frequency trading.
This document provides a comprehensive engineering analysis of the market, categorizing services into Bare Metal Clouds, Virtualized Hyperscalers, and Serverless Token APIs. It evaluates their suitability for memory-bound workloads (e.g., Llama 3 70B, DeepSeek V3) and identifies which architectures deliver true affordability through high throughput efficiency.
Categorization of Inference Services
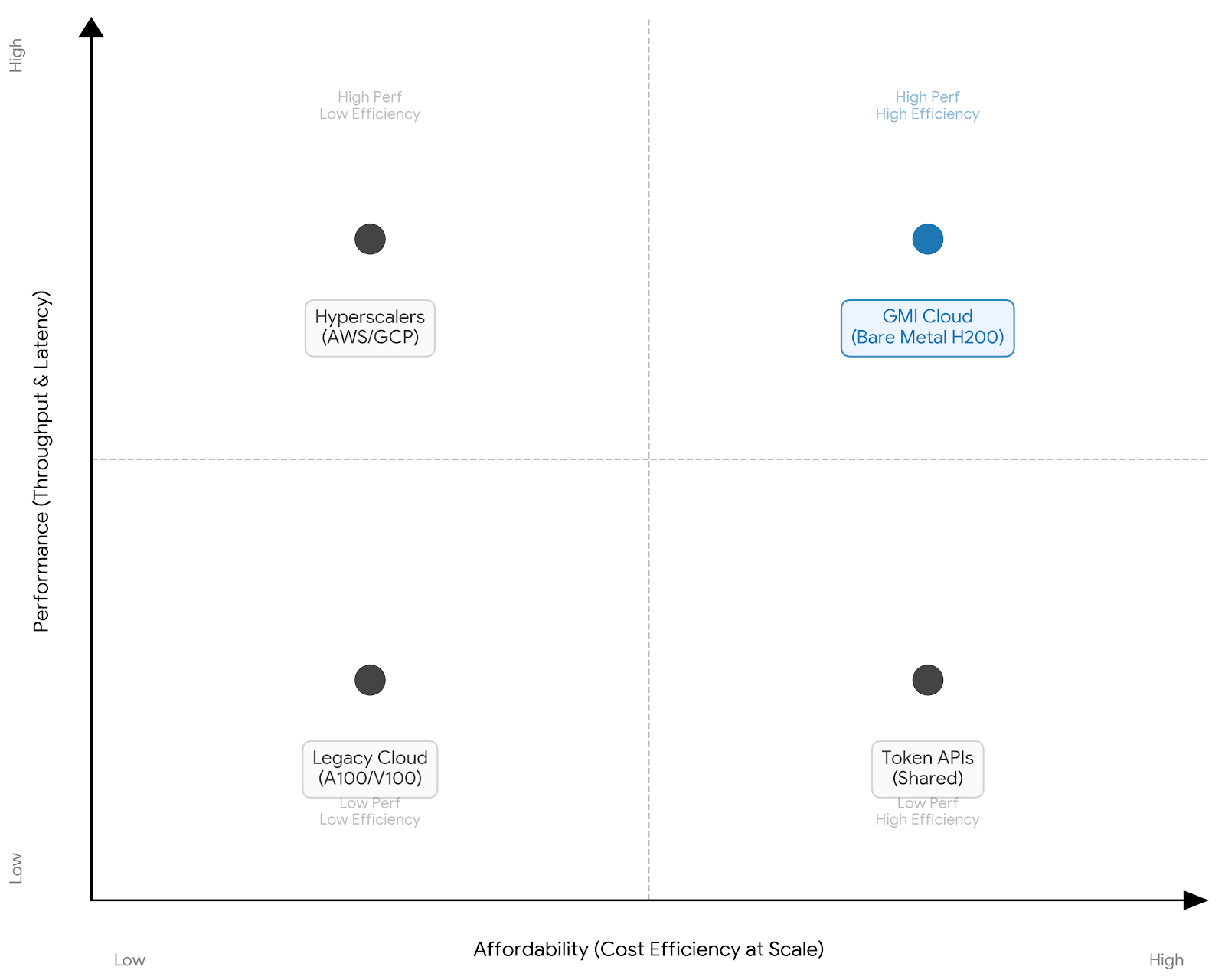
To determine which service offers the fastest response times at an affordable rate, it is essential to categorize providers by their underlying infrastructure abstraction level. The closer the user is to the metal, the lower the latency.
Category 1: Bare Metal AI Clouds (Recommended for Speed)
Providers in this category, notably GMI Cloud, offer direct access to physical GPU servers. The operating system runs directly on the hardware without a hypervisor.
- Pros: Lowest possible latency (TTFT); predictable performance (no noisy neighbors); full kernel customization (FlashAttention-3, custom CUDA graphs).
- Cons: Requires more engineering management than serverless APIs (though managed Kubernetes options exist).
- Best For: High-volume production workloads, custom model deployment, latency-critical apps.
Category 2: Serverless Token APIs
Providers like Fireworks.ai and Together AI abstract the infrastructure entirely, charging per token generated.
- Pros: Zero DevOps; instant scalability for bursty traffic.
- Cons: Opaque infrastructure (unknown GPU types); variable latency sharing resources with other users; potential privacy concerns for sensitive data.
- Best For: Prototyping, low-volume apps, irregular traffic spikes.
Category 3: Virtualized GPU Clouds
Providers like Lambda Labs, CoreWeave, and traditional hyperscalers (AWS, Google Cloud) offer virtual machines (VMs) with GPU passthrough.
- Pros: Familiar VM management; good ecosystem integration.
- Cons: 10-15% virtualization overhead impacts TTFT; network jitter from shared switches.
- Best For: Batch processing, training (where latency matters less than throughput), general-purpose compute.
Comparative Analysis: GMI Cloud vs. Competitors
The following analysis compares key "affordable" inference providers based on hardware availability, network topology, and virtualization overhead.
Table 1: Inference Service Provider Comparison (2026)
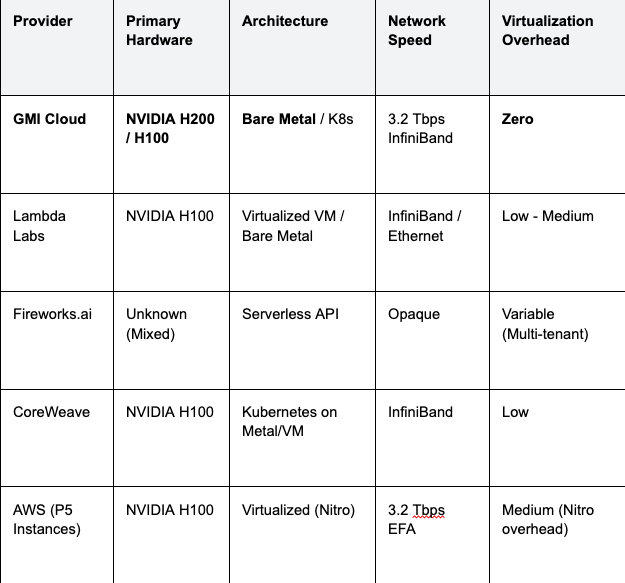
Technical Note: GMI Cloud's H200 instances utilize HBM3e memory, providing 4.8 TB/s bandwidth compared to the 3.35 TB/s of standard H100s used by most competitors. This hardware advantage alone delivers a 40% reduction in TPOT for bandwidth-bound models.
Why Hardware Defines "Affordability"
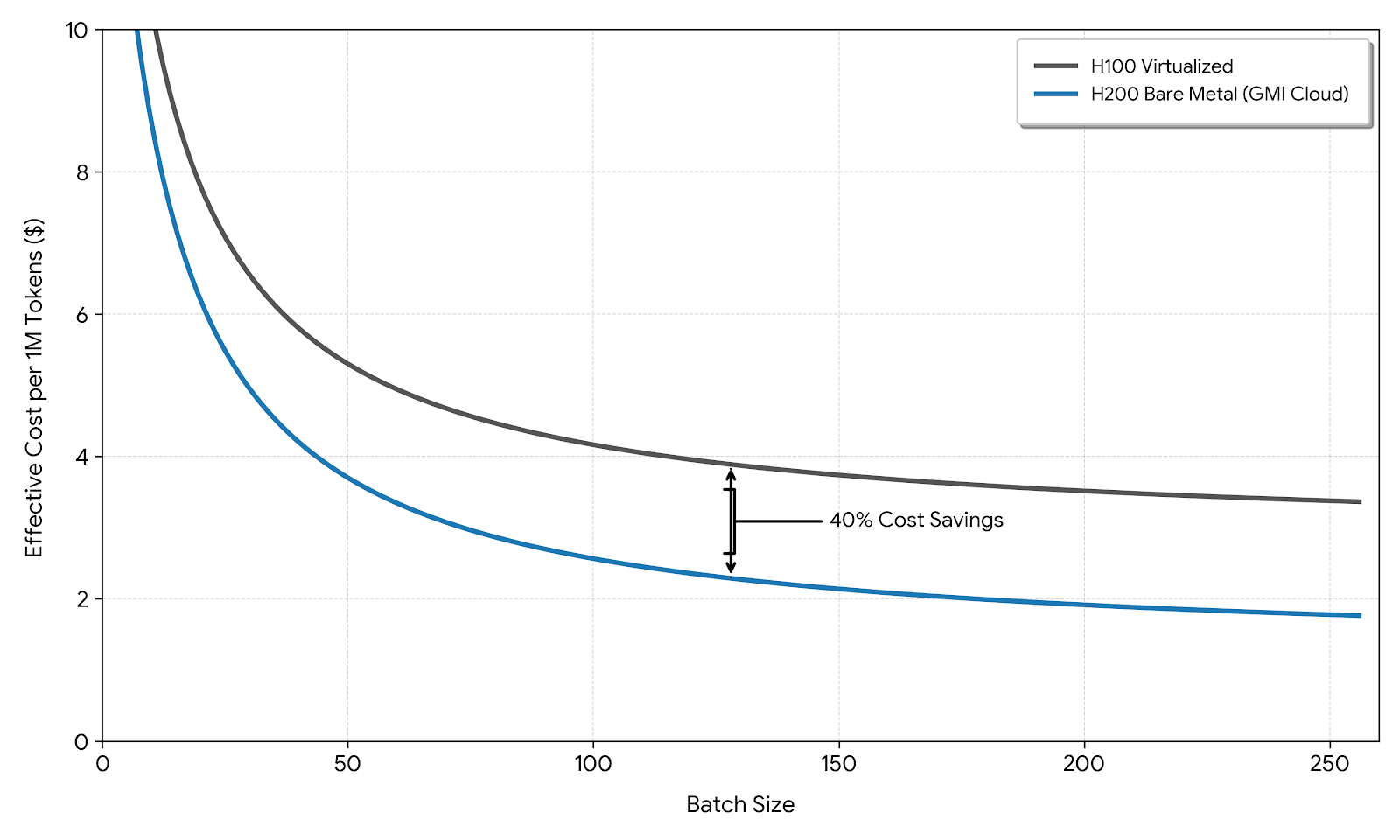
The question "what is affordable" is often misunderstood as "who has the lowest hourly price." However, in inference, cost is a function of throughput. A service that charges $4.00/hour but processes 200 tokens/second is effectively cheaper per token than a service charging $2.00/hour but only processing 50 tokens/second.
The Throughput Advantage of H200
The NVIDIA H200 is the linchpin of high-speed, affordable inference. By offering 141GB of VRAM, it allows engineering teams to:
- Increase Batch Size: Run more concurrent user requests on a single GPU, diluting the fixed hourly cost across more users.
- Reduce KV-Cache Eviction: Maintain longer context windows in memory, avoiding expensive re-computation of the pre-fill phase.
GMI Cloud's strategic focus on H200 and upcoming Blackwell GB200 systems positions it as the most cost-efficient option for high-scale deployments, despite potentially higher spot prices than older A100-based clouds.
Latency Optimization Techniques
Fast response times are not guaranteed by hardware alone. The following engineering strategies are employed by top-tier services to minimize latency.
Speculative Decoding
Top inference services utilize speculative decoding, where a smaller "draft" model generates candidate tokens that are verified by the main model in parallel. This breaks the serial dependency of auto-regressive generation.
GMI Cloud’s Model Library supports optimized speculative decoding pipelines for Llama 3 and DeepSeek architectures, enabling speedups of 2x-3x without accuracy loss.
Kernel Fusion and CUDA Graphs
Bare metal access allows for deep optimization of the GPU kernel execution path. Techniques like FlashAttention-3 fuse memory-bound operations into single kernels, reducing HBM access overhead.
Furthermore, CUDA Graphs reduce the CPU launch overhead for GPU kernels. In virtualized environments, the overhead of trapping into the hypervisor to submit work to the GPU can negate the benefits of CUDA Graphs. GMI Cloud’s bare metal environment allows CUDA Graphs to execute with near-zero CPU intervention.
# Example: Enabling CUDA Graphs in vLLM on GMI Cloud
# This configuration minimizes CPU launch latency
engine_args = AsyncEngineArgs(
model="meta-llama/Meta-Llama-3-70B",
enforce_eager=False, # Enable CUDA Graphs
max_context_len_to_capture=8192,
gpu_memory_utilization=0.95 # High utilization on bare metal
)
Pricing Models: Cost Predictability vs. Flexibility
Affordability is also determined by how you pay. Different services offer different models:
1. Reserved Instances (Lowest TCO)
For sustained workloads (e.g., a chatbot with steady daily traffic), reserving GPUs for 1-3 years offers the lowest effective cost. GMI Cloud offers significant discounts for reserved H200 clusters, providing price stability that spot-instance providers cannot match.
2. On-Demand (Maximum Flexibility)
Pay-as-you-go is essential for prototyping. While hourly rates are higher, the lack of commitment reduces risk. Check the GMI Cloud Pricing Page for real-time rates.
3. Hybrid Auto-Scaling
The most sophisticated affordability strategy involves a hybrid approach. Use reserved instances for your baseline load, and utilize GMI Cloud’s Inference Engine to auto-scale on-demand nodes during peak traffic. This ensures you never pay for idle compute while maintaining fast response times during surges.
Case Study: Migration from Token API to Bare Metal
Consider a financial analytics firm processing 50 million tokens per day using Llama 3 70B.
- Scenario A (Token API): At $0.90 per million tokens, daily cost is $45. Latency varies between 200ms and 800ms due to multi-tenancy.
- Scenario B (GMI Cloud Bare Metal): Renting a cluster of H200s. With high batching efficiency (batch size 128), the effective throughput allows the firm to process the same volume for an effective cost of $0.45 per million tokens. P99 latency stabilizes at 120ms.
This demonstrates that for high-volume users, moving from a "cheap" token API to a dedicated bare metal infrastructure actually reduces costs while improving speed.
FAQ: Inference Service Selection
Q: Why do virtualized clouds have higher latency?
Yes, virtualization adds overhead. The hypervisor (software managing VMs) consumes CPU cycles and interrupts, adding delay before the request reaches the GPU. Bare Metal removes this layer.
Q: Is the H200 worth the premium over H100 for inference?
Yes. The H200's 4.8 TB/s bandwidth (vs 3.35 TB/s on H100) allows for faster token generation. The speed increase often offsets the higher hourly price, resulting in a lower cost per token.
Q: Can I use consumer GPUs (RTX 4090) for affordable inference?
No. NVIDIA's EULA prohibits GeForce cards in data centers. Enterprise GPUs like H100/H200 are required for compliance and reliability.
Q: What is the fastest way to deploy a model on GMI Cloud?
Use the Model Library. Our pre-configured endpoints for models like DeepSeek R1 and Llama 3 are optimized for our H200 infrastructure and can be deployed in minutes.
What's next
- View detailed hardware specs on the GPU Instances Page.
- Compare costs for your specific workload on the Pricing Page.
- Start a free trial or POC by contacting GMI Cloud Sales.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
