What Enterprise Solutions Offer Scalable LLM Inference with High Uptime? (2026 Guide)
February 21, 2026
As Generative AI moves from pilot projects to core business infrastructure, the definition of "scalability" has evolved. It is no longer sufficient to scale up (add more GPUs); systems must scale out (across nodes and regions) while maintaining high availability (HA). For CTOs, the critical metric is the Service Level Agreement (SLA) compliance for both uptime and latency variance (P99).
Scaling inference for models like Llama 3 70B or DeepSeek V3 presents unique challenges compared to traditional microservices. The stateful nature of KV-caches, the massive bandwidth requirements of model weights, and the necessity for GPU-direct networking require a specialized architecture. This guide analyzes the enterprise solutions available in 2026, focusing on how Orchestration Engines, Hardware Redundancy, and Network Topology contribute to a resilient inference architecture.
The Three Pillars of Enterprise Reliability
To achieve high uptime (99.99% or "four nines") in AI inference, an enterprise solution must address reliability at three distinct layers: Infrastructure, Orchestration, and Application.
Infrastructure Reliability (The Hardware Layer)
Reliability begins with the GPU itself. Enterprise workloads utilize ECC (Error-Correcting Code) Memory found in NVIDIA H100 and H200 GPUs to detect and correct single-bit errors that could otherwise cause model hallucinations or crashes. Consumer-grade cards (RTX 4090) lack this critical feature.
GMI Cloud deploys H200s in HGX H200 configurations, where NVSwitch redundancy ensures that even if one link fails, the remaining bandwidth is sufficient to maintain cluster communication, preventing total job failure. Furthermore, our Bare Metal provisioning system includes automated burn-in testing (using DCGM diagnostic level 3) before any node is handed over to a customer, ensuring "Day 0" hardware health.
Orchestration Reliability (The Control Plane)
Hardware fails. A robust orchestration layer must detect failures and heal the system automatically. GMI Cloud’s Cluster Engine is built on Kubernetes (K8s), providing sophisticated failure management strategies:
- Liveness Probes: Continuously checks if the inference server (e.g., vLLM or Triton) is responsive via HTTP/gRPC endpoints.
- Readiness Probes: Ensures a model is fully loaded into HBM before routing traffic to it, preventing "Cold Start" errors.
- Automatic Cordon & Drain: If a node reports GPU Xid errors (e.g., Xid 31 for memory page faults), the Cluster Engine automatically cordons the node to prevent new pods from scheduling there and triggers a node replacement workflow.
Application Reliability (The Serving Layer)
Enterprise solutions employ Load Balancing strategies that go beyond simple Round-Robin. Intelligent routing directs traffic based on queue depth and KV-cache utilization, ensuring no single replica becomes a bottleneck. GMI Cloud supports sidecar proxies that handle request hedging—sending the same request to two independent replicas and returning the fastest response—to minimize tail latency.
Scalability Architectures: Cloud vs. Bare Metal K8s
When selecting a solution, enterprises typically choose between Managed Kubernetes Services on Hyperscalers (EKS/GKE) and Bare Metal Kubernetes on AI Clouds.
Table 1: Scalability & Uptime Comparison
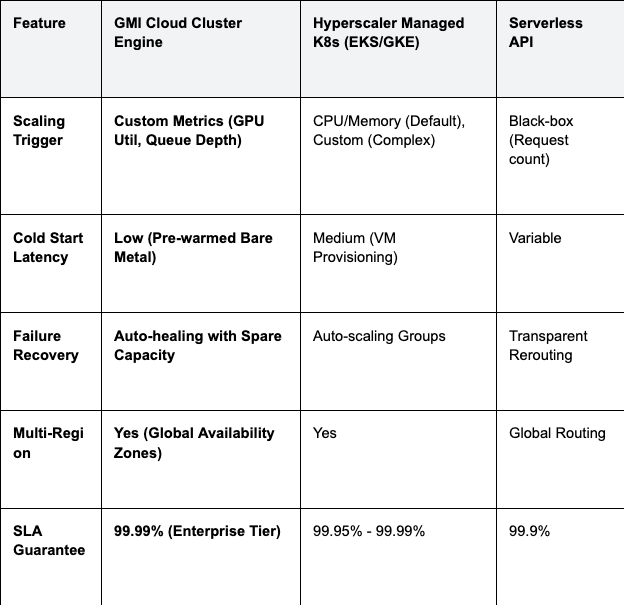
Engineering Insight: GMI Cloud's Cluster Engine allows for "Scale-to-Zero" for development workloads to save costs, while offering "Standby Replicas" for production workloads to ensure zero cold-start latency during traffic spikes.
Advanced Networking Architecture
For scalable inference, specifically for large models requiring Tensor Parallelism across multiple GPUs or nodes, the network is often the bottleneck. Standard Ethernet TCP/IP introduces significant CPU overhead and latency.
RDMA and GPUDirect
GMI Cloud leverages Remote Direct Memory Access (RDMA) over InfiniBand. This technology allows GPUs on different servers to read and write to each other's memory directly, bypassing the host CPU and OS kernel entirely.
- Latency Reduction: RDMA operations typically complete in under 1 microsecond, compared to 10-50 microseconds for TCP/IP.
- Throughput: Our 3.2 Tbps non-blocking network ensures that all-reduce operations (critical for synchronizing weights in distributed inference) never stall the computation.
CNI Plugins for High Performance
In our Kubernetes environment, we utilize specialized CNI (Container Network Interface) plugins. Unlike the standard Flannel or Calico plugins used for general web apps, our **Multus CNI** configuration attaches a secondary, high-speed network interface directly to the Pod. This segregates control plane traffic (Kubernetes API calls) from the data plane traffic (Tensor Parallelism), ensuring that management operations never interfere with inference speed.
Implementing Auto-Scaling on GMI Cloud
True scalability implies the ability to handle traffic surges without manual intervention. GMI Cloud supports HPA (Horizontal Pod Autoscaler) based on custom Prometheus metrics exported by the GPU.
Configuration Example: KEDA Scaler for Inference
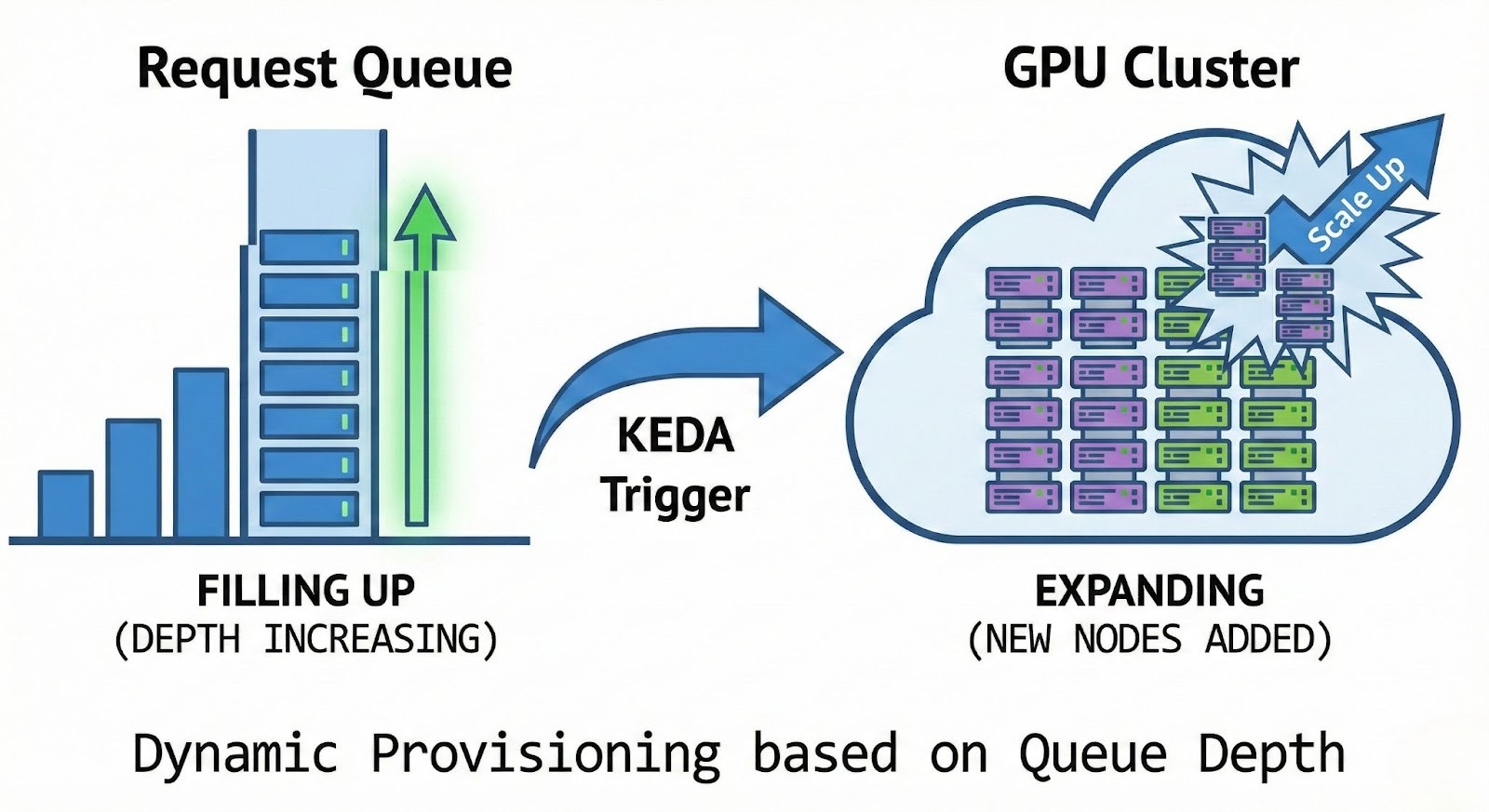
The following Kubernetes configuration demonstrates how to scale an inference service based on the number of pending requests in the queue, a more accurate metric than CPU usage.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: llama3-inference-scaler
spec:
scaleTargetRef:
name: llama3-deployment
minReplicaCount: 2 # High Availability Baseline
maxReplicaCount: 20 # Peak Capacity
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server.monitoring.svc.cluster.local
metricName: vllm:num_requests_waiting
threshold: '5'
query: sum(vllm_num_requests_waiting{model_name="llama3-70b"})
This configuration ensures that as soon as the queue depth exceeds 5 requests, new Bare Metal H200 pods are provisioned instantly. Unlike VM-based autoscaling which can take minutes to boot the OS, our pre-provisioned standby nodes allow for sub-minute scaling times.
Enterprise Security Architecture
Scalability cannot come at the cost of security. As inference workloads often process sensitive user data (PII), the architecture must enforce strict isolation and encryption.
Isolation and Multitenancy
GMI Cloud employs a strict "Hard Multi-tenancy" model for Bare Metal instances. Since customers have root access to the physical machine, there is zero risk of side-channel attacks (like Spectre/Meltdown variants) from noisy neighbors sharing the same CPU cache. The isolation is physical, not virtual.
Encryption at Rest and in Transit
- In Transit: All ingress traffic is terminated via TLS 1.3 at the Global Load Balancer. Internal east-west traffic between microservices can be secured via mTLS (Mutual TLS) using Istio service mesh, which GMI Cloud supports out-of-the-box.
- At Rest: Model weights and KV-cache data stored on local NVMe drives are encrypted using LUKS (Linux Unified Key Setup) with keys managed via an external KMS (Key Management System).
Governance and Policy
We integrate OPA (Open Policy Agent) Gatekeeper into the Cluster Engine. This allows enterprise administrators to enforce policies such as:
- Restricting container registries to trusted internal sources only.
- Preventing privileged container execution (except for specific system agents).
- Enforcing resource quotas per department or team to prevent budget runaways.
Deployment Strategies: Zero-Downtime Updates
High uptime must be maintained even during model updates. GMI Cloud supports advanced deployment strategies natively within the Cluster Engine.
Blue/Green Deployment
For major model version updates (e.g., upgrading from Llama 2 to Llama 3), a Blue/Green strategy is recommended. The new version (Green) is deployed alongside the old version (Blue). Traffic is switched atomically at the load balancer level only after the Green environment passes all health checks. This ensures instant rollback capability if anomalies are detected.
Canary Releases
For finer-grained control, Canary releases allow you to route a small percentage of traffic (e.g., 5%) to the new model version. This is critical for validating performance metrics like Time-To-First-Token (TTFT) in production without risking the entire user base.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: inference-routing
spec:
hosts:
- llm-service
http:
- route:
- destination:
host: llm-service
subset: v1
weight: 95
- destination:
host: llm-service
subset: v2
weight: 5
Multi-Region High Availability (HA)
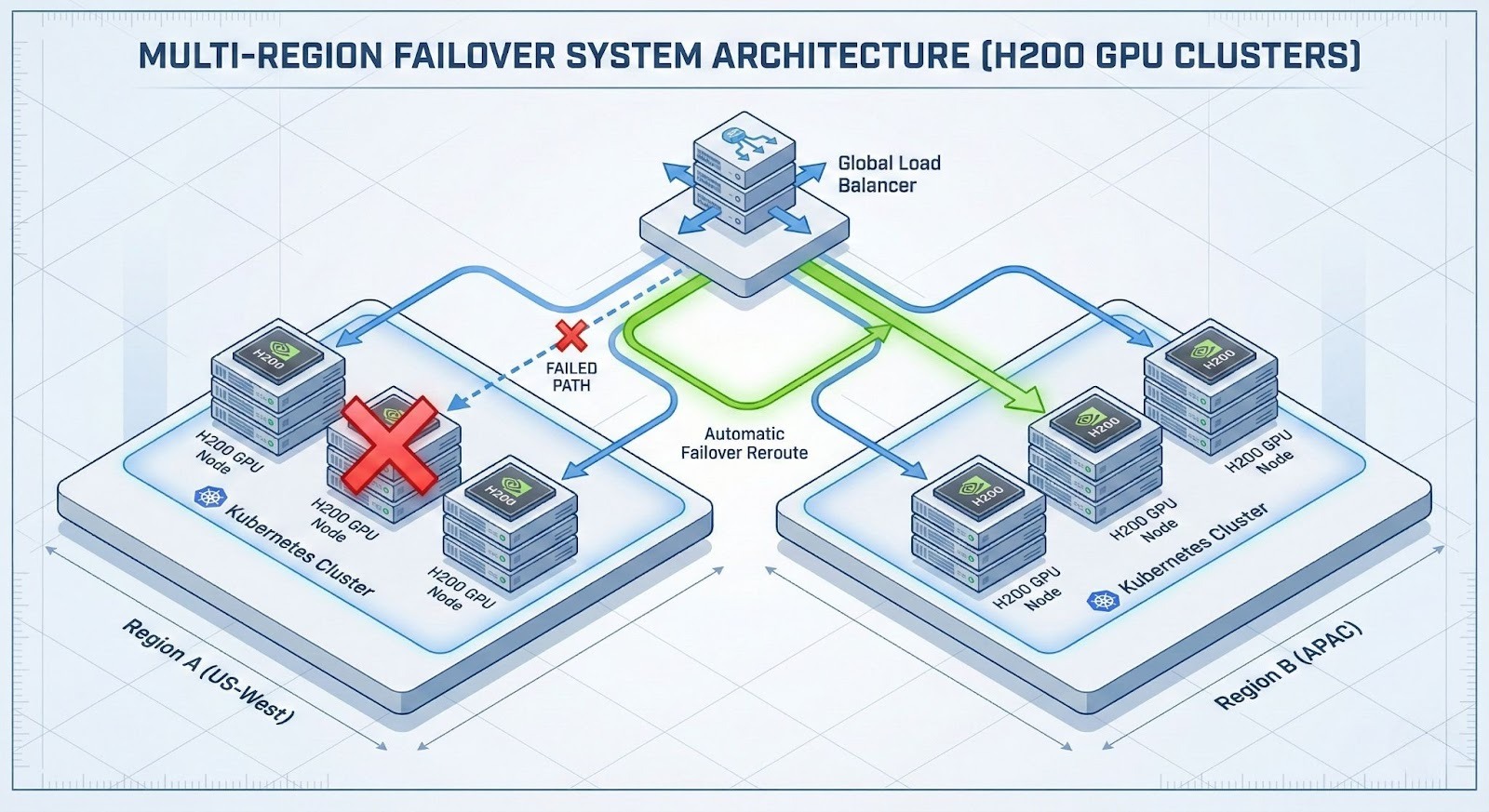
For global enterprises, "Uptime" also means resilience against regional outages. GMI Cloud operates Tier-4 data centers across the US (Mountain View, Denver), APAC (Taipei, Bangkok), and other strategic locations.
By deploying Federated Clusters, enterprises can route traffic to the nearest healthy region. If the US-West region experiences latency degradation, the global load balancer automatically redirects inference requests to US-East or APAC, ensuring service continuity. Our control plane synchronizes configuration state across regions, ensuring that scaling policies and security rules are consistent globally.
Monitoring and Observability
You cannot scale what you cannot measure. Enterprise solutions must provide deep observability into the inference pipeline. GMI Cloud integrates with standard observability stacks.
- Grafana Dashboards: Visualize real-time Token/s throughput, P99 latency, and Queue Depth. Custom dashboards for "Cost per Request" can also be configured.
- DCGM Exporter: Monitor hardware health at a granular level, including GPU temperature, power draw, SM clock frequencies, and ECC error counts. Alerts can be set to trigger before a thermal throttling event occurs.
- Distributed Tracing: Integrate with Jaeger or Zipkin to track a request's journey from the load balancer, through the API gateway, to the specific GPU core processing the token. This is essential for debugging latency outliers.
FAQ: Enterprise Reliability
Q: What represents "99.99% Uptime" in an inference context?
Strict availability. It means the inference API is available and responding within the latency SLA (e.g., <200ms TTFT) for 99.99% of requests. This translates to less than 5 minutes of downtime per month. GMI Cloud backs this with financial credits for downtime events.
Q: How does GMI Cloud handle maintenance upgrades?
Rolling Updates. Our Cluster Engine supports rolling updates for driver patches and OS upgrades. Nodes are drained one by one, ensuring that total cluster capacity never drops below the service threshold. Workloads are gracefully terminated and rescheduled on updated nodes automatically.
Q: Can I reserve capacity for unexpected spikes?
Yes. We offer "Burstable Capacity" agreements where you hold a reserved baseline (e.g., 10 GPUs) and have priority access to an additional pool (e.g., 50 GPUs) during peak events. This guarantees resource availability during product launches or marketing campaigns.
Q: Does GMI Cloud support private networking (VPC)?
Yes. Enterprise customers can utilize Virtual Private Cloud (VPC) isolation and Direct Connect options to peer their existing on-premise infrastructure with GMI Cloud's GPU resources securely. This allows for hybrid cloud architectures where sensitive data remains on-premise while compute bursts to the cloud.
What's next
- Review the Service Level Agreement (SLA) for enterprise tiers.
- Explore Cluster Engine features for automated orchestration.
- Contact Enterprise Sales to discuss multi-region deployment strategies.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
