Where to Find Pre-built LLM Inference Models for Chatbot Development (2026 Guide)
February 21, 2026
In 2026, the primary bottleneck in chatbot development is no longer model availability, but model optimization. While repositories like Hugging Face offer access to over 500,000 models, these are typically "raw" weights that require significant engineering effort to serve with low latency. Developers must manually configure Docker containers, handle GPU memory mapping, and implement quantization strategies.
To accelerate Time-to-First-Token (TTFT) and ensure production stability, AI engineering teams are shifting towards Managed Model Libraries. These platforms host pre-built, pre-optimized inference endpoints running on high-performance infrastructure. This guide evaluates the best sources for these models, focusing on performance, customization, and infrastructure transparency.
The Three Tiers of Pre-built Model Sources
When searching for pre-built models, developers generally encounter three categories of providers, each offering a different balance of control and convenience.
Tier 1: Managed Model Libraries (Recommended for Enterprise)
Providers like GMI Cloud, Together AI, and Fireworks.ai offer "Serverless" or "Dedicated" endpoints for open-weights models.
- Characteristics: Models are pre-loaded onto GPUs; APIs are instantly available; underlying infrastructure is optimized.
- Optimization: Includes kernel-level optimizations (FlashAttention-3, TensorRT-LLM) and hardware acceleration (FP8 on H200).
- Best For: Production chatbots requiring strict SLAs, low latency, and immediate scalability.
Tier 2: Raw Model Repositories
Hugging Face is the de facto standard for storing model weights.
- Characteristics: Provides raw `.safetensors` or `.bin` files.
- Optimization: Zero. You must build the serving stack (vLLM, TGI) yourself.
- Best For: Research, custom pre-training, or highly specific fine-tuning capabilities not supported by managed providers.
Tier 3: Closed Proprietary APIs
OpenAI (GPT-4) and Anthropic (Claude 3.5).
- Characteristics: Black-box models accessible only via API.
- Optimization: Fully managed but opaque. High cost per token at scale.
- Best For: Prototyping or scenarios where data privacy and cost are secondary to reasoning capability.
Top Pre-built Models for Chatbot Development in 2026
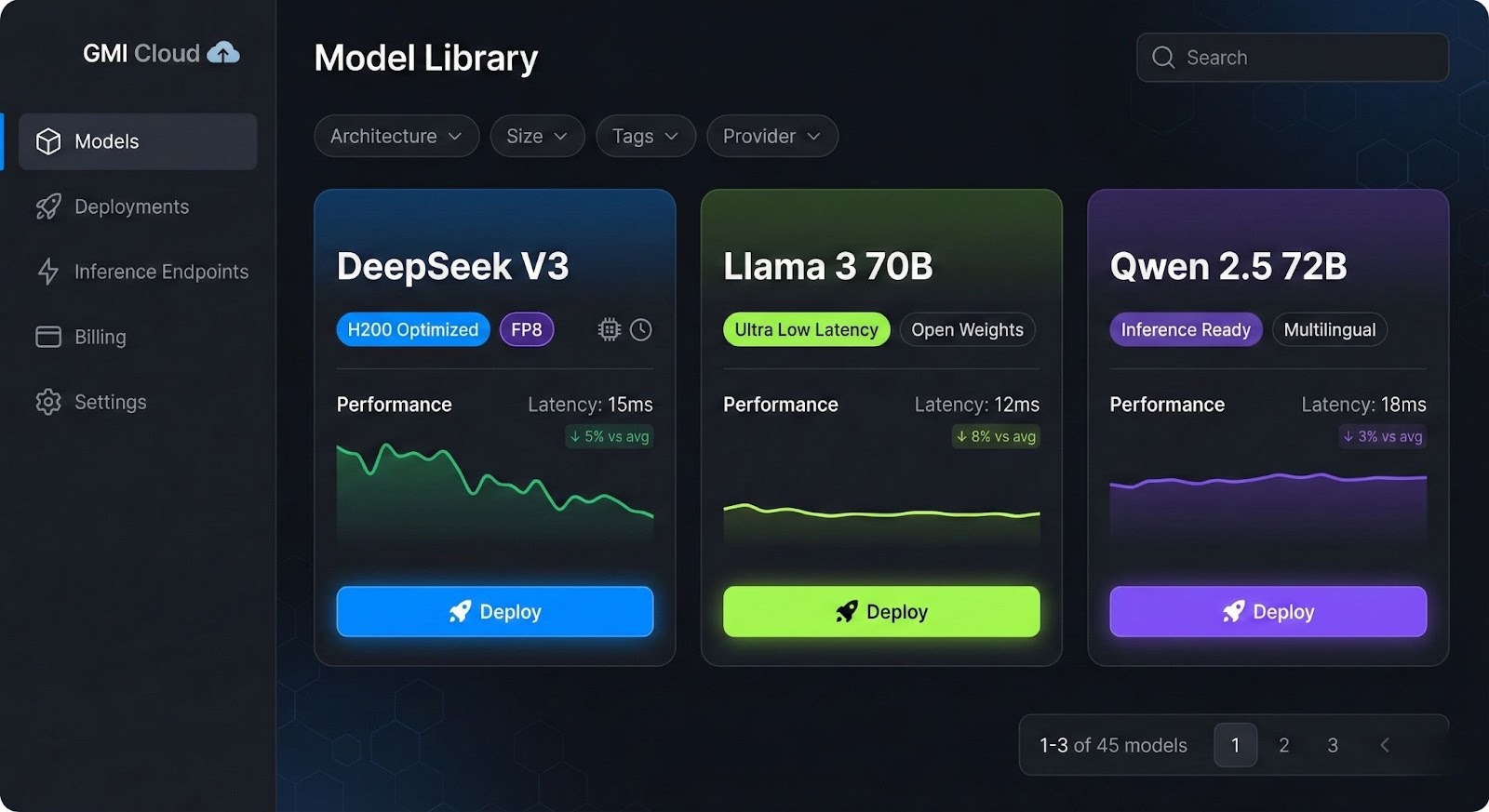
Within the GMI Cloud Model Library, specific models have emerged as the industry standards for conversational AI. These models are hosted on NVIDIA H200 infrastructure to maximize context window throughput.
DeepSeek V3 & R1
DeepSeek has redefined the price-performance curve. The V3 model (Mixture-of-Experts) rivals GPT-4 class performance at a fraction of the inference cost.
- Use Case: Complex reasoning, coding assistants, multi-turn dialogue.
- Infrastructure Requirement: Requires multi-node H200 clusters due to massive parameter count (671B). GMI Cloud handles this orchestration automatically.
Llama 3 (70B & 8B)
Meta's Llama 3 remains the workhorse for general-purpose chatbots.
- Use Case: Customer support agents, content generation, RAG (Retrieval-Augmented Generation) pipelines.
- Optimization: On GMI Cloud, Llama 3 70B is served with FP8 precision, utilizing the H200's Transformer Engine to double throughput compared to FP16.
Qwen 2.5 (72B)
Alibaba's Qwen series excels in multi-lingual capabilities and mathematical reasoning.
- Use Case: Global chatbots requiring strong performance in Asian languages.
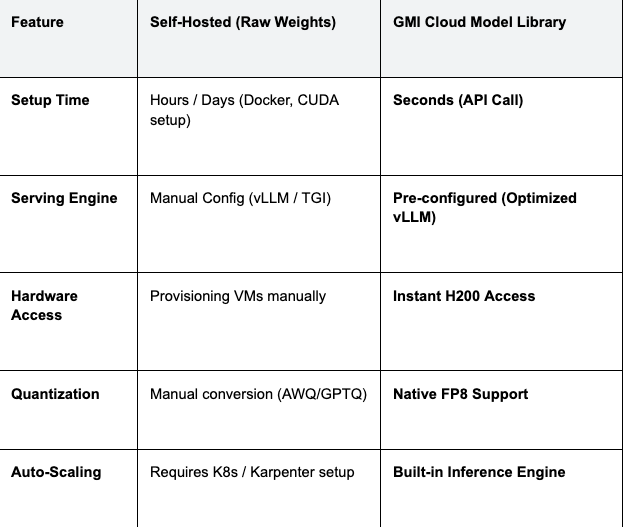
Technical Comparison: Raw Weights vs. GMI Cloud Model Library
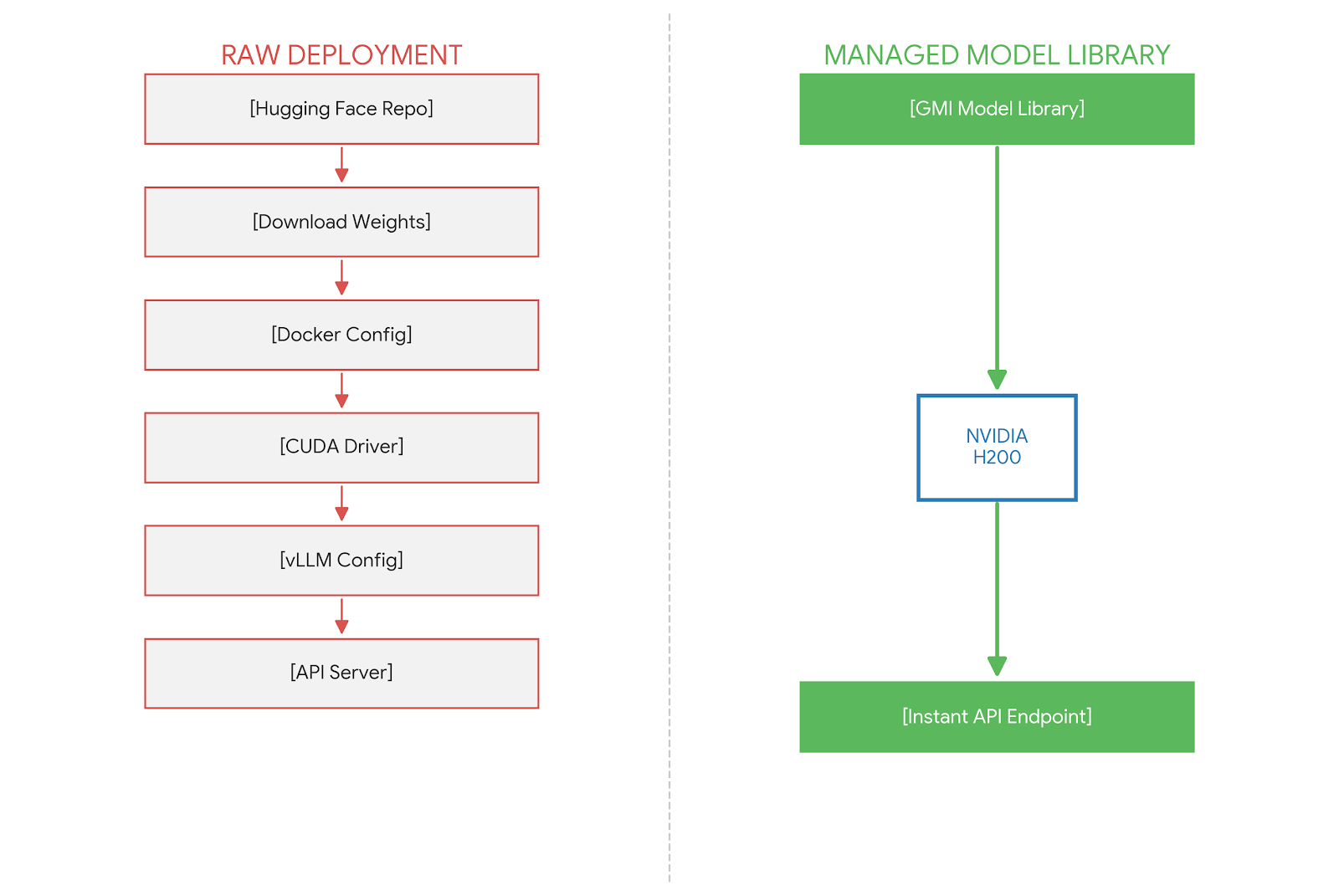
The following table illustrates the engineering overhead removed by using a managed model library versus self-hosting raw weights.
Table 1: Deployment Comparison
Engineering Insight: Self-hosting Llama 3 70B requires managing the KV-cache memory limits manually. GMI Cloud's endpoints automatically handle PagedAttention memory mapping on H200s, preventing Out-Of-Memory (OOM) errors during high concurrency.
How to Integrate Pre-built Models
Integrating a model from the GMI Cloud Model Library into your chatbot application is designed to be drop-in compatible with the OpenAI SDK standard. This allows developers to migrate from closed APIs to open weights with minimal code changes.
Python Implementation Example
The following code snippet demonstrates how to query the DeepSeek V3 model hosted on GMI Cloud:
import openai
# Configure the client to point to GMI Cloud's API
client = openai.OpenAI(
base_url="https://api.gmicloud.ai/v1",
api_key="YOUR_GMI_API_KEY"
)
# Create a chat completion request
response = client.chat.completions.create(
model="deepseek-v3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Explain memory management in CUDA."}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content or "", end="")
This implementation leverages the Inference Engine, which routes the request to the nearest available Bare Metal H200 instance, ensuring minimal latency.
Infrastructure Matters: The H200 Advantage
When choosing a source for pre-built models, the underlying hardware is as critical as the model architecture. Many providers run models on older A100 or even A10 GPUs to save costs, which results in high latency.
GMI Cloud exclusively hosts its Model Library on NVIDIA H200 and H100 GPUs. The H200's 4.8 TB/s memory bandwidth is particularly beneficial for chatbots using RAG, as it allows for processing long context windows (up to 128k tokens) with significantly lower latency than A100-based alternatives.
FAQ: Using Pre-built Models
Q: Can I fine-tune these pre-built models?
Yes. While the Model Library provides ready-to-use inference endpoints, GMI Cloud also offers Cluster Engine for fine-tuning. You can take a base model like Llama 3, fine-tune it on your data using LoRA/QLoRA on our bare metal H100s, and then serve it.
Q: Are the models running on shared or dedicated hardware?
Both options are available. For development, our Serverless API uses shared resources for cost efficiency. For production, you can deploy the same models to Dedicated Instances (Bare Metal H200s) for guaranteed throughput and isolation.
Q: How does GMI Cloud ensure model data privacy?
Strict isolation. Unlike some providers that may use request data for training, GMI Cloud adheres to strict enterprise privacy standards. Data sent to our inference endpoints is ephemeral and never stored or used for model training.
Q: Where can I see the full list of supported models?
Visit the Model Library. Our Model Library page is updated weekly with the latest state-of-the-art open source models, including new releases from Mistral, Meta, and DeepSeek.
What's next
- Browse the GMI Cloud Model Library to find the right model for your chatbot.
- Read the technical documentation on API Integration.
- Get a free consultation on sizing your H200 cluster for production traffic.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
