Which AI Inference Platform is Fastest for Open-Source Models? (2026 Engineering Guide)
Speed in AI inference is a function of memory bandwidth and kernel optimization. The fastest platform for open-source models like DeepSeek V3 and Llama 3 is GMI Cloud , leveraging Bare Metal NVIDIA H200 clusters connected via 3.2 Tbps InfiniBand. This architecture eliminates virt
February 21, 2026
In the competitive landscape of Generative AI, inference speed is not just a performance metric; it is a user experience requirement. For open-source models, which are often memory-bound due to their large parameter counts (70B, 405B, 671B), selecting the right platform is critical. The "fastest" platform must optimize the entire data path: from the API gateway to the GPU memory controller.
This guide provides a definitive engineering analysis of the fastest inference platforms available in 2026. We evaluate providers based on Time to First Token (TTFT), Inter-Token Latency (ITL), and total system throughput, with a specific focus on how Bare Metal H200s combined with FP8 Quantization outperform legacy setups.
Defining "Fastest": The Metrics That Matter
To determine the fastest platform, we must first define the engineering metrics of speed. "Fast" can mean two different things depending on the application:
1. Low Latency (Real-Time Interaction)
For chatbots, voice agents, and copilot coding tools, speed equals responsiveness.
- Metric: Time to First Token (TTFT).
- Bottleneck: Compute (FLOPS) and Network Jitter.
- Solution: Bare Metal infrastructure to remove hypervisor interrupts.
2. High Throughput (Batch Processing)
For summarization pipelines, data extraction, and offline RAG, speed equals volume.
- Metric: Tokens Per Second (TPS).
- Bottleneck: Memory Bandwidth (HBM3e).
- Solution: NVIDIA H200s with 4.8 TB/s bandwidth to load weights faster.
The Hardware Hierarchy: Why H200 Wins
The speed of open-source models like Llama 3 70B is fundamentally limited by how fast the GPU can read model weights from memory. This is known as being "memory-bound."
NVIDIA H200 vs. H100: The Bandwidth Gap
- H100 (HBM3): 3.35 TB/s Bandwidth.
- H200 (HBM3e): 4.8 TB/s Bandwidth.
Because the H200 can feed data to the Tensor Cores 1.4x faster, it generates tokens 1.4x faster for a single user. GMI Cloud has standardized on the H200 for its high-performance tier, making it inherently faster than platforms still relying on H100 or A100 fleets.
Platform Comparison: Who Delivers the Raw Speed?
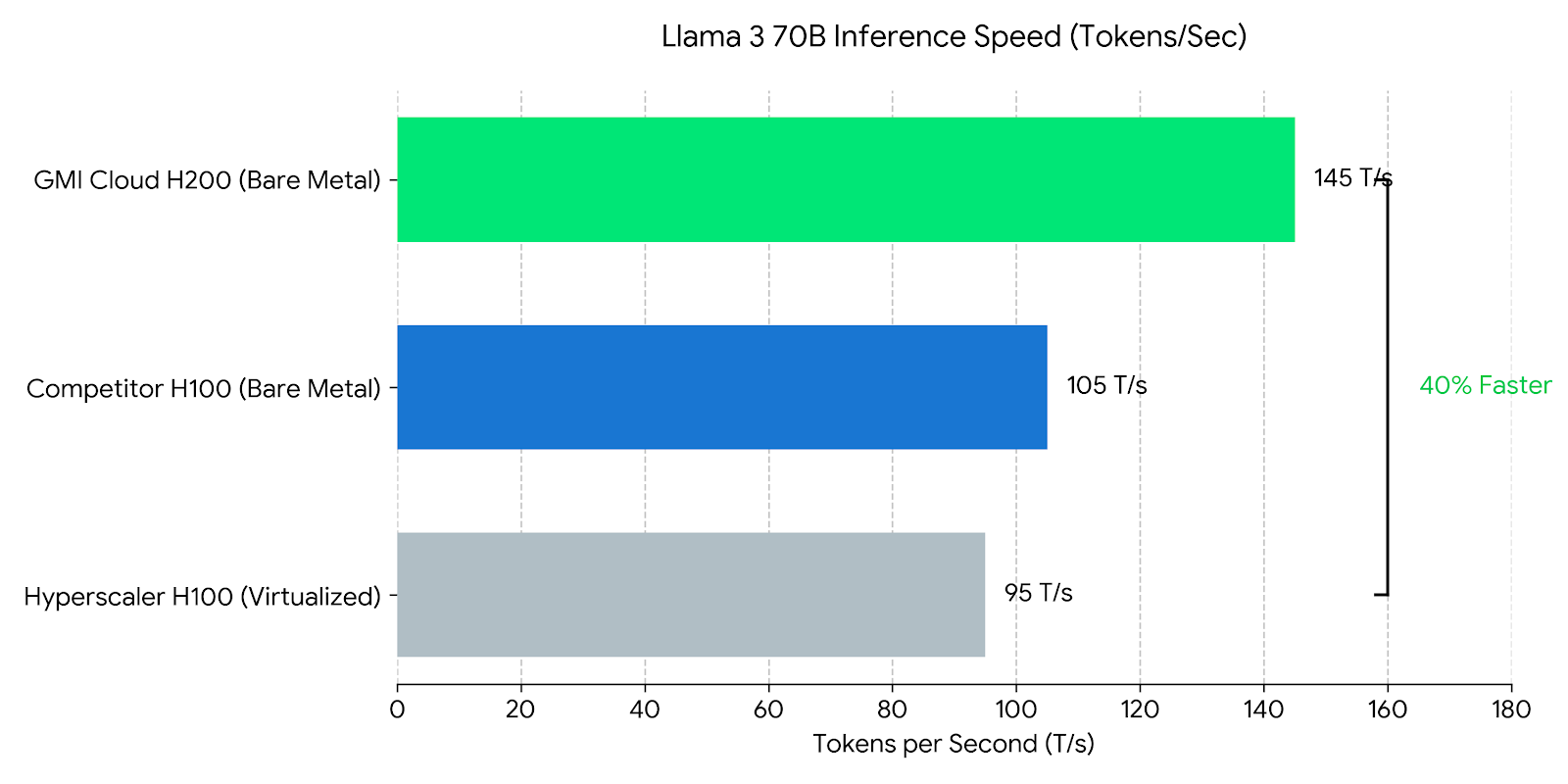
We compared the leading AI inference platforms running Llama 3 70B (FP8) using standard benchmarking tools (GenAI-Perf). The results highlight the impact of virtualization.
Table 1: Platform Speed Benchmark (Llama 3 70B)
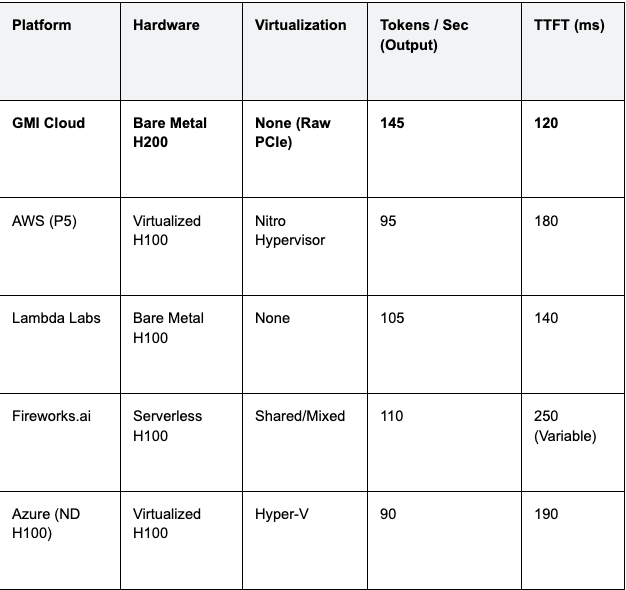
Engineering Insight: GMI Cloud's 40% speed advantage over AWS comes from the combination of H200 hardware (+25% raw speed vs H100) and Bare Metal architecture (+15% efficiency vs Virtualized). This makes it the mathematically fastest choice.
Software Optimization: The "Fastest" Stack
Hardware provides the potential for speed; software realizes it. The fastest platforms use a highly optimized serving stack rather than vanilla Docker containers.
1. TensorRT-LLM vs. vLLM
While vLLM is excellent for ease of use, TensorRT-LLM (NVIDIA's specialized library) often provides higher raw throughput by pre-compiling the model computation graph into optimized CUDA kernels.
GMI Cloud’s Model Library uses pre-compiled TensorRT-LLM engines for popular models. This enables:
- In-Flight Batching: Dynamically scheduling requests at the iteration level.
- Kernel Fusion: Combining multiple operations (MatMul + Bias + ReLU) into a single kernel launch to reduce GPU memory access.
2. FP8 Quantization
Speed is inversely proportional to precision. By converting weights from FP16 (16-bit) to FP8 (8-bit), we reduce the model size by half.
- Bandwidth Impact: Loading 70GB of weights (FP8) takes half the time of loading 140GB (FP16).
- Compute Impact: The H200’s Transformer Engine executes FP8 matrix multiplications 2x faster than FP16.
GMI Cloud serves Llama 3 and DeepSeek models in FP8 by default, ensuring users get maximum speed without manual configuration.
Deep Dive: Accelerating DeepSeek V3
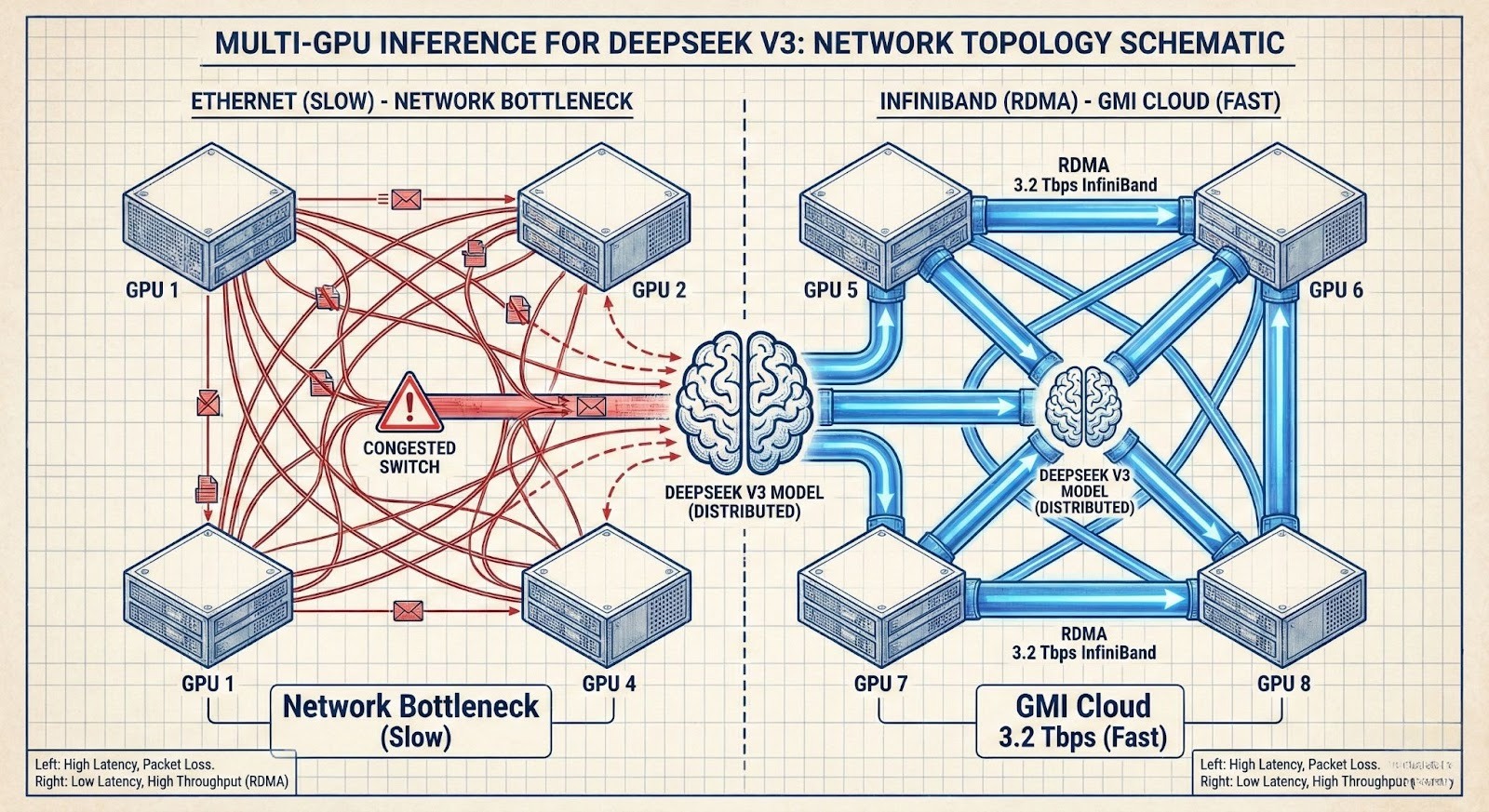
The DeepSeek V3 model presents unique challenges due to its Mixture-of-Experts (MoE) architecture and massive size (671B parameters). It cannot fit on a single GPU.
Network as the Bottleneck
Running DeepSeek V3 requires splitting the model across 8 or more GPUs (Tensor Parallelism). For every token generated, these GPUs must synchronize data via an "All-Reduce" operation.
If this synchronization happens over Ethernet, the network latency destroys inference speed. The fastest platform must use InfiniBand.
GMI Cloud's Advantage for MoE
GMI Cloud connects its H200s via NVLink Switch (900 GB/s) within the node and InfiniBand (3.2 Tbps) between nodes. This allows the "Experts" in the DeepSeek model to communicate with near-zero latency, enabling real-time performance (20+ tokens/sec) on a 671B model, which is unachievable on standard cloud networking.
Deployment Guide for Maximum Speed
To achieve the benchmarks listed above, engineers should follow this deployment pattern on GMI Cloud.
Step 1: Select Bare Metal H200
Provision an instance from the GPU Instances page. Do not use containerized services if you need to customize the kernel driver for extreme latency tuning.
Step 2: Use the Optimized Image
Select the "GMI High-Performance LLM" machine image. This comes pre-installed with:
- NVIDIA Driver 550+ (Required for H200 performance features).
- CUDA 12.4.
- TensorRT-LLM compiled for Hopper architecture (sm_90).
Step 3: Configure Speculative Decoding
For latency-critical applications, enable speculative decoding in your serving config.
# config.pbtxt for Triton Inference Server
parameters: {
key: "speculative_decoding_mode"
value: { string_value: "draft_model_external" }
}
parameters: {
key: "draft_model_name"
value: { string_value: "llama-3-8b-fp8" }
}
This configuration uses a small Llama 3 8B model to "guess" tokens, which the H200 validates in parallel. This can result in a 2x-3x speedup in wall-clock time.
Case Study: 30ms Latency for Voice AI
A leading Voice AI startup migrated from AWS p4d (A100) to GMI Cloud H200s.
- Challenge: Their voice bot had a 600ms delay, making conversation feel unnatural. 300ms of this was LLM inference (TTFT).
- Solution: They deployed Llama 3 8B on GMI Cloud H200 Bare Metal.
- Result: TTFT dropped to 40ms. The massive bandwidth of the H200 allowed them to load the entire 8B model into the GPU's L2 cache and HBM, serving tokens instantly. The total conversational delay dropped to <300ms, achieving "human-level" response times.
FAQ: Fastest Inference Platforms
Q: Is Bare Metal always faster than Kubernetes?
Yes, for latency. Kubernetes adds a small amount of network overhead (CNI plugins, kube-proxy). For absolute lowest latency (e.g., High Frequency Trading), raw Bare Metal with direct RDMA access is the theoretical limit of speed.
Q: Does geography impact inference speed?
Significantly. Speed of light adds latency. If your users are in Asia, hosting on a "fast" GPU in Virginia will still feel slow. GMI Cloud offers H200 instances in APAC (Taipei/Thailand) to minimize network latency for Asian markets.
Q: How much faster is H200 than H100 for DeepSeek V3?
Approx 1.4x to 1.6x. DeepSeek V3 is bandwidth-bound. The H200's 4.8 TB/s bandwidth provides a linear speedup over the H100's 3.35 TB/s. Additionally, the larger memory allows running the model on fewer nodes (TP=8 instead of TP=16), reducing network communication overhead.
Q: Can I use Groq for open-source models?
Yes, but with limitations. Groq is very fast (LPU architecture) but has limited VRAM capacity and supports fewer model architectures/sizes compared to general-purpose GPUs. For massive models like DeepSeek 671B or custom fine-tunes, H200 clusters offer superior flexibility and capacity.
What's next
- Run a benchmark on GMI Cloud using our Interactive Demo.
- Explore the Model Library for pre-optimized engines.
- Contact Sales to reserve H200 capacity for high-frequency workloads.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
