Which AI Inference Platform is Most Reliable? (2026 Engineering Guide)
February 21, 2026
In the domain of traditional software, reliability is often achieved through redundancy of stateless microservices. However, scaling reliability for Large Language Models (LLMs) presents a unique set of physical challenges. A single "bit flip" in a GPU's memory can cause a 70B parameter model to hallucinate or crash. A network timeout of 50ms can desynchronize a Tensor Parallelism group, causing an entire 8-GPU cluster to stall.
Therefore, the "most reliable" platform is not simply the one with the most servers, but the one with the deepest integration between hardware diagnostics and software orchestration. This guide evaluates the engineering robustness of AI Cloud providers, focusing on Error Correcting Code (ECC) implementation, NVSwitch redundancy, and Automated Fault Tolerance mechanisms.
The Reliability Stack: From Silicon to Service
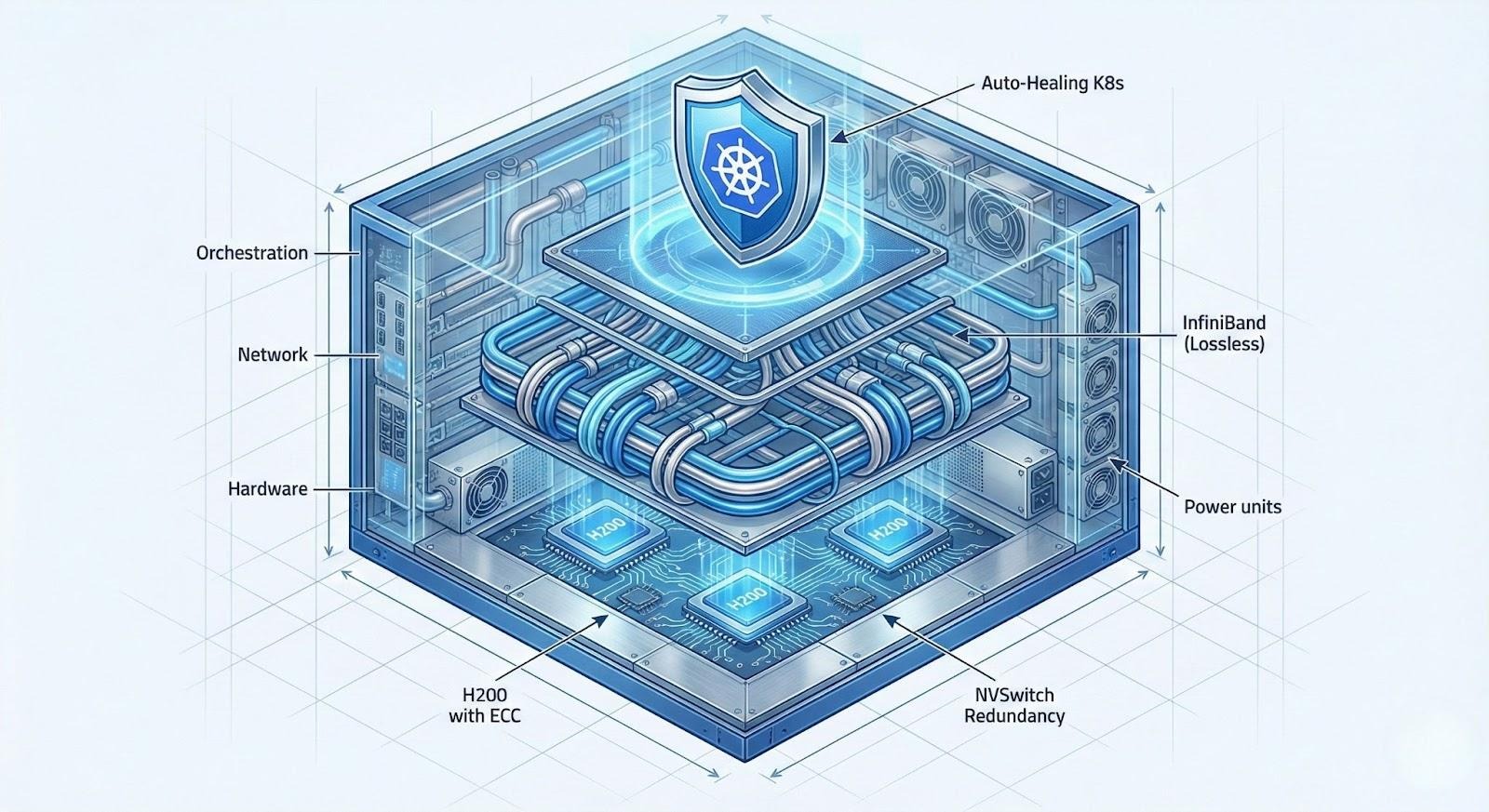
To assess reliability objectively, we must analyze the stack layer by layer. Failure can occur at any level, and the platform must have safeguards for each.
Layer 1: The Silicon (HBM3e and ECC)
The foundation of reliability is the GPU memory. Consumer-grade GPUs (like the RTX 4090) do not support ECC (Error Correction Code) for their VRAM. In a data center running 24/7 at high temperatures, cosmic rays and electrical noise cause "Single Bit Errors" (SBEs).
For an LLM, an SBE in the weights might be negligible, but an SBE in the KV-Cache or activation logic can lead to gibberish output. GMI Cloud exclusively uses NVIDIA H100 and H200 Data Center GPUs with ECC enabled by default. The H200's HBM3e memory includes on-die ECC that corrects errors before they leave the chip, ensuring mathematical determinism.
Layer 2: The Interconnect (NVSwitch)
In multi-GPU inference (e.g., DeepSeek V3), GPUs communicate via NVLink. If a link fails, the model hangs. GMI Cloud’s HGX H200 systems utilize 3rd Generation NVSwitch chips. These switches allow for "SHARP" (Scalable Hierarchical Aggregation and Reduction Protocol) in-network computing, which offloads error checking from the GPU compute cores and provides redundant paths for data.
Layer 3: The Host (Bare Metal vs. Hypervisor)
Hypervisors introduce a "blast radius" risk. If the hypervisor kernel panics, all VMs on that host die. Furthermore, hypervisors often mask low-level hardware errors (like PCIe bus retries) until it is too late. GMI Cloud’s Bare Metal Architecture exposes raw telemetry (via DCGM) to the orchestration layer, allowing for predictive maintenance before a hard failure occurs.
Platform Comparison: Reliability Metrics
We evaluated the leading AI inference platforms based on their fault tolerance mechanisms and hardware standards.
Table 1: Reliability Feature Matrix
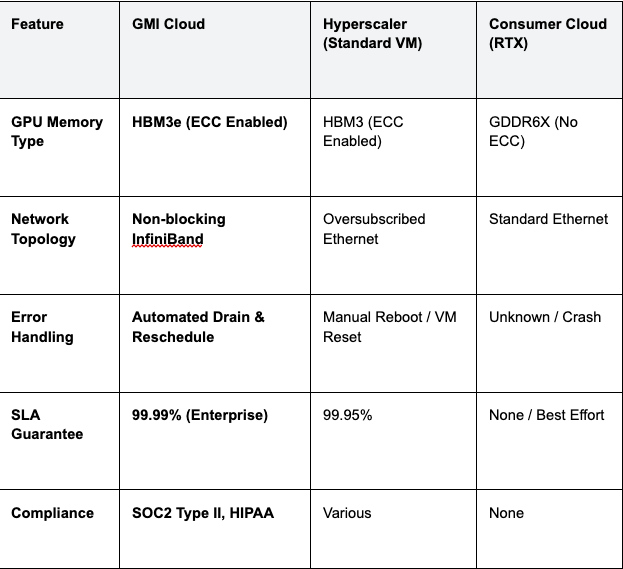
Engineering Insight: "Best Effort" providers using consumer GPUs (RTX 3090/4090) are statistically guaranteed to fail during long-running inference jobs due to lack of ECC and lower MTBF ratings. They are unsuitable for production applications where reliability is non-negotiable.
Automated Fault Tolerance: The "Self-Healing" Cloud
Reliability is not the absence of failure, but the automated recovery from it. GMI Cloud’s orchestration system monitors the health of the GPU fleet in real-time.
Detecting Xid Errors
The NVIDIA driver reports hardware issues via "Xid" error codes. GMI Cloud monitors these specifically:
- Xid 31: GPU memory page fault.
- Xid 43: GPU stopped processing.
- Xid 74: NVLink error.
When our monitoring agent detects a critical Xid error on a node, it immediately triggers a "Cordon" event in Kubernetes. This stops new pods from being scheduled on the compromised node.
The Auto-Drain Workflow
Once cordoned, the system initiates a graceful drain. Existing inference requests are allowed to complete (if possible), or transparently retried on a healthy replica. The faulty node is then rebooted and subjected to a DCGM Level 3 Diagnostic run. If it fails diagnostics, it is physically replaced by data center technicians without the customer ever needing to open a ticket.
Network Reliability: InfiniBand vs. Ethernet
For distributed inference, the network is the most common point of failure. Packet loss on standard Ethernet leads to TCP retransmissions, causing latency spikes (P99 outliers) that can trigger client-side timeouts.
GMI Cloud utilizes 3.2 Tbps InfiniBand with Adaptive Routing. Unlike Ethernet, which drops packets during congestion, InfiniBand uses credit-based flow control to ensure zero packet loss at the hardware layer. This provides a deterministic network environment where "tail latency" is virtually eliminated, ensuring that 99.99% of requests complete within the SLA window.
Deep Dive: DCGM Diagnostics
How do you know a GPU is reliable before you run a workload on it? GMI Cloud runs the NVIDIA Data Center GPU Manager (DCGM) diagnostic suite on every instance boot.
# Example: Running DCGM Level 3 Diagnostics
dcgmi diag -r 3
This test validates:
- Memory Integrity: Writes patterns to every bit of VRAM to check for dead cells.
- PCIe Bandwidth: Ensures the link is negotiating at full Gen5 x16 speed.
- Thermal Stress: Runs a compute virus to ensure cooling systems can maintain clock speeds without throttling.
Only nodes that pass this rigorous testing are added to the active pool available via the Cluster Engine.
Case Study: FinTech Reliability
A high-frequency trading firm needed an LLM to parse news feeds. A single hallucination caused by a bit flip could result in a bad trade worth millions.
- Challenge: Their previous provider (using RTX 4090s) experienced random crashes once a week.
- Solution: Migration to GMI Cloud Bare Metal H200s (ECC enabled).
- Result: Zero hardware-induced crashes in 6 months. The ECC memory corrected over 50 single-bit errors that would have otherwise gone unnoticed or caused silent data corruption.
FAQ: Inference Reliability
Q: Why is consumer hardware (RTX) unreliable for inference?
Lack of ECC and P2P limits. Without Error Correcting Code memory, random bit flips accumulate over time. Additionally, consumer cards lack NVLink/NVSwitch support, making multi-GPU inference fragile and slow over PCIe.
Q: Does GMI Cloud offer a multi-region SLA?
Yes. For enterprise contracts, we offer a multi-region SLA. If an entire region (e.g., US-West) goes offline, our global load balancer automatically reroutes traffic to the nearest healthy region (e.g., US-East or APAC) with sufficient reserved capacity.
Q: How do you protect against thermal throttling?
Overspec'd Cooling. Our data centers are designed for high-density compute (50kW+ per rack). We monitor GPU temperatures continuously. If a GPU exceeds its thermal threshold, our scheduler automatically migrates the workload to a cooler node to prevent performance degradation.
Q: Is Bare Metal harder to recover than a VM?
No, with our automation. While a physical reboot takes longer than a VM restart, our Cluster Engine maintains a pool of "warm spare" nodes. If a bare metal node fails, the Kubernetes pod is instantly rescheduled to a spare node, typically recovering service within seconds.
What's next
- Review our SLA Documentation for detailed uptime guarantees.
- Learn about Model Library redundancy features.
- Contact Enterprise Sales to discuss a High Availability (HA) architecture review.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
