Which Edge Computing Service is Ideal for AI Inference? (2026 Engineering Guide)
February 21, 2026
The definition of "Edge Computing" has undergone a radical shift in the era of Large Language Models (LLMs). Traditionally, edge computing meant running lightweight models (like YOLO or MobileNet) on constrained devices like Raspberry Pis or NVIDIA Jetson modules. However, modern GenAI applications—such as real-time voice translation, autonomous coding agents, and complex RAG (Retrieval Augmented Generation)—require models like Llama 3 70B or DeepSeek V3, which simply cannot fit on a device.
Consequently, the "AI Edge" has moved up the stack. It now refers to Regional Data Centers located within 500km of the user base, connected via high-speed fiber backbones. This guide analyzes the engineering trade-offs between Device Edge, CDN Edge, and Regional Cloud Edge, ultimately identifying the ideal architecture for scalable, low-latency AI inference.
Redefining the Edge: The Three Tiers of Inference
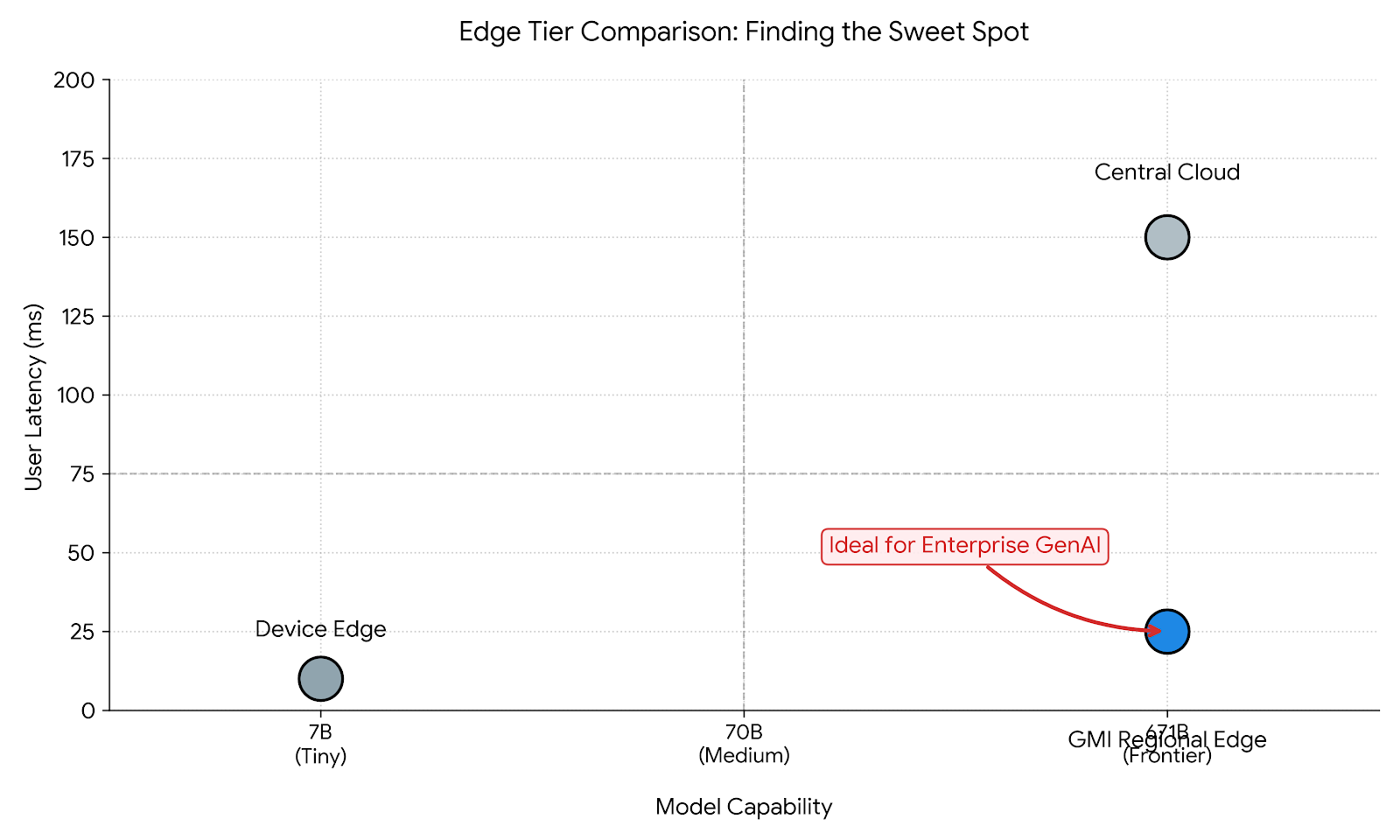
To choose the ideal service, architects must map their model's resource requirements to the appropriate edge tier. There is no "one size fits all."
Tier 1: Device Edge (On-Premise / On-Device)
- Hardware: NVIDIA Jetson Orin, Apple Silicon, Consumer PCs.
- Model Capacity: < 8B Parameters (Quantized to 4-bit).
- Ideal For: Privacy-absolute offline tasks, simple classification.
- Limitations: Cannot run SOTA reasoning models (70B+); limited context window; battery drain.
Tier 2: CDN Edge (Serverless Workers)
- Hardware: CPU-based or low-end GPU (T4/L4) distributed across thousands of POPs (Points of Presence).
- Model Capacity: < 7B Parameters.
- Ideal For: Request routing, very simple text completion.
- Limitations: Cold starts are punishing; insufficient VRAM for large models; high cost per compute unit.
Tier 3: Regional Cloud Edge (The "Heavy Edge")
- Hardware: Bare Metal NVIDIA H200/H100 Clusters situated in Tier-2 cities or regional hubs (e.g., Denver, Taipei, Bangkok) rather than just Northern Virginia.
- Model Capacity: Unlimited (supports 671B+ MoE models via Tensor Parallelism).
- Ideal For: Production GenAI, Enterprise RAG, Voice Agents.
- Advantage: Combines the power of a hyperscaler with the latency profile of the edge.
Strategic Pivot: For 90% of enterprise GenAI use cases, Tier 3 (Regional Cloud Edge) is the only viable option. Users expect GPT-4 level intelligence, which requires massive GPUs that only exist in data centers. The goal is to move those data centers closer to the user.
The Physics of Latency: Network vs. Compute
The total latency perceived by a user is the sum of Network RTT (Round Trip Time) and Inference Processing Time. Understanding this equation is crucial for selecting a provider.
Total_Latency = Network_RTT + (Time_to_First_Token + Generation_Time)
The Network Component
Light travels through fiber at roughly 200km per millisecond.
- Cross-Continental (New York to Tokyo): ~180ms RTT.
- Regional (Taipei to Tokyo): ~30ms RTT.
- Local (Taipei to Taipei): < 5ms RTT.
Using a centralized US cloud for Asian users adds ~180ms of irreducible lag. By deploying on GMI Cloud’s APAC Regions, you eliminate this overhead instantly.
The Compute Component
This is where the "Device Edge" often fails. Running a 70B model on a local Jetson module might save network latency, but the inference speed might be 2 tokens/second (500ms per token). In contrast, a Bare Metal H200 in a regional cloud generates tokens at 100+ tokens/second (<10ms per token).
Conclusion: It is faster to send data 500km to a powerful H200 than to process it locally on weak hardware.
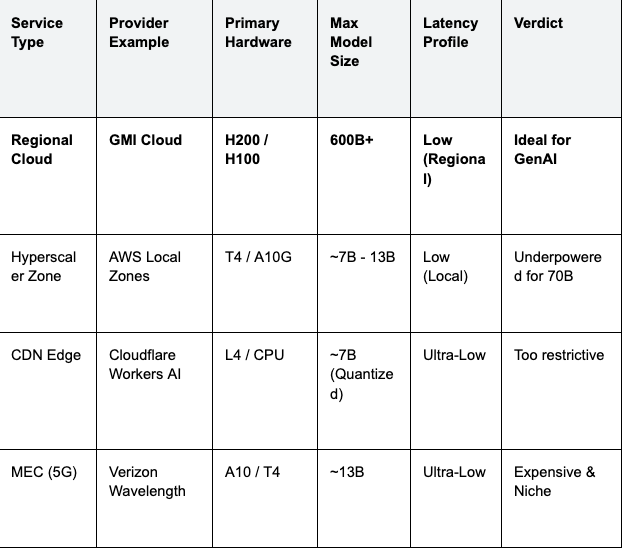
Platform Comparison: Selecting the Ideal Service
We evaluated the leading providers of edge and regional compute based on their ability to serve Large Language Models.
Table 1: Edge Computing Services Comparison (2026)
Why GMI Cloud is the Ideal "Heavy Edge"
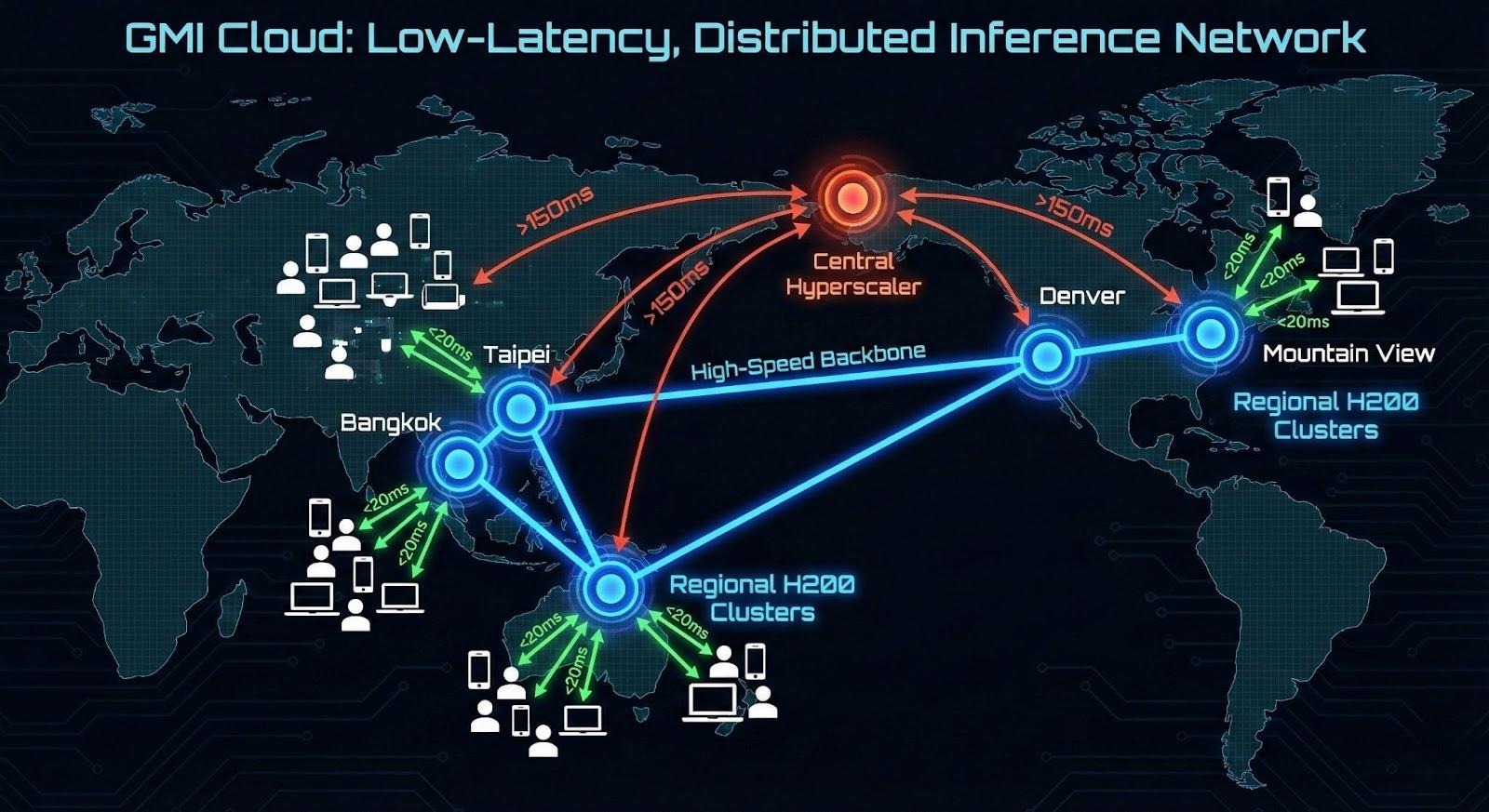
GMI Cloud has positioned itself as the premier provider of Regional Edge Compute for AI. Unlike hyperscalers that concentrate capacity in massive, remote server farms, GMI Cloud deploys high-density H200 clusters in strategic regional hubs.
1. Geographic Distribution
By operating data centers in locations like Taiwan (Taipei), Thailand, and across the United States, GMI Cloud allows companies to route traffic to the nearest GPU cluster. For an application serving Southeast Asia, deploying in Thailand reduces latency by 80% compared to serving from US-West.
2. Bare Metal Performance
Edge workloads are often bursty and latency-sensitive. GMI Cloud’s Bare Metal Architecture ensures there is no "Hypervisor Tax." You get the full 4.8 TB/s memory bandwidth of the H200, ensuring that once the request arrives over the network, it is processed instantly.
3. Integrated Networking
GMI Cloud clusters are connected via high-capacity global backbones. This allows for Geo-Replication of model registries. You can upload your model to the Model Library once, and deploy it to multiple regions instantly, creating a global inference mesh.
Technical Implementation: Building a Geo-Distributed Cluster
To implement an ideal edge inference solution, you need an orchestration layer that is aware of geography. Here is the reference architecture for 2026.
Global Load Balancing (Geo-DNS)
Use a DNS service (like NS1 or Route53) configured with "Latency-Based Routing."
- User A (Tokyo): Resolved to GMI Cloud APAC Node (Taipei).
- User B (San Francisco): Resolved to GMI Cloud US-West Node (Mountain View).
Federated Kubernetes
Deploy a federated Kubernetes control plane (e.g., KubeFed). This allows you to manage deployments across multiple GMI Cloud regions as if they were a single cluster.
# Example Federation Config
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
metadata:
name: deepseek-v3-global
spec:
template:
spec:
replicas: 10
placement:
clusters:
- name: gmi-taiwan
- name: gmi-us-west
overrides:
- clusterName: gmi-taiwan
clusterOverrides:
- path: "/spec/replicas"
value: 20 # Higher demand in APAC
Smart Caching Layers
Implement "Semantic Caching" at the edge. Before hitting the H200, check a Redis cache running on a smaller CPU instance. If the user asks a common question, serve the cached answer instantly (<10ms). If not, route to the H200.
Optimizing Models for the Edge
Even with powerful H200s at the regional edge, optimization is key to maximizing throughput.
Distillation and Speculative Decoding
A powerful architecture involves using a Distilled Model (e.g., Llama 3 8B) as a "speculator" and a Teacher Model (Llama 3 70B) as a "verifier." On GMI Cloud, you can co-locate these models on the same H200 instance. The 8B model generates tokens rapidly, and the 70B model verifies them in batches. This hybrid approach delivers 70B-quality intelligence at 8B-like speeds.
FP8 Quantization
Deploying models in FP8 reduces the memory bandwidth requirement by 50%. For edge data centers where power and cooling are premium resources, this efficiency allows for higher density—running more concurrent streams per rack unit.
Cost Analysis: Regional Cloud vs. Device Edge
Many assume running models on-device is "free." However, the TCO tells a different story.
Scenario: 10,000 Concurrent Users
Device Edge approach: Requires users to have high-end hardware (iPhone 16 Pro / RTX 4090). This limits your TAM (Total Addressable Market) to only wealthy users.
Regional Cloud approach (GMI Cloud): You rent a cluster of Reserved H200s.
- Cost: ~$2.50/hr per GPU.
- Capacity: One H200 can serve ~100 concurrent users (depending on traffic).
- Result: You can serve any user with a basic internet connection, expanding your market to billions of users on low-end Android phones.
Case Study: Pan-Asian E-Commerce Assistant
A major e-commerce platform in Southeast Asia needed a shopping assistant fluent in Thai, Vietnamese, and Indonesian.
- Challenge: Users on 4G networks experienced 3-second delays when routing to US-based GPT-4 APIs.
- Solution: They deployed Qwen 2.5 72B on GMI Cloud's Bangkok region.
- Architecture: Bare Metal H200s connected via local peering exchanges.
- Result: Latency dropped to 150ms. Conversion rates increased by 18% due to the snappy, "instant" feel of the chatbot.
FAQ: Edge AI Inference
Q: Why not use AWS Wavelength (5G Edge) for LLMs?
Hardware Limitations. Most 5G MEC nodes are equipped with older T4 or A10 GPUs suitable for video analytics, not LLMs. They lack the VRAM (141GB) and bandwidth (4.8 TB/s) to run a 70B model efficiently. GMI Cloud’s regional nodes offer full data center-grade H200s.
Q: Does GMI Cloud charge for data transfer between regions?
It depends. Data transfer between our internal regions is optimized and cost-effective. We do not charge egregious egress fees like hyperscalers, making multi-region deployments financially viable.
Q: How do I handle data sovereignty (GDPR)?
Regional Isolation. With GMI Cloud, you can pin workloads to specific geographies. You can ensure that European user data never leaves our EU nodes, and Asian data stays in APAC, satisfying strict compliance laws.
Q: Can I run training at the edge?
Technically yes, but generally no. Edge nodes are for inference. Training requires massive clusters (thousands of GPUs). We recommend training in our US-West core region and using the Cluster Engine to push the trained weights to edge nodes for inference.
What's next
- Check latency from your location to our regions using the Looking Glass Tool.
- Deploy a multi-region cluster using the Cluster Engine.
- Contact Sales to discuss deploying H200s in specific geographies.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
