
H100
Hopper · baseline
- Memory
- 80 GB HBM3
- Inference perf
- 1.0× (baseline)
The workhorse. General LLM and multimodal inference. Where most production workloads start.
Prime Inference gives you reserved GPU capacity, tuned per model, with the engineering partnership to turn a working prototype into a production system.
H100 · H200 · Blackwell
NVIDIA-validated hardware
99.9% uptime
Production SLA

Performance, reach, and elasticity — built for real production traffic, sized for any scale.
2× Higher
Top performance
Per-model runtime tuning — kernel, scheduling, and routing — delivers up to 2× the sustained throughput of a generic stack on leading open-source models.
Directional benchmark. Actual performance varies by model and workload.
3 Global Reach
Low latency
Single-tenant capacity across APAC, North America, and Europe. Region-pin for low TTFT, region-lock for residency — we fit the deployment to your market.
Industry-leading
Elastic by design
Burst absorbs spikes, quiet hours drain to save. We've already closed the gap most platforms can't — and we're pushing provisioning faster still.
Reserved capacity rewards real production traffic — and per-model runtime tuning compounds the advantage over time.
Per-model kernel, scheduling, and routing optimization — not a generic stack. Pick your model, we handle the engine.
Reserved GPUs stay warm with weights pre-loaded. Every call lands hot — no cold-start delay, no first-token jitter.
GPUs reserved only for your workload. No noisy neighbors, no contention under load, no shared-tier surprises.
Any open-source, fine-tuned, or proprietary weights. Load from Hugging Face, S3, or your own storage — onto a runtime built to serve it well.
Our inference engineers continuously tune the runtimes behind the most-deployed open-source models — so when you pick one, the kernel work is already done.
vLLM, TensorRT-LLM, and SGLang pre-tuned per GPU class. Quantization configurable. Multi-GPU orchestration handled.
Region-pin endpoints for first-token latency, or region-lock them for data residency.
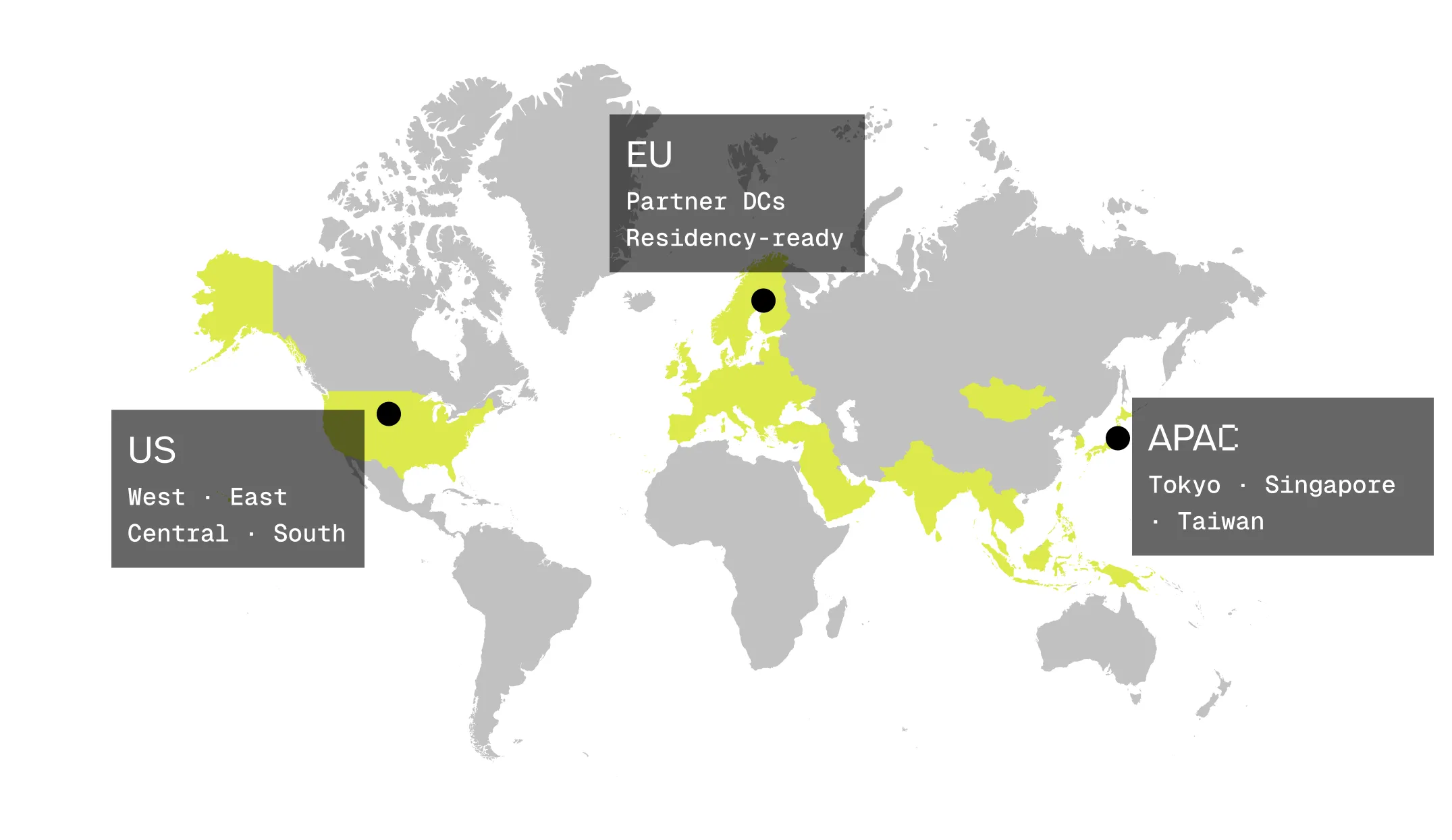
Tokyo · Singapore · Taiwan — serving the fastest-growing AI markets.
U.S. West, East, Central, and South — high-throughput production traffic.
EU partner data centers — residency and compliance-sensitive workloads.
Reserved capacity when you need guaranteed performance. Burst capacity when demand spikes. Drain when it doesn't. Pay only for what you actually use.
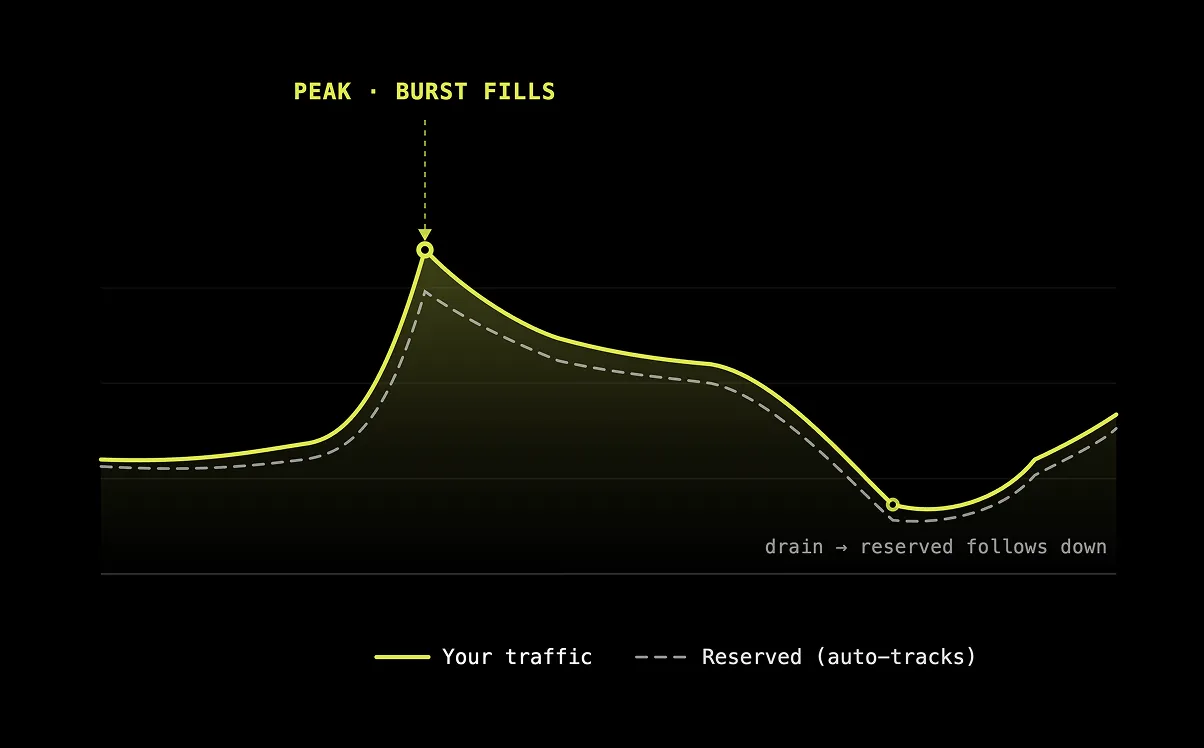
Spikes get absorbed automatically. No queueing, no manual scaling, no failed requests during demos or launches.
Quiet hours cost less. Capacity scales down gracefully without dropping in-flight calls.
When your home region hits capacity, traffic borrows from the next-closest region to keep latency low and service continuous.
Pick a model, pick the hardware, deploy. The platform handles model loading, resource orchestration, and routing — so you go from selection to a live API in minutes.
Any open-source model, anything from Hugging Face, or upload your own weights.
GPU type, GPU count per replica, replica count, and target region.
Launch from console, CLI, or API. Endpoint is live in minutes, not days.
Monitor latency and throughput. Burst when traffic spikes, drain when it doesn't.
One-click deployment for the leading open-source models — DeepSeek, Kimi, GLM, Llama, NVIDIA, and more. From frontier LLMs to vision, voice, and multimodal — pick a model, get a production endpoint.
deepseek-ai
moonshot-ai
zhipu-ai
meta-llama
nvidia
Production traffic patterns where predictability, throughput, and engineering partnership turn a working prototype into a reliable product.
Many short calls per task. First-call latency dominates user perception. Tool-use needs to be reliable, not just fast.
Stable endpoint per agent fleet · warm capacity · no cold-start during demos or launches.
Voice doesn't tolerate variability. Persistent WebSocket sessions on warm capacity. Region-pinned for short round-trips.
Sub-second first-byte TTS · streaming endpoints · no shared-tier jitter.
Sustain millions of daily queries with hardware-bounded throughput. Consistent tail latency on long-context workloads.
Optimized KV-cache · bounded P95/P99 · no shared-pool contention.
Isolated runtime, audit logs, zero-retention serving. Region-locked for finance, healthcare, public sector.
EU residency available · single-tenant isolation · enterprise SLAs.
Hopper, Hopper-refresh, and Blackwell — choose by memory footprint, context length, or frontier performance need.
Hopper · baseline
The workhorse. General LLM and multimodal inference. Where most production workloads start.

Hopper refresh
Memory-heavy workloads — long context, large KV-cache, big batch sizes.

Blackwell · frontier
Frontier models, FP4 inference, max throughput. For performance-critical workloads.
Frequently asked questions

Spin up a Prime Inference endpoint from the console — or contact sales about reserved capacity, custom tuning, and trial credits.