Cost-Effective AI Inference at Scale: A 2025 Benchmark & Strategy Guide
November 09, 2025

Conclusion (TL;DR): Achieving cost-effective AI inference in 2025 requires choosing the right platform and optimizations. Specialized providers like GMI Cloud offer on-demand H100 GPUs at rates up to 40-70% lower than hyperscalers. By leveraging a dedicated Inference Engine with features like automatic scaling, model quantization, and batching, businesses can dramatically reduce latency and compute costs, with real-world case studies showing 45-65% savings.
Key Takeaways:
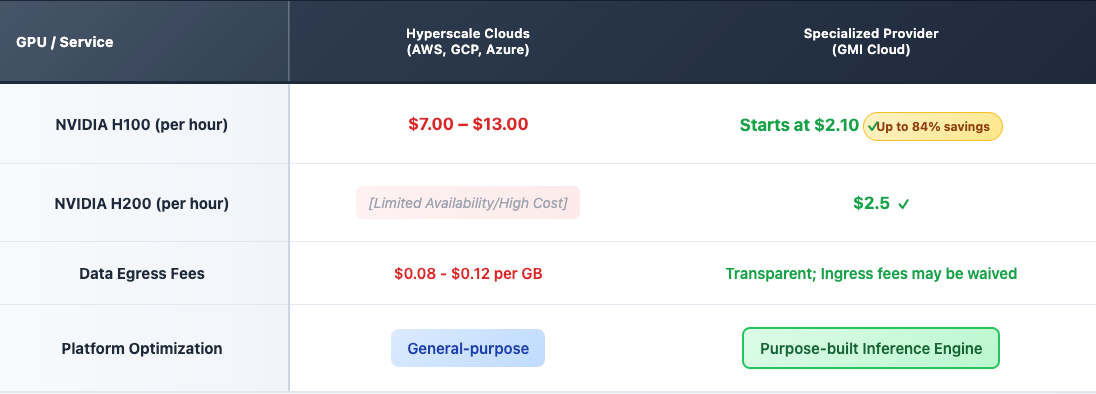
- Platform Choice is Key: Specialized GPU providers like GMI Cloud offer significantly lower hourly rates (e.g., H100s from $2.10/hour) compared to hyperscalers ($7.00-$13.00/hour).
- Optimization Techniques: Strategies like quantization, speculative decoding, and workload batching are essential for reducing the compute cost per request.
- Auto-Scaling is Crucial: A fully automatic scaling solution, like the GMI Cloud Inference Engine, prevents over-provisioning and ensures you only pay for the compute you use.
- Hidden Costs Matter: Hyperscale clouds often add 20-40% to bills via hidden data egress, storage, and networking fees. GMI Cloud offers transparent pricing and may negotiate or waive ingress fees.
- Proven Reductions: Real-world applications confirm these strategies work. Partners using GMI Cloud have achieved up to a 65% reduction in inference latency and 45-50% lower compute costs.
The 2025 AI Inference Cost Benchmark: Specialized vs. Hyperscale Clouds
For any AI application, inference compute represents a major, recurring operational cost. While major hyperscale clouds (like AWS, GCP, and Azure) offer convenience, it often comes at a significant premium.
The short answer: Specialized, high-performance GPU cloud providers typically offer superior pricing and performance for cost-effective AI inference.
Hyperscale clouds often have limited availability for top-tier GPUs and charge premium rates, with on-demand NVIDIA H100s costing between $4.00 and $8.00 per hour. Furthermore, their pricing models frequently include substantial hidden costs for data transfer (egress), storage, and networking, which can inflate a monthly bill by 20-40%.
In contrast, specialized providers like GMI Cloud focus on delivering raw GPU performance with transparent, lower-cost pricing.
Note: GMI Cloud offers on-demand NVIDIA H100 GPUs starting at just $2.10 per hour and H200 container instances at $3.35 per hour, providing the same (or better) hardware as hyperscalers for a fraction of the cost.
AI Inference Cost Benchmark (On-Demand)
Core Strategies for Cost-Effective AI Inference
Beyond raw hourly cost, how you run inference is critical. Implementing the right strategies can cut compute costs by over 50%.
Strategy 1: Utilize a Purpose-Built Inference Engine
Manually managing GPU clusters for inference is inefficient. It leads to idle, costly GPUs or, conversely, slow response times during traffic spikes.
A purpose-built platform like the GMI Cloud Inference Engine solves this. It is designed specifically for real-time AI inference at scale, providing two key cost-saving features:
- Fully Automatic Scaling: The engine automatically allocates resources according to workload demands, ensuring continuous performance without manual intervention. You never pay for idle capacity.
- Ultra-Low Latency: The infrastructure is optimized for speed, delivering faster, more reliable predictions. This is proven by partners like Higgsfield, who saw a 65% reduction in inference latency after switching to GMI Cloud.
Strategy 2: Implement Advanced Model Optimizations
Large models are expensive to run. The GMI Cloud platform is built to support end-to-end optimizations that reduce cost while maintaining speed.
- Quantization: This technique reduces the memory and compute requirements of your model. The GMI Cloud Inference Engine supports these optimized models.
- Speculative Decoding: This method helps improve serving speed and reduce cost at scale.
- Workload Batching: Strategically grouping inference requests minimizes overhead and maximizes GPU utilization.
Strategy 3: Right-Size Your GPU Instances
A common mistake is using oversized, expensive GPUs (like the H100) for tasks that could run on smaller, cheaper instances. Most inference workloads, unlike training, can perform exceptionally well on inference-optimized GPUs.
By choosing a provider like GMI Cloud, you gain access to a variety of top-tier GPUs, allowing you to "right-size" your hardware for your specific workload, from development to large-scale production.
Real-World Benchmarks: GMI Cloud Customer Success
The data confirms these strategies work. Businesses migrating to GMI Cloud see immediate and significant cost savings and performance gains.
- LegalSign.ai: Found GMI Cloud to be 50% more cost-effective than alternative cloud providers, drastically reducing AI training and inference expenses.
- Higgsfield: Achieved 45% lower compute costs compared to their prior provider. They also experienced a 65% reduction in inference latency, enabling a smoother real-time user experience.
- DeepTrin: By leveraging GMI Cloud's high-performance H200 GPUs, the company boosted its LLM inference accuracy and efficiency by 10-15%.
Conclusion: How to Start Optimizing Your Inference Costs Today
The path to cost-effective AI inference is clear: move away from the high costs and hidden fees of general-purpose hyperscalers.
Platforms built specifically for AI, like GMI Cloud, provide the solution. GMI Cloud combines a high-performance, auto-scaling Inference Engine with industry-leading, transparent pricing on the market's most advanced GPUs. By choosing a specialized partner, you can stop overpaying for compute and focus on building your application.
Frequently Asked Questions (FAQ)
What is the biggest hidden cost in AI inference?
Answer: The most common hidden costs are data transfer (egress) fees and paying for idle GPU time. Hyperscalers may charge $0.08-$0.12 per GB for data egress, and idle GPUs can waste 30-50% of your budget.
How much cheaper is GMI Cloud than AWS or GCP for inference?
Answer: GMI Cloud's on-demand H100 GPUs start at $2.10/hour, which can be 40-70% cheaper than hyperscaler rates of $4.00-$8.00/hour for the same hardware.
What is an Inference Engine?
Answer: It is a specialized platform, like the GMI Cloud Inference Engine, designed to deploy and serve AI models efficiently. It focuses on providing ultra-low latency and fully automatic scaling to handle real-time requests cost-effectively.
Does "cost-effective" mean lower performance?
Answer: No. A truly cost-effective platform optimizes performance. GMI Cloud partners report reduced latency (by 65%) and increased model efficiency (by 10-15%) after migrating.
How does GMI Cloud optimize inference?
Answer: GMI Cloud's Inference Engine uses end-to-end hardware and software optimizations, including support for techniques like quantization and speculative decoding, combined with intelligent, automatic scaling to ensure peak performance at the lowest possible cost.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
