GMI Cloud vs. Nebius: The best GPU cloud for startups
This article compares GMI Cloud and Nebius as GPU cloud platforms for AI startups. While Nebius prioritizes simplicity and quick onboarding, GMI Cloud delivers enterprise-grade control, scalability, and cost optimization, making it ideal for startups planning long-term growth and global reach.
October 31, 2025

This article compares GMI Cloud and Nebius to help AI startups choose the best GPU cloud platform for performance, scalability, and cost efficiency. While Nebius offers simplicity and fast onboarding, GMI Cloud provides enterprise-grade control, flexible scaling, and optimized infrastructure designed to support long-term growth and global expansion.
What you’ll learn:
• The key differences between GMI Cloud and Nebius for AI startup workloads
• How GMI Cloud’s hybrid pricing and high-performance GPUs lower long-term costs
• Why inference latency and scalability are critical for real-time AI products
• How GMI Cloud’s Inference and Cluster Engines deliver fine-grained control
• When simplicity (Nebius) vs. flexibility (GMI Cloud) is the better choice
• How startup infrastructure choices impact future scalability and ROI
• Why many teams migrate from general-purpose clouds to GMI Cloud as they grow
For AI startups, infrastructure isn’t just a backend decision – it’s a strategic lever. The right GPU cloud provider can accelerate development, keep costs predictable and help teams scale globally without burning capital. The wrong choice can lock you into rigid architectures, unexpected bills and painful migrations down the line.
Two platforms that often enter this conversation are GMI Cloud and Nebius. Both provide GPU-powered infrastructure, but they differ in philosophy, pricing, flexibility and how they support early-stage companies.
This article breaks down those differences so founders and technical leads can make an informed, long-term decision.
Two platforms, two approaches
GMI Cloud positions itself as a GPU-first cloud designed for high-performance AI workloads – with a particular emphasis on inference, scalability and flexibility. Its model is built to give startups control over their compute, while keeping operations lean and predictable.
Nebius, on the other hand, presents itself as a general-purpose cloud with strong support for AI, built around a developer-friendly experience and integrations that appeal to teams getting started quickly. It’s part of the growing wave of platforms aiming to make access to compute simpler, faster and more cost-efficient.
Both offer GPU infrastructure, but the way they deliver and optimize it is fundamentally different.
Speed to deployment
Startups need to get models into production fast. Delays in provisioning or scaling infrastructure can cost valuable market momentum.
Nebius offers a smooth onboarding process and accessible APIs. It’s designed to get teams up and running quickly with minimal friction. For teams that want to start small and ramp up as they go, this is an attractive entry point.
GMI Cloud is equally focused on fast provisioning – but it emphasizes fine-grained control from the start. Teams can deploy GPUs in minutes, configure environments according to workload needs, and scale with precision.
The difference is subtle but meaningful: Nebius makes it easy to get started; GMI Cloud makes it easy to stay in control as complexity grows.
Performance and latency
Inference latency can make or break AI products. Whether it’s a chatbot, a computer vision system or an API serving customers worldwide, startups need performance that’s both fast and consistent.
Nebius offers solid performance for general workloads and provides GPU-backed compute that suits most early-stage use cases. However, like many general-purpose clouds, its architecture is built to serve a broad customer base, which can mean less fine-tuning for high-throughput inference scenarios.
GMI Cloud, in contrast, was purpose-built for inference. Its high-bandwidth networking, dedicated GPU resources, and optimized orchestration minimize latency even under heavy load. Startups running real-time applications – where every millisecond counts – benefit from more predictable, low-latency performance.
Cost models and startup economics
Cost is often the single biggest constraint for AI startups. On-premise deployments are capital-intensive, and cloud spending can spiral if not carefully managed.
Nebius promotes transparent, competitive pricing aimed at making compute more accessible. Its pay-as-you-go model suits teams with small or fluctuating workloads. For early prototyping and initial deployments, this can be cost-efficient and straightforward.
GMI Cloud takes a hybrid approach with reserved and on-demand GPU options:
- Reserved capacity comes with lower hourly rates for predictable baseline usage.
- On-demand capacity supports traffic spikes without locking startups into fixed costs.
This hybrid structure aligns infrastructure spending with actual business activity – an important advantage for startups that can’t afford to overpay for idle capacity or underprovision during peak demand.
Scalability and elasticity
Startups grow fast, often unpredictably. A successful launch can turn yesterday’s small prototype into today’s global product. Infrastructure that can’t keep up becomes a bottleneck.
Nebius offers scalable infrastructure and supports elastic expansion, but its scaling options are designed to remain user-friendly rather than deeply customizable. This is excellent for teams that want simplicity but may become limiting as workloads grow in complexity.
GMI Cloud is designed for elastic scaling at speed. Teams can burst capacity on demand, run distributed training or inference workloads, and maintain performance under pressure. Startups that aim to handle large inference volumes, global traffic or enterprise contracts benefit from the control over when, where and how scaling happens.
Flexibility and control
For many early-stage teams, the first product is just the beginning. Infrastructure choices made in the first six months often shape what’s possible in the next two years.
Nebius abstracts much of the complexity away. That’s a plus for speed – but it can limit how much teams can customize their stack as they mature. Advanced configurations, workload partitioning or complex orchestration may be harder to implement without additional tooling.
GMI Cloud is built for infrastructure maturity. Startups can:
- Deploy custom and fine-tuned models.
- Control serving configurations.
- Integrate their preferred orchestration tools.
- Adjust caching, batching and scaling policies.
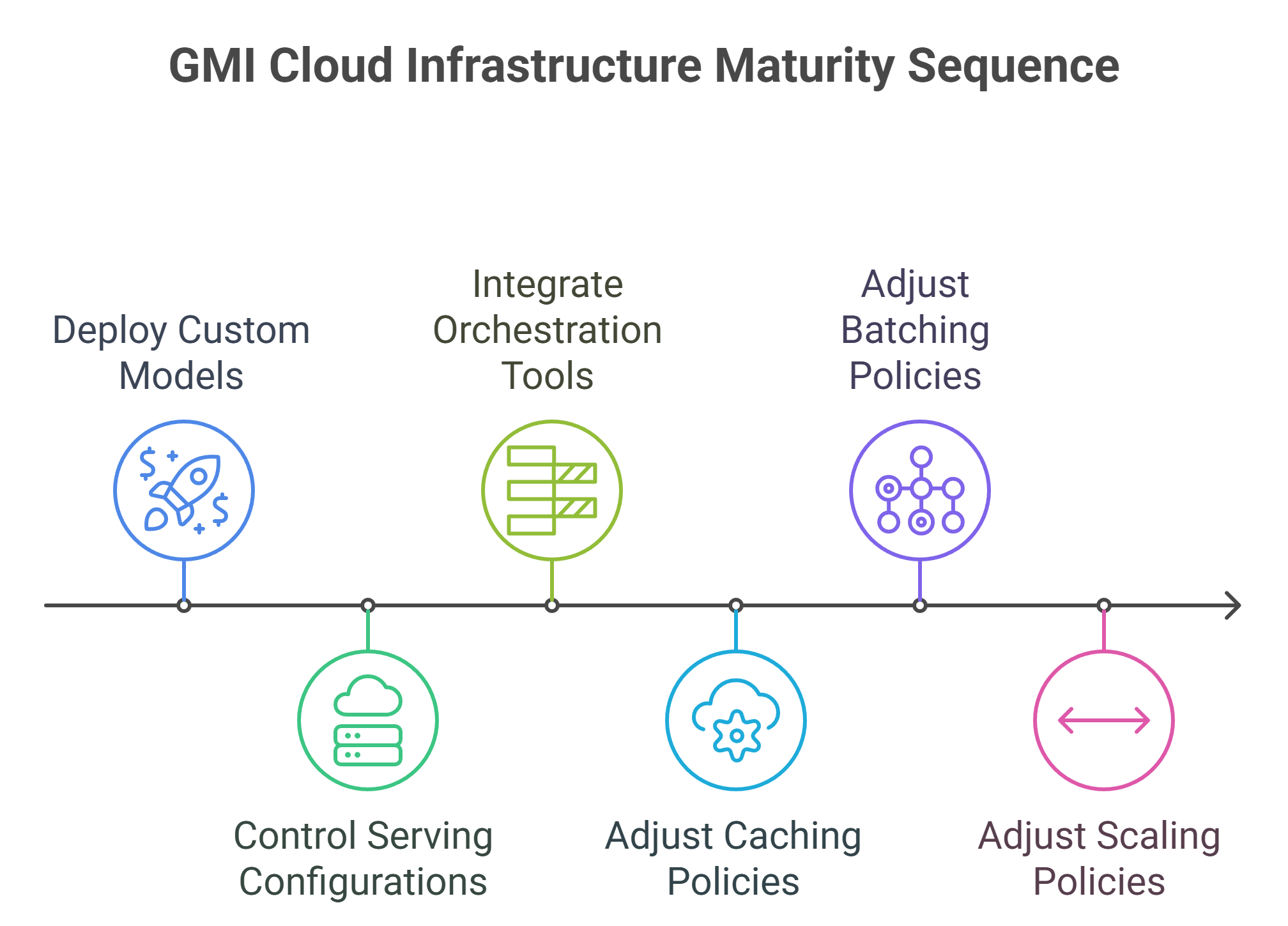
This level of flexibility ensures teams aren’t boxed in as their needs evolve.
Integration with MLOps workflows
Inference doesn’t happen in isolation – it sits inside a broader ML lifecycle that includes training, retraining, versioning and monitoring.
Nebius provides solid developer tools and basic MLOps integration, which is ideal for startups focused on prototyping or early launches.
GMI Cloud takes a more advanced stance, integrating seamlessly with modern MLOps frameworks, Kubernetes orchestration, CI/CD workflows and observability stacks. Its Inference Engine is purpose-built for high-performance model serving, enabling startups to deploy and scale LLMs and other AI workloads with minimal overhead. Combined with Cluster Engine for intelligent scheduling and dynamic resource allocation, this setup allows teams to automate deployment, monitor cost and performance in real time, and maintain operational efficiency as they grow.
Security and compliance
As AI products move into sensitive sectors – from healthcare to finance – startups need to demonstrate that their infrastructure can handle data securely.
Nebius provides standard cloud security features and compliance certifications suitable for most early-stage applications.
GMI Cloud adds enterprise-grade security features, including SOC 2 certification, role-based access control, and encrypted storage. Startups planning to work with regulated industries or sensitive data benefit from this stronger compliance posture without having to build it themselves.
Geographic reach and latency
Many startups build products for a global user base from day one. Infrastructure that only lives in a single region can create latency and reliability issues as traffic grows.
Nebius provides multi-region support but with more limited geographic control.
GMI Cloud gives startups more precise region selection and low-latency global reach, allowing them to deploy workloads close to users. This flexibility supports real-time applications and global scaling without additional complexity.
Developer experience
Nebius stands out for its ease of use. Its clean interface and API-first approach make it appealing to smaller teams without dedicated infrastructure engineers. It’s a good fit for fast-moving startups that need to get their MVPs out quickly.
GMI Cloud’s developer experience is built around fine-grained control. It offers intuitive provisioning but also provides hooks for teams that want to customize orchestration, optimize performance, or integrate with advanced tooling. It’s more powerful for teams that are either infrastructure-savvy or plan to scale fast.
Choosing what fits your growth path
The best platform for your startup depends on your trajectory, not just your current workload.
- Choose Nebius if:
- You want a fast, easy entry point into GPU cloud.
- Your workloads are moderate and predictable.
- Simplicity outweighs the need for deep customization.
- You’re focused on early MVPs and rapid iteration.
- Choose GMI Cloud if:
- Performance, cost optimization and global scale matter.
- You need full control over GPU infrastructure.
- You’re integrating inference into a mature or growing MLOps stack.
- You want flexibility to scale without vendor lock-in.
The long game for startups
In the early days, ease of use often wins. But as AI startups grow, control, scalability and cost optimization become make-or-break factors. Nebius offers a great starting point for teams prioritizing simplicity. GMI Cloud provides a foundation that scales with ambition.
Many successful startups follow a familiar pattern: launch on a platform like Nebius, then migrate to something more flexible as workloads – and stakes – rise. Others start directly on GMI Cloud to avoid the pain of replatforming down the road.
In a world where speed is critical but long-term scalability defines winners, making this decision early – and wisely – can shape the entire trajectory of your AI business.
Frequently Asked Questions About GMI Cloud Versus Nebius for Startup GPU Infrastructure
1. What is the main difference between GMI Cloud and Nebius for startups?
GMI Cloud focuses on enterprise-grade control, scalability, and cost optimization for high-performance AI (especially inference). Nebius prioritizes simplicity and fast onboarding with developer-friendly tools. Both offer GPU infrastructure, but GMI Cloud is built to keep you in control as complexity and scale grow, while Nebius makes it very easy to get started.
2. Which platform is better for low-latency inference and consistent performance?
GMI Cloud is purpose-built for inference with high-bandwidth networking, dedicated GPU resources, and optimized orchestration to minimize latency under heavy load. Nebius provides solid performance for general workloads, but its general-purpose architecture is less tuned for high-throughput inference scenarios.
3. How do pricing and cost models differ for early-stage teams?
Nebius offers transparent, competitive pay-as-you-go pricing that works well for small or fluctuating workloads. GMI Cloud uses a hybrid approach: reserved capacity (lower hourly rates for predictable baselines) plus on-demand capacity (to handle spikes). This lets startups align spend with real business activity without overpaying for idle capacity.
4. What should I consider for scalability and elasticity as my product grows?
Nebius supports elastic expansion with a strong emphasis on ease of use. GMI Cloud is designed for elastic scaling at speed, including distributed training or inference, precise burst capacity, and control over where and how workloads scale—useful for global traffic, large inference volumes, or enterprise contracts.
5. How do GMI Cloud and Nebius compare on flexibility, MLOps integration, and developer experience?
Nebius abstracts complexity for fast MVPs and straightforward APIs. GMI Cloud emphasizes fine-grained control: custom and fine-tuned model serving, control of serving configurations, caching, batching, and scaling policies, plus integrations with modern MLOps frameworks, Kubernetes, CI/CD, observability, an Inference Engine for high-performance serving, and a Cluster Engine for intelligent scheduling.
6. What about security, compliance, and geographic reach for global users?
Nebius provides standard cloud security features and compliance suitable for most early-stage use cases. GMI Cloud adds enterprise-grade security such as SOC 2, role-based access control, and encrypted storage, along with more precise region selection for low-latency global reach—helpful for teams targeting regulated industries or worldwide users.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
