How to Deploy the Kimi K2 Model on the Cloud: A 2026 Guide to GPU Infrastructure
April 14, 2026

TL;DR (Answer First): Deploying the 1-trillion parameter Kimi K2 model requires specialized cloud infrastructure due to its complex Mixture-of-Experts (MoE) architecture. Success depends on access to high-end GPUs (NVIDIA H100, H200, and next-generation Blackwell systems including NVIDIA GB200 NVL72, NVIDIA GB200 NVL4, and NVIDIA HGX™ B300), low-latency networking like InfiniBand, and robust orchestration. While API-based options exist, a specialized GPU provider like GMI Cloud offers an optimized, cost-effective path with its auto-scaling Inference Engine and instant access to dedicated H200 GPU clusters.
Key Takeaways:
- Massive Scale: Kimi K2's 1-trillion parameter MoE design demands massive GPU memory and advanced parallel processing (Tensor, Expert Parallelism).
- Core Challenges: The primary obstacles are managing inference latency, high GPU costs, and complex deployment orchestration.
- Infrastructure is Key: Standard cloud VMs are inefficient. You need a platform built for large-scale AI, featuring InfiniBand networking and top-tier GPUs such as NVIDIA H100, H200, and Blackwell systems (GB200 NVL72, GB200 NVL4, HGX™ B300).
- GMI Cloud Solution: GMI Cloud provides a purpose-built solution with two key services: the Inference Engine for ultra-low latency, auto-scaling endpoints and the Cluster Engine for full orchestration control (K8s) on bare-metal H100/H200 GPUs.
- Platform Choice: Your choice ranges from simple (but inflexible) Model APIs to powerful (but complex) DIY paths. GMI Cloud offers a balance of power, control, and ease of use.
I. The Challenge: Deploying the Kimi K2 Behemoth
Why can’t you deploy Kimi K2 on standard cloud VMs?
Because Kimi K2’s 1-trillion parameter Mixture-of-Experts architecture requires distributed GPU clusters, high VRAM capacity, and ultra-low-latency networking like InfiniBand. Standard cloud VMs lack the interconnect bandwidth and orchestration capabilities needed for efficient expert parallelism, leading to high latency and excessive costs.
The Kimi K2 model represents a significant leap in AI, reportedly featuring a 1-trillion parameter Mixture-of-Experts (MoE) architecture. This design, combined with a long context window and multi-tool capabilities, makes it incredibly powerful.
However, these capabilities create enormous technical challenges for deployment:
- Extreme GPU Demand: MoE models require immense VRAM to hold all experts, even if only a few are active per token.
- Latency & Throughput: Coordinating multiple "expert" models across different GPUs or nodes demands ultra-low latency networking to avoid bottlenecks.
- Complex Orchestration: Efficiently routing requests to the correct experts (Expert Parallelism) is far more complex than deploying a single dense model.
- Cost Management: Running large clusters of H100, H200, or Blackwell GPUs (such as GB200 NVL72 or HGX™ B300 systems) 24/7 is prohibitively expensive without optimized, auto-scaling infrastructure.
- Security & Compliance: Enterprises must ensure this powerful model runs in a secure, compliant environment.
Choosing the right cloud provider is not just a preference; it's the most critical factor determining if your Kimi K2 deployment will succeed or fail.
II. Key Technical Considerations to Deploy the Kimi K2 Model on Cloud
What infrastructure is required to run a 1T-parameter MoE model like Kimi K2?
Deploying Kimi K2 requires multi-GPU clusters using NVIDIA H100 or H200 GPUs, support for tensor, data, and expert parallelism, InfiniBand networking for low-latency communication, Kubernetes-based orchestration, and automated scaling to manage cost and performance efficiently.
Before selecting a platform, you must verify it can meet these non-negotiable technical demands.
Model Specifications & Resource Needs
The MoE architecture means the full 1T parameters are not all active at once. However, the infrastructure must support the high-memory footprint and the complex routing logic. This requires a platform that excels at distributed computing.
Inference and Parallelism
You cannot run Kimi K2 on a single GPU. Deployment requires a sophisticated combination of parallelism strategies:
- Tensor Parallelism: Splitting a single model layer across multiple GPUs.
- Data Parallelism: Replicating the model to handle multiple requests simultaneously.
- Expert Parallelism: Distributing the "experts" across different GPUs/nodes, which is essential for MoE models.
Essential Cloud Platform Capabilities
Your cloud provider must offer:
- Top-Tier GPUs: Instant, on-demand access to NVIDIA GPUs is mandatory. GMI Cloud, for example, offers dedicated H200 GPUs on-demand.
- High-Speed Networking: Standard Ethernet is too slow. You need high-throughput, low-latency interconnects like InfiniBand to connect GPUs.
- Intelligent Orchestration: The platform must support Kubernetes (K8s) or a similar system to manage complex containerized workloads across clusters.
- Automated Scaling: The ability to scale resources (especially for inference) automatically based on demand is crucial for cost control.
Enterprise Operational Needs
Beyond raw power, enterprises need:
- Cost Control: A flexible, pay-as-you-go model is ideal. GMI Cloud's H200 container instances are priced as low as $2.6/GPU-hour.
- Security & Compliance: Look for providers with SOC 2 certification and features like VPCs, RBAC, and isolated multi-tenant architecture.
- Monitoring: Real-time monitoring of GPU usage, latency, and throughput is essential for optimization.
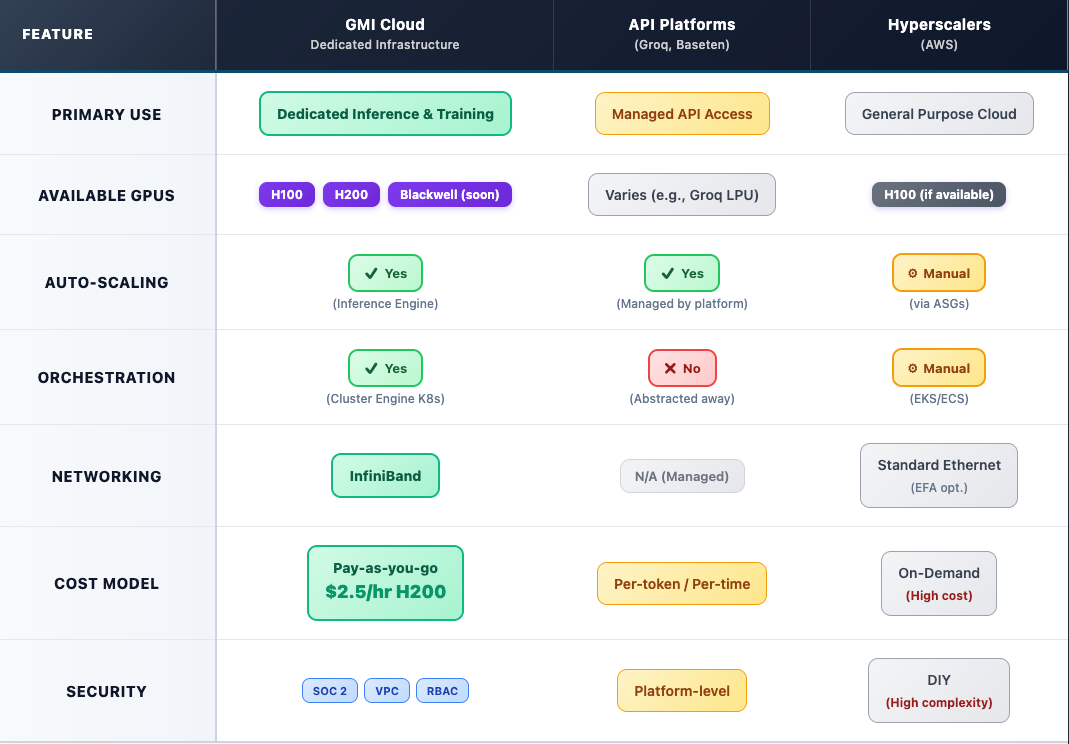
III. Comparison of Cloud Providers for Kimi K2 Deployment
Should you use a Model API platform or dedicated GPU infrastructure for Kimi K2?
Model APIs are easier to use but offer limited control over cost, customization, and infrastructure. Dedicated GPU platforms like GMI Cloud provide full control over hardware, networking, scaling, and security, which is essential for production-grade deployment of large MoE models.
When you deploy the Kimi K2 model on the cloud, your options fall into three categories. We'll use GMI Cloud as the benchmark for specialized infrastructure, as its entire platform is built for this type of workload.
GMI Cloud: Optimized Infrastructure for MoE
GMI Cloud provides a complete ecosystem optimized for large-scale AI.
- GMI Inference Engine (IE): This service is purpose-built for real-time, low-latency inference. It supports fully automatic scaling, dynamically allocating resources to meet demand without manual intervention. This is ideal for serving Kimi K2's API.
- GMI Cluster Engine (CE): For teams needing full control, the CE provides a robust Al/ML Ops environment. It uses Kubernetes to orchestrate workloads on bare-metal (CE-BMaaS) or containerized (CE-CaaS) H100/H200 instances, all connected via InfiniBand.
- Hardware: GMI offers instant access to NVIDIA H200 GPUs as well as next-generation Blackwell systems including NVIDIA GB200 NVL72, NVIDIA GB200 NVL4, and NVIDIA HGX™ B300, ensuring you have the best hardware for large-scale MoE models.
API-Centric Platforms (Groq, Baseten)
These platforms offer Kimi K2 "as-a-service."
- Groq Cloud: Known for its LPU-based inference, Groq offers API access to the Kimi K2 Instruct model. This is excellent for high speed but offers little customization.
- Baseten: Baseten provides a Model API and deployment stack. It allows you to run open-source models like Kimi K2 on their infrastructure, but you are tied to their specific environment.
Key Difference: These platforms are user-friendly for API calls but provide less control over the underlying infrastructure, cost, and security compared to GMI Cloud's dedicated engine approach.
General Hyperscalers (AWS)
This is the "Do-It-Yourself" (DIY) path. You can rent EC2 instances with H100 GPUs and build the entire deployment stack using Docker, Kubernetes, and custom scripts.
- Pros: Full control.
- Cons: Extremely complex, high cost, and slow to provision. Case studies have shown that specialized providers like GMI Cloud can be 50% more cost-effective than traditional hyperscalers for AI training and reduce compute costs by 45%.
Provider Comparison Table
IV. Deep Dive: Why GMI Cloud Excels for Kimi K2 Deployment
GMI Cloud's platform directly addresses the core challenges of MoE models.
The GMI Inference Engine: Built for MoE Latency
Why is auto-scaling critical when deploying Kimi K2 in production?
Kimi K2 workloads fluctuate significantly depending on user demand. Without auto-scaling, clusters run idle and waste GPU budget. An optimized inference platform dynamically allocates resources based on traffic, reducing costs while maintaining low latency and high throughput.
Kimi K2's performance is defined by latency. The GMI Inference Engine is optimized for this single purpose, delivering ultra-low latency and high throughput. Its intelligent auto-scaling means you only pay for the exact compute needed to serve your users, drastically reducing costs compared to idle, provisioned clusters. It also supports optimizations like quantization to further boost speed.
The GMI Cluster Engine: Full Orchestration Control
For R&D and custom deployments, the Cluster Engine (CE) provides the power of a supercomputer with the flexibility of the cloud. You can provision bare-metal H200 servers (CE-BMaaS) connected with InfiniBand to build your own Expert Parallelism strategy. Or, use the K8s-native container service (CE-CaaS) for rapid, automated deployment of your model.
Unmatched Hardware Access and Cost-Efficiency
GMI Cloud's status as an NVIDIA Reference Cloud Platform Provider allows it to offer instant access to the latest GPUs like the H200. This eliminates the hardware waitlists common on other platforms. This access, combined with a pay-as-you-go model and proven cost savings of 45-50% over alternatives, makes it the most financially sound choice for startups and enterprises.
Proven Success with Large Language Models
GMI Cloud has a track record of optimizing complex AI workloads. In a partnership with DeepTrin, GMI's platform increased LLM inference accuracy and efficiency by 10-15% and accelerated their go-to-market timeline by 15%.
Call to Action: Ready to deploy Kimi K2 without the complexity? Contact GMI Cloud to get instant access to H200 GPU clusters.
V. Roadmap and Best Practices for Kimi K2 Production
Follow these steps for a successful deployment.
Step 1: Initial Deployment and Testing
Start with the GMI Cluster Engine's CaaS (Container) service. Use a single H200 node to test your containerized Kimi K2 model, ensuring all dependencies and parallelism logic function correctly.
Step 2: Scaling for Performance
Move to a multi-node cluster using the CE's bare-metal (BMaaS) service with InfiniBand networking. This is where you will fine-tune your Expert Parallelism strategy for maximum throughput.
Step 3: Production API Deployment
Once optimized, deploy your model to the GMI Inference Engine. This will provide a durable, auto-scaling, and low-latency API endpoint for your application, complete with real-time monitoring.
Best Practices Checklist
How can you control costs when running large-scale models like Kimi K2?
Use pay-as-you-go GPU pricing, right-size cluster configurations, implement quantization and speculative decoding, monitor GPU utilization in real time, and separate development clusters from production inference. Specialized platforms designed for AI infrastructure help prevent over-provisioning and reduce idle GPU waste.
- Monitor Everything: Use GMI's real-time monitoring tools to track GPU utilization, latency, and costs.
- Secure by Default: Implement Role-Based Access Control (RBAC) and use separate VPCs for your deployment. GMI Cloud's SOC 2 certification provides a secure foundation.
- Optimize Models: Use techniques like quantization and speculative decoding to reduce the computational load.
- Right-Size Your GPUs: Don't default to the largest cluster. Use GMI's pay-as-you-go flexibility to find the perfect price-to-performance ratio.
VI. Conclusion: Your Infrastructure Choice Defines Your Success
Deploying the Kimi K2 model on the cloud is one of the most demanding AI infrastructure challenges today. Its 1-trillion parameter MoE architecture pushes standard cloud providers past their limits, resulting in high latency, runaway costs, and deployment failures.
Success requires a new class of provider. Specialized, AI-native platforms like GMI Cloud are not just an option; they are a necessity. By providing an integrated ecosystem of instant-access H200 GPUs, InfiniBand networking, and purpose-built services like the Inference Engine and Cluster Engine, GMI Cloud removes the infrastructure barriers, allowing you to focus on innovation.
If you are serious about using Kimi K2 or similar MoE models in production, don't let infrastructure be your bottleneck.
Final Call to Action: Explore GMI Cloud's Inference and Cluster Engines to see how you can deploy Kimi K2 with industry-leading performance and cost-efficiency.
Frequently Asked Questions (FAQ)
What is the Kimi K2 model?
Kimi K2 is a reported 1-trillion parameter large language model that uses a Mixture-of-Experts (MoE) architecture. This allows it to be extremely powerful while managing computational load by only activating a subset of its "experts" for any given task.
Why is it so difficult to deploy the Kimi K2 model on the cloud?
Its MoE design and massive size require a distributed cluster of high-end GPUs (like NVIDIA H100, H200, or Blackwell systems such as GB200 NVL72, GB200 NVL4, and HGX™ B300) with extremely fast, low-latency networking (like InfiniBand) to connect them. Standard cloud infrastructure cannot handle this complexity efficiently, leading to high latency and costs.
What is the best GPU for deploying Kimi K2?
The NVIDIA H100 or H200 GPUs are considered the best choice. The H200, with its 141GB of HBM3e memory, is particularly well-suited for holding Kimi K2's large expert models. GMI Cloud offers on-demand access to both H100 and H200 GPUs.
How does GMI Cloud help deploy Kimi K2?
GMI Cloud offers two specialized services: 1) The Inference Engine provides a fully-managed, auto-scaling endpoint for low-latency inference. 2) The Cluster Engine provides full K8s orchestration on bare-metal H200 clusters with InfiniBand networking, giving you the power and control needed for complex MoE routing.
How much does it cost to deploy Kimi K2 on GMI Cloud?
GMI Cloud uses a flexible, pay-as-you-go model. As a reference, on-demand NVIDIA H200 GPUs are listed at $2.60/GPU-hour. Case studies show GMI Cloud can be 45-50% more cost-effective than hyperscalers.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
