
Artificial intelligence has moved far beyond the experimental phase of building and training models. The real test comes when those models are deployed into live environments, making decisions in real time. Whether it is a voice assistant responding in milliseconds, a fraud detection system analyzing thousands of transactions per second, or a recommendation engine adapting instantly to user behavior, AI inference is where the practical value of AI emerges.
In particular, real-time inference has become a defining capability for organizations that rely on speed and scale. As adoption accelerates, the ability to deliver results instantly is no longer just a feature – it is a competitive advantage. This is where running inference workloads on GPU cloud infrastructure becomes essential. GMI Cloud provides an inference-optimized platform designed to meet these needs, ensuring models run with the performance, efficiency, and reliability that modern applications demand.
Understanding AI inference and real-time needs
AI inference takes a model trained on large datasets and applies it to new data in order to deliver predictions. For example, a recommendation engine uses inference to suggest products, or a computer vision model uses it to recognize objects in images.
Real-time inference adds an additional requirement – low latency. This means the system must deliver results almost instantly, often within milliseconds. Consider self-driving cars, fraud detection in financial transactions, or chatbots providing live customer support. In all these cases, delays can reduce effectiveness or even create risks.
Meeting such requirements pushes beyond the limits of traditional CPU-based systems. While CPUs can handle inference, they are often slower when the workload involves the massive parallel processing required by deep learning models. This is where GPUs come in.
Why GPUs are better suited for inference
GPUs (graphics processing units) were originally designed for rendering images and graphics. However, their architecture – capable of handling thousands of operations in parallel – makes them ideal for deep learning tasks. Compared to CPUs, GPUs excel in situations where large volumes of data need to be processed simultaneously.
When deployed for AI inference, GPUs can significantly reduce latency, enabling real-time performance even with complex models. This makes them particularly valuable for industries that require instant decision-making, such as healthcare, finance, manufacturing, or autonomous systems.
Moreover, GPU cloud platforms allow organizations to scale their inference workloads seamlessly. Instead of investing in expensive hardware upfront, businesses can access GPU resources on demand, paying only for what they use.
The role of cloud in real-time inference
Running inference on-premises can be resource-intensive, requiring constant upgrades, high energy consumption, and dedicated maintenance. Cloud computing addresses these challenges by offering elastic access to GPU infrastructure. This flexibility ensures that workloads can scale according to demand – for example, an e-commerce platform needing more computing power during holiday sales.
A GPU cloud also simplifies deployment. Developers can integrate models into production environments without worrying about managing hardware. They can use preconfigured environments optimized for AI inference, reducing setup time and accelerating time to market.
Additionally, cloud platforms often provide tools for monitoring, scaling, and optimizing inference workloads, allowing organizations to balance performance and cost.
Integrating inference into the AI lifecycle
Real-time inference is just one part of a larger AI lifecycle, which begins with training a model on large datasets, validating its accuracy, and then deploying it into a production environment. Once deployed, the model moves into the inference stage, where it processes real-world data. However, this is not the end of the process. Ongoing monitoring and optimization are essential to ensure that the model continues to perform well over time and adapts to new patterns in the data.
Running both training and inference on cloud GPUs can streamline this lifecycle. Using similar infrastructure for both stages reduces complexity and allows teams to move models from development to production more quickly. GMI Cloud’s unified platform makes it possible to manage the entire AI workflow in a single environment, eliminating friction between R&D and deployment. For further insights into inference best practices, see NVIDIA’s AI inference whitepaper.
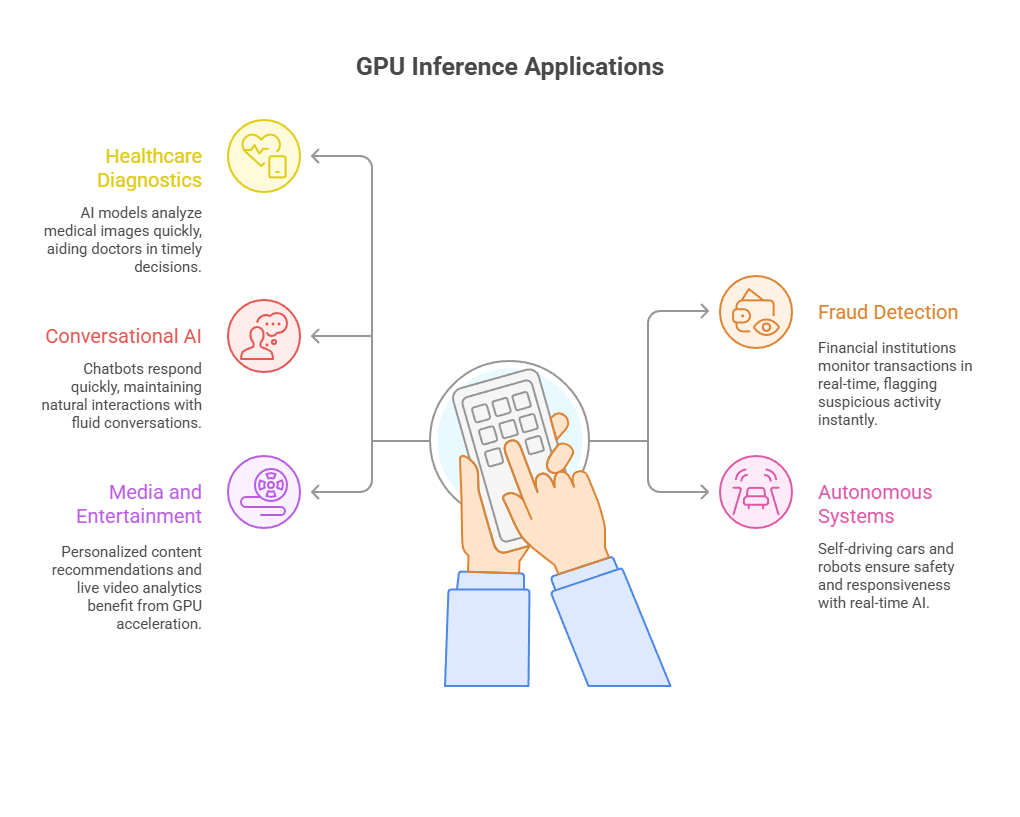
Real-world applications of real-time GPU inference
The benefits of GPU-powered inference are most evident in practical use cases:
- Healthcare diagnostics: AI models analyzing medical images rely on low latency to support rapid diagnosis. A cloud-based GPU system can process scans in seconds, helping doctors make timely decisions.
- Fraud detection: Financial institutions use real-time inference to monitor transactions. With GPU inference, suspicious activity can be flagged instantly before damage occurs.
- Conversational AI: Chatbots and virtual assistants must respond quickly to maintain a natural interaction. Running these models on GPUs ensures fluid conversations without delays.
- Autonomous systems: From self-driving cars to industrial robots, real-time AI inference on GPU cloud infrastructure ensures safety and responsiveness.
- Media and entertainment: Personalized content recommendations and live video analytics also benefit from GPU-accelerated inference.
Each of these examples underscores the importance of combining speed, accuracy, and scalability – qualities that GPU cloud solutions deliver more effectively than CPU-based systems.
Balancing cost and performance
One of the biggest questions organizations face is cost. On the surface, GPU instances may seem more expensive than CPUs. However, performance differences often offset the higher per-hour price. Because GPUs complete inference tasks much faster, the total cost of achieving results can actually be lower.
In addition, cloud computing offers pricing flexibility. Businesses can choose between on-demand resources, reserved instances, or spot pricing models depending on workload predictability. This adaptability allows companies to optimize costs without sacrificing performance.
It is also worth noting that GPUs are particularly efficient for batch inference at scale. When hundreds or thousands of predictions must be processed simultaneously, GPUs deliver both speed and cost savings compared to CPUs.
Overcoming challenges in deployment
Despite the advantages, deploying AI inference on the cloud is not without challenges. Some organizations worry about data privacy and compliance when sensitive data is sent to external servers. Others may face integration issues between cloud infrastructure and existing systems.
These challenges can be addressed through hybrid strategies – running sensitive workloads on-premises while using the GPU cloud for less critical or large-scale inference. Furthermore, many providers now offer compliance-ready environments, making it easier for industries like healthcare or finance to adopt cloud-based AI safely.
Another key consideration is workload management. To truly benefit from GPU inference, organizations must carefully plan how models are deployed, monitored, and scaled. Leveraging managed services or orchestration tools can simplify this process.
The future of real-time AI inference
As AI models become more sophisticated, the demand for faster inference will continue to rise. Edge computing – bringing processing closer to the data source – will play a bigger role, often in combination with the GPU cloud. This hybrid approach ensures that latency-sensitive tasks are handled locally, while large-scale workloads are managed centrally.
Furthermore, advancements in model optimization techniques, such as quantization and pruning, will help reduce computational requirements. This makes inference even more efficient and accessible to a wider range of businesses.
The future clearly points toward an ecosystem where real-time AI inference powered by GPU cloud platforms is the standard, enabling smarter applications across industries.

Key takeaways
Real-time AI inference is transforming how organizations operate, interact with customers, and make decisions. By harnessing the power of GPU inference on the cloud, businesses can achieve the low latency, high scalability, and cost efficiency needed to keep pace with today’s AI-driven world.
As industries continue to adopt and integrate AI into mission-critical systems, GPU cloud infrastructure stands out as the most practical and future-ready solution. For companies looking to unlock the full potential of AI inference, now is the time to embrace the benefits of real-time processing in the cloud.
Frequently Asked Questions About Real-Time AI Inference on GPU Cloud
1. What is AI inference and why is it important?
AI inference is the process of applying a trained model to new data in order to make predictions or decisions. For example, a recommendation engine suggests products, while a computer vision model recognizes objects in images. Inference brings the real-world value of AI, as it is the stage where models operate in live environments.
2. How is real-time inference different from traditional inference?
Real-time inference requires extremely low latency. Results must be delivered within milliseconds, otherwise the effectiveness may drop or risks may arise. This is crucial in use cases such as self-driving cars, fraud detection, or chatbots providing live customer support.
3. Why are GPUs better suited for inference than CPUs?
GPUs excel at parallel processing, allowing them to handle massive amounts of data simultaneously. This enables real-time performance even for complex models. In addition, GPU cloud platforms provide scalable resources, so businesses only pay for what they use while still achieving high efficiency and performance.
4. What are the advantages of using GPU cloud for inference?
GPU cloud eliminates the high costs of maintaining and upgrading on-premise hardware. It offers flexible scaling, simplified deployment with preconfigured environments, and built-in monitoring and optimization tools. This helps organizations balance performance and cost while accelerating time to market.
5. Which industries benefit most from real-time GPU inference?
Several industries gain a strong advantage, including:
- Healthcare – rapid diagnostics from medical imaging.
- Finance – instant fraud detection in transactions.
- Customer service – fast, natural chatbot responses.
- Autonomous systems – safe and responsive self-driving cars or industrial robots.
- Media and entertainment – personalized recommendations and live video analytics.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
