The rise of AI agents and what they demand from cloud infrastructure
October 02, 2025

This article explores how AI agents are reshaping enterprise automation by moving beyond static predictions to autonomous, real-time actions, and explains the cloud infrastructure requirements needed to support their scale, resilience, and complexity.
What you’ll learn:
- Why AI agents matter for industries like finance, healthcare, and operations
- How agents differ from traditional inference with persistence and adaptability
- The compute intensity of agents and the central role of GPUs
- Why elastic scaling, scheduling, and low-latency pipelines are critical
- How reliability and fault tolerance protect continuous workflows
- The integration of AI agents into MLOps practices for deployment and monitoring
- Cost, efficiency, and governance considerations for enterprise adoption
AI adoption is moving beyond static models and into dynamic, autonomous systems. The spotlight is now on AI agents – models that don’t just generate predictions but can reason, take action, and interact with both humans and other systems in real time. From intelligent copilots embedded in software suites to autonomous workflows that handle everything from scheduling to customer support, AI agents are quickly becoming the next wave of enterprise AI.
What makes them transformative is not only their ability to respond but also their capacity to operate independently. Agents can plan multi-step actions, invoke external tools, adapt based on feedback, and integrate with organizational processes. For CTOs and ML teams, this means shifting infrastructure strategies: AI agents don’t just need powerful compute – they demand cloud environments that are flexible, scalable and resilient enough to handle continuous, context-driven workloads.
Why AI agents matter
Unlike traditional inference, which focuses on single outputs from trained models, AI agents are designed for persistence and adaptability. They don’t shut down after producing one answer; they remain active, monitoring inputs, making decisions and chaining tasks together. This makes them particularly valuable in industries where complexity and responsiveness are paramount.
- Customer service: Agents can resolve tickets end to end, escalating only when human judgment is needed.
- Finance: Agents execute trades, analyze risk, and generate compliance reports, often in real time.
- Healthcare: Agents assist doctors by synthesizing patient history, clinical notes and imaging data, and by recommending next steps.
- Operations: Agents coordinate logistics, optimize supply chains, and adjust workflows dynamically.
In every case, the enterprise benefit is efficiency and scalability. But realizing that benefit requires infrastructure that can support constant interaction, multimodal processing and seamless integration with external systems.
Compute intensity of AI agents
AI agents rely on a constellation of capabilities: natural language processing, retrieval from large knowledge bases, planning algorithms and tool invocation. Each step adds to the computational load. Unlike one-off inference queries, agents generate sustained demand for low-latency, high-throughput compute.
GPUs play a central role here. Running multiple models in parallel – for language, vision or even structured data – requires the parallelism that GPUs provide. But even more important is how those GPUs are orchestrated in the cloud. Static allocation leads to waste, while under-provisioning leads to lag or failure. Elastic scaling, GPU scheduling and intelligent load balancing become non-negotiable.
Data pipelines and real-time responsiveness
Agents thrive on context. They pull data from APIs, vector databases, enterprise systems and user interactions. The data pipeline therefore becomes just as critical as the model itself. If the pipeline introduces latency or bottlenecks, the agent’s decision-making falters.
Optimized cloud infrastructure addresses this through high-bandwidth networking, co-location of compute and storage and streamlined preprocessing pipelines. For enterprises, this means designing systems where data flows into GPUs with minimal delay and results flow back out fast enough to support continuous interaction.
Reliability and fault tolerance
Because agents run persistently, downtime is unacceptable. If a customer service agent fails mid-interaction or a financial trading agent drops a task, the business impact is immediate. Infrastructure must therefore prioritize fault tolerance, redundancy and automated recovery.
Enterprise GPU cloud platforms often address this with built-in redundancy across availability zones, proactive monitoring and autoscaling policies that spin up new resources as needed. For CTOs, the key is ensuring that cloud providers can guarantee uptime SLAs and deliver resilience at the infrastructure level, not just the application level.
Integration with MLOps
AI agents don’t exist in a vacuum – they are deployed, monitored and iterated on like any other AI system. This means that MLOps practices remain critical. Continuous integration and delivery pipelines, real-time monitoring and model version control all need to extend to agents.
GPU cloud platforms that integrate seamlessly with MLOps workflows allow teams to update agents rapidly, roll back faulty deployments, and capture telemetry for improvement. For organizations experimenting with multiple agents across business units, this kind of operational maturity prevents fragmentation and chaos.
Cost and efficiency considerations
Running agents can be expensive. Persistent workloads consume compute continuously, and without optimization, costs can spiral. Enterprises need cloud platforms that support granular billing, spot instance utilization and efficient GPU sharing.
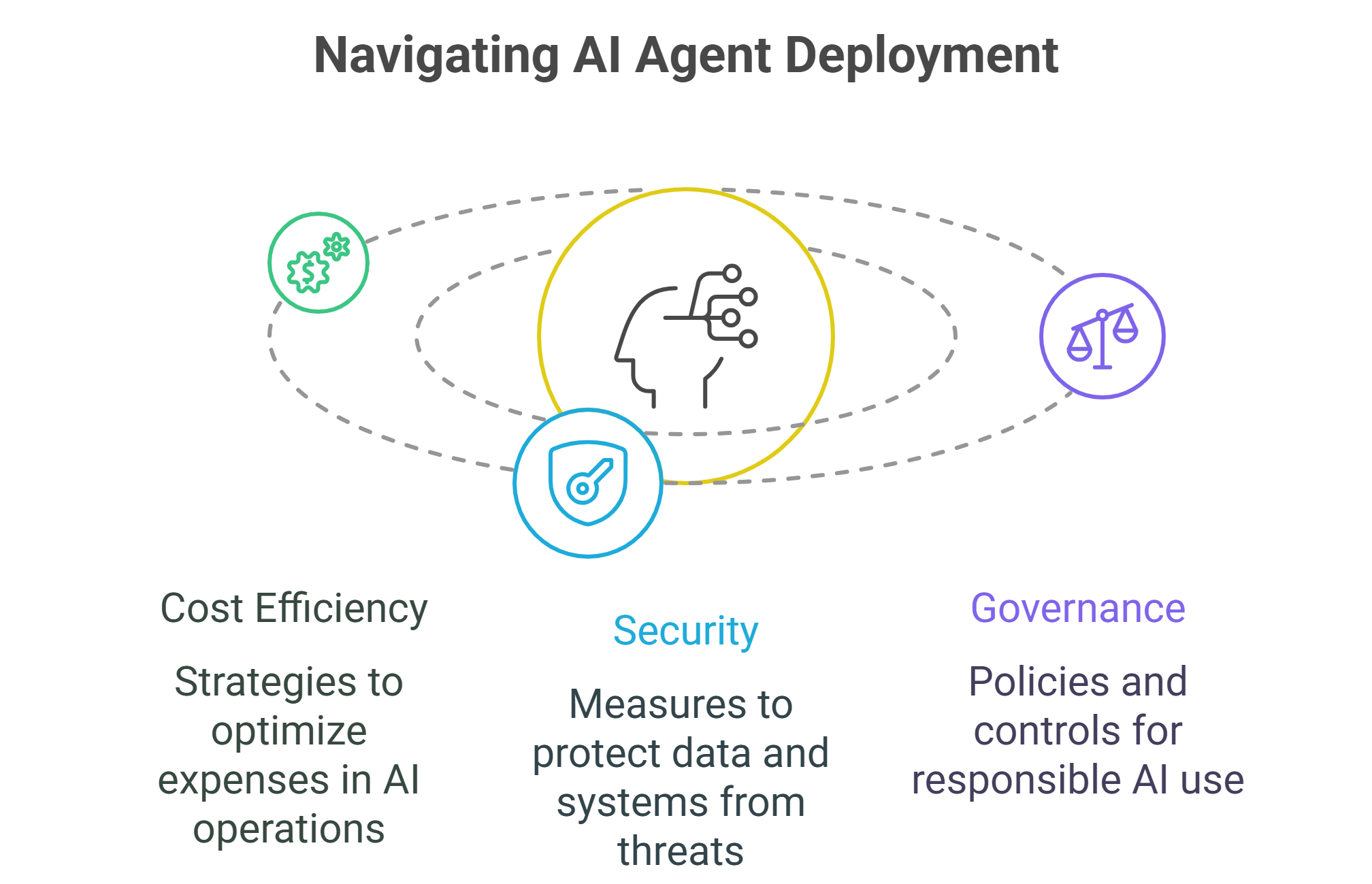
One strategy is hybrid deployment: using high-performance GPUs for real-time agent responses and CPUs for background or lower-priority tasks. Another is workload-aware scheduling, which ensures that compute resources match demand without over-provisioning. By aligning infrastructure cost models with the nature of agent workloads, enterprises can make persistent AI economically viable.
Security and governance
AI agents introduce unique risks. Because they act autonomously and often interact with external systems, they must be carefully governed. Security concerns range from data leakage to unauthorized tool use. Compliance issues, especially in regulated industries, add another layer of complexity.
Cloud platforms can support governance by offering role-based access controls, encrypted data flows and audit logs of agent actions. Enterprises should also establish clear policies for what agents can and cannot do, combining infrastructure-level safeguards with organizational oversight.
The competitive landscape
Major hyperscalers are embedding agent capabilities into their ecosystems, while startups are racing to deliver lightweight, specialized alternatives. Enterprises evaluating platforms must consider whether they need broad integration with existing cloud services or specialized environments optimized for inference and agent deployment.
GMI Cloud positions itself in the latter category, focusing on inference-optimized infrastructure that minimizes latency and maximizes flexibility. By offering GPU scheduling, elastic scaling and streamlined APIs, platforms like GMI Cloud enable enterprises to deploy AI agents without being locked into monolithic ecosystems.
To sum up
AI agents represent the next step in enterprise automation. They’re not just passive responders – they’re active participants in workflows, capable of chaining tasks, adapting in real time and integrating seamlessly across systems. But to deliver on this promise, they require infrastructure that matches their intensity: GPU-powered, cloud-native, elastic and secure.
For CTOs and ML teams, the challenge is less about proving AI’s potential and more about operationalizing it. Those who align their infrastructure with the unique demands of AI agents will not only accelerate adoption but also define the benchmarks for reliability, efficiency and user experience in the agent-driven era.
Frequently Asked Questions About AI Agents and Their Cloud Infrastructure Needs
1. What makes an AI agent different from a traditional model?
Traditional inference returns a single answer and stops. AI agents are persistent and adaptive: they plan multi-step actions, call external tools, integrate with organizational systems, and keep working based on feedback. That’s why they’re valuable in customer service, finance, healthcare, and operations—and why they need cloud environments that handle continuous, context-driven workloads.
2. Why do AI agents demand GPU-powered, elastic infrastructure?
Agents generate sustained low-latency, high-throughput compute across multiple capabilities (language, vision, structured data, planning, retrieval, tool use). GPUs provide the parallelism to run these pieces in parallel, but orchestration is crucial: without elastic scaling, GPU scheduling, and intelligent load balancing, static allocation wastes resources while under-provisioning creates lag or failures.
3. What data-pipeline capabilities are essential for real-time agents?
Agents thrive on context pulled from APIs, vector databases, enterprise systems, and user interactions. To keep decisions responsive, pipelines need high-bandwidth networking, co-location of compute and storage, and streamlined preprocessing so data reaches GPUs with minimal delay—and results flow back quickly enough for continuous interaction.
4. How do we ensure reliability, fault tolerance, and governance for persistent agents?
Downtime mid-interaction is unacceptable. Enterprise GPU clouds address this with redundancy across availability zones, proactive monitoring, and autoscaling that replaces unhealthy resources automatically—backed by uptime SLAs. Because agents act autonomously, you also need role-based access controls, encrypted data flows, and audit logs of agent actions, plus clear internal policies for what agents may do.
5. How do MLOps practices extend to AI agents?
Agents still need full-lifecycle ops: CI/CD for rapid updates, real-time monitoring, and model version control. Aligning agents with existing MLOps lets teams roll out improvements, roll back faulty deployments, and use telemetry for iteration—avoiding fragmentation when multiple agents run across business units.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
