When milliseconds matter: GPU cloud for trading, healthcare and robotics
GMI Cloud powers real-time AI for industries where milliseconds matter—from trading and healthcare to robotics. With GPU-optimized infrastructure, intelligent scheduling, and edge integration, it enables ultra-low latency, scalability, and reliability for mission-critical applications.
October 20, 2025

This article explores how GPU cloud infrastructure powers real-time AI in industries where every millisecond counts—such as trading, healthcare, and robotics. It highlights how GMI Cloud’s GPU-optimized clusters, intelligent scheduling, and edge integration deliver ultra-low latency, scalability, and reliability for mission-critical applications.
What you’ll learn:
• Why latency is the ultimate differentiator in real-time AI systems
• How GPU acceleration enables sub-millisecond inference for trading, healthcare, and robotics
• The role of edge proximity and high-bandwidth networking in achieving low latency
• How autoscaling and orchestration maintain performance under fluctuating demand
• Ways to balance cost and scalability through hybrid GPU models
• How intelligent scheduling improves utilization and resource efficiency
• Why GMI Cloud’s Cluster Engine is designed for mission-critical, latency-sensitive AI workloads
In many industries, performance isn’t measured in minutes or seconds – it’s measured in milliseconds. A trade executed a few milliseconds faster can mean the difference between profit and loss. A medical AI model that processes images instantly can accelerate critical diagnoses. A robot that reacts in real time can avoid collisions and adapt dynamically to its environment. These use cases are powered by a combination of advanced algorithms and high-performance infrastructure – and increasingly, GPU cloud is the engine that makes it all work.
While compute power has always been essential for AI, latency has emerged as the real competitive differentiator. For enterprises in domains where every millisecond matters, cloud infrastructure must deliver more than just raw performance. It needs to be optimized for low-latency inference, scalable enough to handle demand spikes, and flexible enough to support rapid iteration cycles without compromising reliability.
The latency imperative
Latency is the time between when a system receives a request and when it produces a response. In AI applications, low latency is critical for maintaining performance, accuracy and user experience. Even a small increase in response time can lead to cascading effects: slower decision-making, degraded service quality or missed opportunities.
GPU acceleration plays a key role here because of its ability to process large volumes of data in parallel. By reducing inference time from hundreds of milliseconds to just a few, GPUs unlock real-time AI capabilities that would be impractical or impossible on CPU-based infrastructure. But GPUs alone aren’t enough – the surrounding cloud infrastructure must minimize network overhead, scale intelligently, and keep workloads as close to the edge as possible.
Trading: every millisecond counts
In financial trading, speed is strategy. High-frequency trading platforms, algorithmic trading desks and risk management systems rely on real-time insights to act ahead of the competition. A single delay in executing an order can mean missed opportunities or unfavorable prices.
GPU cloud infrastructure enables ultra-low-latency inference for models that power trade execution, risk scoring and predictive analytics. By co-locating compute resources close to major exchanges and optimizing data transfer, firms can minimize round-trip time. In practice, this means inference can occur in microseconds rather than milliseconds, giving trading strategies a critical edge.
Another key advantage of GPU cloud is elasticity. Market activity isn’t constant – it spikes around major economic announcements, geopolitical events or even sudden market swings. Instead of overprovisioning on-premises hardware, firms can scale up GPU capacity dynamically to match demand, then scale back down during quieter periods. This agility makes high-performance infrastructure financially sustainable.
Healthcare: precision depends on speed
In healthcare, latency isn’t just a performance metric – it can be a matter of patient outcomes. AI is increasingly used to support clinical workflows: radiology imaging analysis, pathology classification, predictive patient monitoring and more. These tasks often require processing massive volumes of data in near real time.
For example, medical imaging AI models must analyze scans quickly so that radiologists can make fast, informed decisions. Similarly, predictive monitoring systems for critical care depend on analyzing streams of sensor data to detect deterioration before it becomes critical. GPU cloud platforms enable these workloads to run at scale while keeping response times low, ensuring clinicians receive actionable insights at the moment they matter most.
Security and compliance are also essential. GPU cloud platforms that serve the healthcare sector must meet stringent regulatory requirements, from HIPAA compliance to robust access control. Built-in security features and compliance certifications help healthcare organizations deploy low-latency AI without compromising patient data protection.
Robotics: real-time autonomy
Autonomous systems – from industrial robots to drones and autonomous vehicles – rely on low-latency AI to function safely and efficiently. These systems continuously process streams of sensor data, make split-second decisions, and execute actions in the physical world.
The closer these decisions get to real time, the more effectively the systems can operate. GPU cloud infrastructure makes it possible to run computationally intensive models such as perception, path planning and control without exceeding tight latency budgets. In scenarios where local compute isn’t enough or isn’t feasible, edge-integrated GPU cloud deployments bring inference closer to where data is generated, minimizing delays.
A major advantage in robotics is scalability across fleets. Whether coordinating autonomous delivery vehicles in a city or managing robotic arms on a production line, cloud-based orchestration allows centralized control and distributed decision-making to coexist seamlessly.
Building for low latency
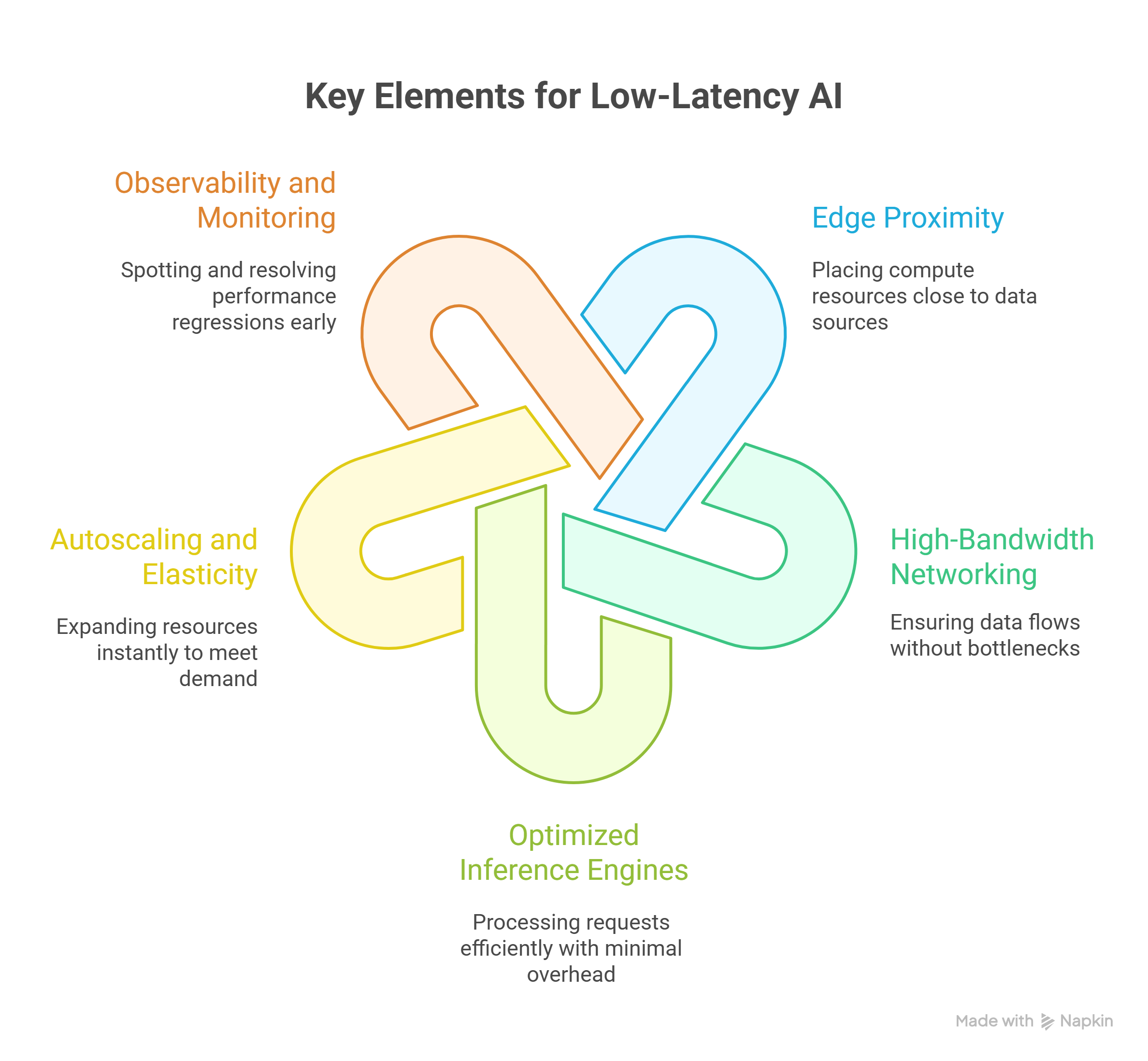
Low-latency AI isn’t just about compute speed – it’s about the entire pipeline. Several key architectural elements determine whether a GPU cloud deployment can meet sub-100 millisecond targets:
- Edge proximity: Placing compute resources close to where data is generated minimizes round-trip delays. For trading, this might mean data centers near major exchanges; for robotics, local edge nodes.
- High-bandwidth networking: Even the fastest GPU can’t compensate for network congestion. High-throughput, low-latency networking fabrics keep data flowing without introducing bottlenecks.
- Optimized inference engines: Leveraging optimized serving frameworks and container orchestration ensures requests are processed efficiently without unnecessary overhead.
- Autoscaling and elasticity: Latency targets can break under unexpected load if infrastructure can’t scale fast. Elastic GPU resources allow systems to expand instantly to meet demand.
- Observability and monitoring: Fine-grained metrics on latency, utilization and throughput allow teams to spot and resolve performance regressions early.
By addressing these factors holistically, enterprises can unlock the full value of GPU acceleration in latency-sensitive domains.
Cost and scalability considerations
Ultra-low-latency performance often comes with higher infrastructure costs – but smart architecture choices can make it sustainable. Reserved GPU instances offer predictable pricing for consistent workloads, while on-demand capacity provides flexibility during peak demand. This hybrid approach ensures enterprises only pay for what they need, when they need it, without sacrificing speed.
Edge deployments can also reduce bandwidth costs by processing data closer to the source, avoiding expensive round trips to centralized data centers. Combining cloud elasticity with targeted edge compute creates an optimal balance between performance, cost and scalability.
The role of GPU scheduling and orchestration
One of the hidden levers of low-latency performance is GPU scheduling. Intelligent schedulers ensure high-priority workloads always get the resources they need, while background tasks are deferred or allocated to lower-cost infrastructure. Kubernetes and other orchestration frameworks make this possible at scale, but tuning these systems for latency-sensitive applications requires specialized expertise and infrastructure support.
Rethinking what’s possible in milliseconds
When milliseconds define outcomes, infrastructure becomes a strategic asset. GMI Cloud delivers GPU-optimized clusters with high-bandwidth networking, intelligent scheduling and edge integrations to keep latency ultra-low.
Powered by the Cluster Engine, GMI Cloud enables precise resource allocation, automated workload bin packing and real-time utilization insights – ensuring GPUs are always matched to the right tasks without wasted capacity. This intelligent resource management is what allows real-time workloads to run smoothly even at scale.
With both reserved and on-demand models, enterprises balance cost and performance while scaling instantly to match demand. Built-in observability, security and orchestration support streamline operations, letting teams focus on innovation – not infrastructure.
Whether it’s trading, healthcare, or robotics, GMI Cloud provides the foundation for real-time AI at enterprise scale.
FAQs: GPU Cloud for Ultra-Low-Latency AI in Trading, Healthcare, and Robotics
1. How does GPU cloud reduce latency for real-time AI in trading, healthcare, and robotics?
GPU cloud pairs parallel GPU compute with low-latency networking, intelligent scheduling, and edge integration. This setup cuts inference time and minimizes round-trip delays, so models respond within tight millisecond budgets for order execution, clinical workflows, and autonomous control.
2. Why do milliseconds matter so much in these industries?
Small delays cascade: a slower trade can miss price windows, a delayed image analysis can slow diagnoses, and a robot that reacts late can’t safely adapt. Low latency preserves performance, accuracy, and user experience in mission-critical settings.
3. What architectural choices enable sub-100-millisecond inference on GPU cloud?
Placing compute near data sources (edge proximity), using high-bandwidth, low-latency networking, running optimized inference engines in containers, and autoscaling under load—all monitored with fine-grained observability—keep end-to-end latency consistently low.
4. How does GPU cloud handle unpredictable spikes without overprovisioning?
With elasticity. Teams reserve baseline capacity for steady demand and burst on-demand during market events, clinical peaks, or fleet surges. Autoscaling and intelligent GPU scheduling keep performance stable while avoiding idle hardware.
5. What makes GPU cloud suitable for regulated or safety-critical use cases?
Built-in security, governance, and compliance features (such as role-based access control, encryption, and support for frameworks like HIPAA in healthcare) are integrated into the platform. That lets organizations deploy low-latency AI without bolting on separate controls.
6. How does GMI Cloud specifically support real-time workloads at scale?
GMI Cloud provides GPU-optimized clusters, high-bandwidth networking, and edge integrations, all coordinated by a Cluster Engine for precise resource allocation, automated bin-packing, and real-time utilization insights—plus hybrid reserved/on-demand models and integrated observability, security, and orchestration to keep latency ultra-low while scaling.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
