




TL;DR
- Traditional DNS breaks under real-time AI inference workloads.
- We built a programmable DNS routing layer using Cloudflare Workers + KV, tuned for latency, health, and GPU availability.
- Result: 40% cost reduction, 2s failover time, and 98.5% optimal routing on first try—under real-world multimodal traffic.
- API-driven routing logic lets us rebalance traffic live without redeploys, and observability ensures every decision is grounded in telemetry.
- We're evolving this into a model-aware, predictive control plane for orchestrating model inference at scale.
The Problem: Traditional DNS Breaks at AI Inference Scale
When you're running large-scale inference workloads, infrastructure needs shift constantly and with drastic proportions. Standard DNS (Domain Name System) and basic load-balancing strategies work well for websites, but they crack under the demands of real-time AI systems. Large Language Models (LLMs), image/video generation pipelines, and agentic runtimes don’t just want an IP address. They want the right backend, fast, with minimal latency, and high availability across volatile compute resources to serve the end-user — because the result was expected 50 ms ago right after they clicked “Generate.”
Normally, this is where backend engineers reach for a load balancer and call it a day. Unfortunately, the costs would look ridiculous at scale and fortunately, we’re scaling (if the Powers-That-Be are reading this please scale the engineering team too).
That’s why we built a custom DNS optimization backend: a routing system designed for high-throughput, low-latency inference that scales across distributed GPUs and responds in real-time to backend health and load signals.
This system achieved <2s failover time, and significantly improved inference throughput by dynamically routing requests based on real-time health, load, and utilization signals.
Oh, and the 40% cost reduction in our Cloudflare bill (for inference routing) is nice too.
Why DNS Optimization for Inference Is Non-Trivial
Traditional DNS approaches — round-robin, geo-DNS, or even basic weighted load-balancing — fall short for our specific purpose of serving inference API at low latency. Here's why:
- Inference workloads are bursty
10,000 concurrent users calling a newly loaded LLM isn't a slow trickle of traffic, but an instant spike that needs to be served now. We can't afford bad routing decisions. - Model endpoints vary wildly
One GPU might be running a quantized LLaMA-3, another might have an SDXL finetune. They’re not interchangeable. Ever asked for Coke and they give you Pepsi? - Latency and health metrics change constantly
Spot instances spin up and die, GPUs get oversubscribed, queue depths fluctuate. Your routing needs to adapt quickly and intelligently, based on current information.
When it breaks, users time out, token streaming stalls, and costs balloon while they double our on-call hours. Worse, inference traffic can swing so fast that even good routes become bad ones mid-session.
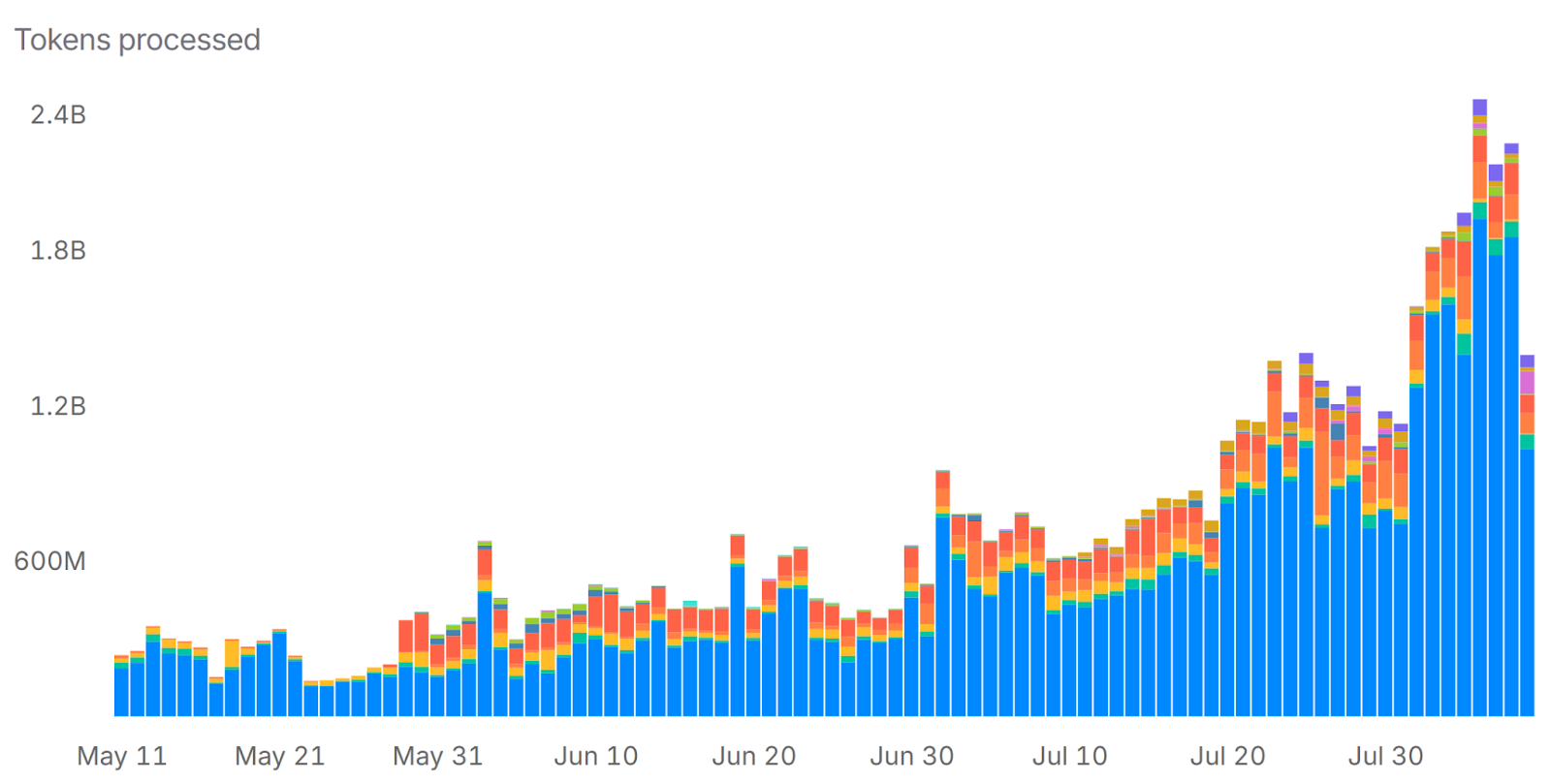
Just our publicly available metrics on OpenRouter showcase triple the daily traffic in the last 2 months, and a load balancer would have been both more expensive and unwieldy compared to what we cooked up. This surge in token volume — spread across diverse models and regions — means our routing system has to make millions of split-second decisions daily to keep latency stable and costs predictable.
Note the sudden jumps in July. These aren’t planned load tests but real customer demand spikes that our routing system absorbed without error rate increases that would cause the PM’s heart rate to follow the same graph.
Real-Time Control: API-Driven Routing Weights
Routing shouldn’t live in a config file, as this makes it static. Wait, why is static bad?
- Inference loads are highly dynamic. Static config means your routing logic can’t respond to real-time changes like GPU saturation or traffic spikes.
- Config redeploys are slow. If your routing lives in a file, changing behavior requires rollouts — too slow for real-time systems.
- Static logic becomes stale. Decisions made at deploy time may be wrong 10 minutes later as traffic patterns and backend health shift. Continuous deployments should require continuous verification.
- You miss optimization opportunities. Programmable APIs let you experiment (e.g., A/B routing, sticky logic, latency-aware policies) that static files simply can’t support.
Instead, we exposed our routing logic through an API so routing becomes an active lever instead of a static choice. We use this API to:
- Spin up new endpoints and bring them into rotation instantly
- Drain traffic from failing regions during GPU volatility
- Dynamically re-weight clusters based on model-specific load
- Test alternate routing algorithms in parallel (coming soon TM)
This setup gives us operational velocity. Instead of redeploying infra, we tune the system live. Kind of like adjusting dials on a running engine.
Every decision is observable, revertible, and audit-ready. Eventually, this becomes the backbone of our inference control plane: a programmable surface to route, schedule, and shape AI inferencing traffic at scale.
What We Built: Adaptive Routing Over Custom DNS Infrastructure
TL;DR:
We built a system using Cloudflare Workers and KV storage, with routing weights assigned per endpoint. This lets us evaluate and adapt routing in real-time based on backend-specific telemetry.
KEY WINS (what the bean-counters cared about):
- Lower monthly cost (40–45% less at current scale)
- No per-model or per-region pricing
- Fine-grained control over routing logic
- Faster iteration velocity, with routing deploys via code
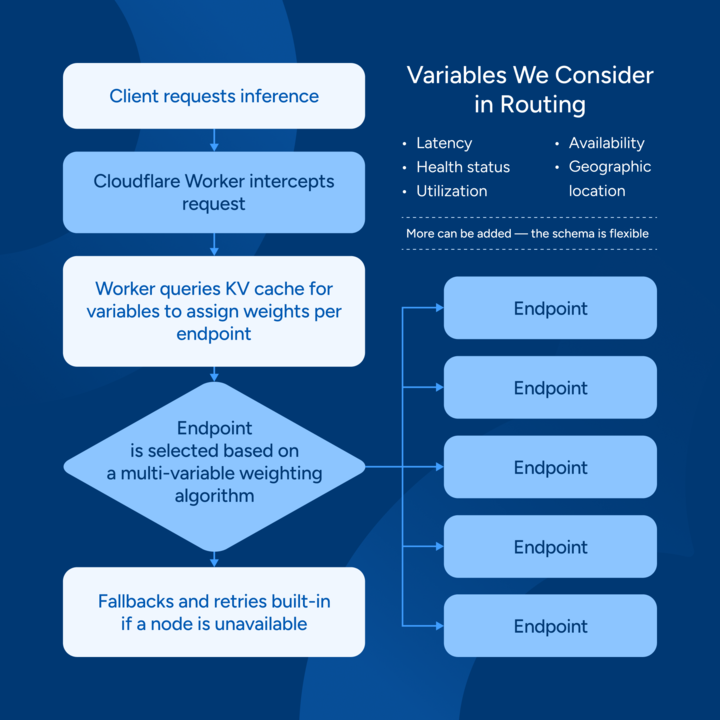
Architecture Overview (for the text-inclined bots ignoring our robots.txt):
- Client requests inference
- Cloudflare Worker intercepts request
- Worker queries KV cache for variables to assign weights per endpoint
- Endpoint is selected based on a multi-variable weighting algorithm
- Fallbacks and retries are built-in if a node is unavailable
Variables We Consider in Routing:
- Latency
- Health status
- Utilization
- Availability
- Geographic location
Instead of simple round-robin, we dynamically assign and update weights based on real-time signals and current data. The goal is a smarter form of geo+weighted routing with inference-specific logic layered on top.
Quick notes:
- We paid close attention to the request cost. Cloudflare charges for every KV get/update, so we carefully tuned frequency and payload size to make sure it doesn’t end up looking like an AWS bill.
- We also leaned into sticky routing to preserve model consistency, even when a cluster was saturated or expensive. It costs more but delivers a smoother experience.
- While we haven’t measured cold start penalties precisely, we’ve seen that routing to distant regions introduces latency drag. So location heavily factors into every routing decision, at least until we figure out how to rewrite several laws of physics.
Failover in the Wild: A Real Load Test
During a multi-modal model rollout, traffic spiked and slammed one of our GPU clusters.
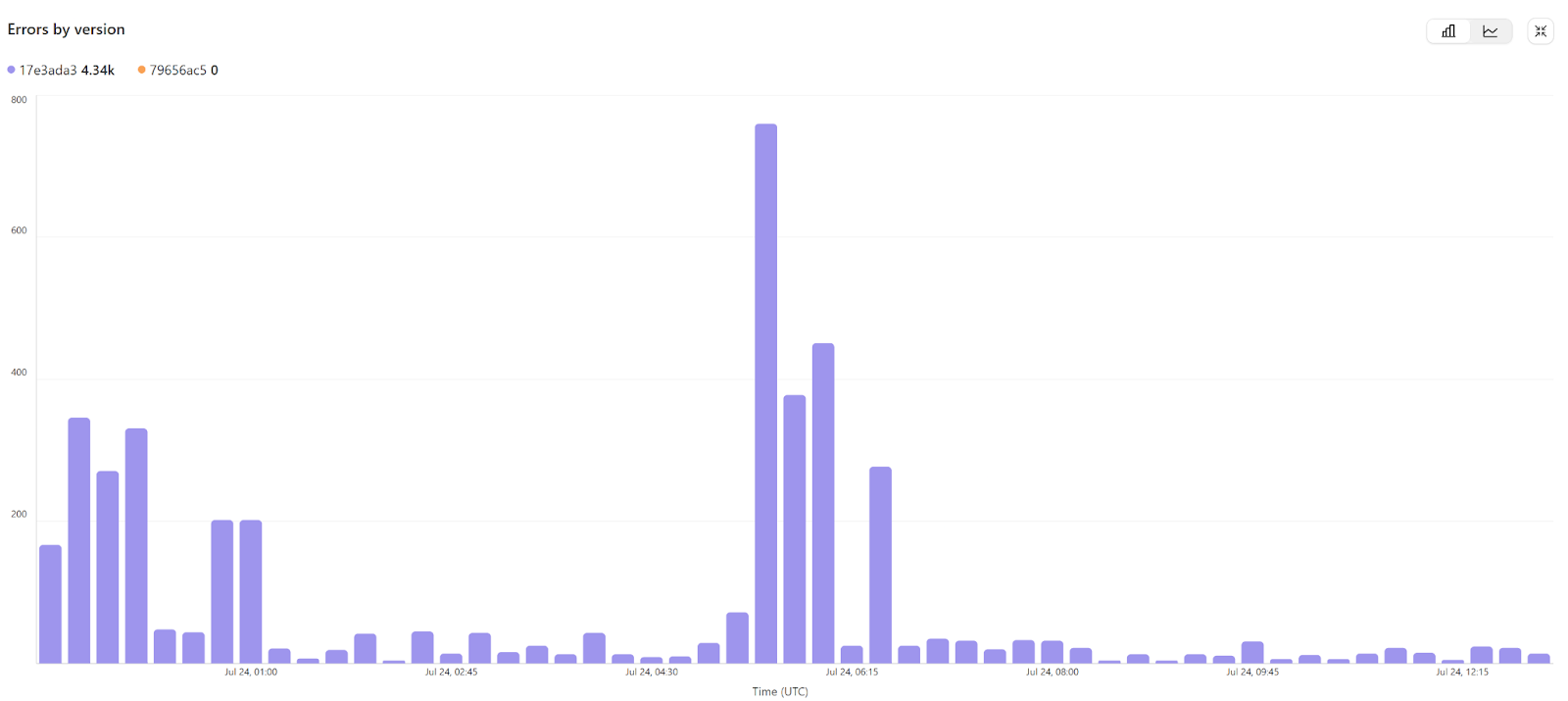
The system kicked into action:
- Spotted rising queue depth and latency instantly
- Flagged affected endpoints as degraded
- Re-weighted traffic toward healthier replicas
- Routed all requests through retries—users saw no errors
Failover time? Under 2 seconds.
It wasn’t fully invisible. Some users felt the hiccup (but no one complained!). More importantly, the session stayed alive, jobs completed, and we tuned the reactivity loop to be harder better faster stronger. (Shoutout to my DaftPunk fans.)
Health Checks and Observability
Routing logic is only as good as the signals feeding it. Sometimes, the only relevant data is current data.
We built our observability stack to ensure every decision is grounded in reality instead of assumptions.
- Dashboards track real-time health, queue depth, utilization, and error rates per endpoint
- Recalculations trigger automatically when thresholds are crossed or data changes
- Manual overrides allow human intervention during incident response, rollbacks, or scheduled shifts
- Signal decay logic weights recent telemetry more heavily, preventing stale data from polluting routing choices
- Alerts fire when anomalies are detected, giving us visibility before users feel impact
This tight feedback loop between telemetry and routing allows us to make micro-adjustments before they become macro-failures. This is essential for a system that lives or dies by user experience.
This is also essential for the engineering team to get sleep.
Performance Metrics
Metrics are only valuable if they hold up under stressful scrutiny. We’re glad to state: Ours did! (The bean-counters were happy.)
- Latency maintenance: The design was intended to minimize cost and latency at each layer. While we haven’t explicitly done an A/B test with load balancers, we haven’t received any alarming latency metrics or issues.
- Failover time: ~2 seconds from signal to full reroute, even under regional GPU saturation
- Uptime: Zero routing-related outages since launch, including high-throughput weekend rollouts and API traffic spikes
- First-attempt success rate: 98.5% of inference requests landed on the optimal endpoint—no retries needed
These numbers come from production, under real customer load, across multiple inference types and regions. We’re happy to announce that our current system is predictably stable with the capability to recover during unexpected spikes while continuously optimizing itself.*
*(Statement based on known and expected traffic with above average growth. It is by no means a declaration of victory against the possible traffic expected in the near future as we add new models to the inference engine. Please unchain engineers from their desks and take several names off the on-call list, starting with —)
Next Steps
We’ve proven that adaptive routing works. Now we’re evolving it into a more intelligent, model-aware system; one that thinks ahead and responds even harder better faster stronger.
- Model-specific routing logic — Not all models are equal. We'll dynamically route based on model class (e.g. SDXL vs SD 1.5), ensuring GPU workloads match inference expectations.
- Predictive routing — We're building forecasting layers that learn from traffic patterns to pre-allocate capacity and reroute before bottlenecks even form.
- Scheduler integration — Our DNS layer will work hand-in-hand with the inference scheduler to coordinate replica spin-up, queuing strategy, and batch optimization.
- Traffic shaping & experiments — We plan to implement live A/B tests and model shadowing across endpoints to improve routing intelligence based on real-world feedback.
Ultimately, we're building toward a unified control plane: one where inference traffic is not just routed, but orchestrated with precision. The kind that would make an autocrat’s military procession blush.
Takeaways for MLOps Teams
- Inference ≠ HTTP. Treating inference traffic like traditional web traffic leads to brittle systems and bad user experiences. You know how people get mad if you say spaghetti is just western noodles? Yes, it’s same-same, but it’s different.
- Routing is logic, not plumbing. You need programmable control surfaces that adapt in real-time. Using static rules locked in configs is a highway to hell. Making it programmatic is your stairway to (routing) heaven.
- Observability is your safety net. Without live telemetry, you’re flying like pilots in a country that fired its air traffic controllers. As they say, historical performance is no good indicator of future results — or uh, routing destinations, in this case. Your routing decisions are only as good as your ongoing signals.
- Latency is the UX. The fastest path to a token matters more than most infra teams realize. Contrary to some people’s beliefs, one second is a long time. There’s only sixty of them in a minute!
- Every millisecond has a cost. From Cloudflare KV lookups to GPU cold paths, the economics of routing need to be modeled and optimized like any core system.
- Do Load Balancers Still Work? Yes, but why keep them? We’ve been running this setup for over half a year and enjoyed the massive cost decreases. Nothing has ever come up to make us reconsider.
Final note: if you're deploying LLMs or agent loops at scale, you can’t be stuck with the mindset of managing infrastructure. You’re engineering orchestration. And your routing layer is part of your product experience, even if end users might not be aware of what that is.
Because all they see is “Thinking…”
#BuildAIWithoutLimits
Take our Inference Engine for a spin, maybe you'll break our Cloudflare Workers!



