
H100
Hopper · 基準款
- 記憶體
- 80 GB HBM3
- 推理效能
- 1.0×(基準)
主力款 GPU,適合一般 LLM 與多模態推理,是大多數正式環境工作負載的起點。
Prime Inference 提供針對每個模型最佳化的預留 GPU 容量,並搭配工程協作支援,讓你能順利從可運作的原型推進到正式環境系統。
H100 · H200 · Blackwell
NVIDIA 認證硬體
99.9% 可用性
正式環境 SLA

效能、覆蓋範圍與彈性 — 為真實的正式環境流量而設計,可因應任何規模。
2 倍吞吐量
頂尖效能
針對每個模型的執行階段最佳化 — 涵蓋核心、排程與路由 — 在主流開源模型上可提供相較於通用堆疊最高 2 倍的持續吞吐量。
為參考性質的基準測試,實際效能會因模型與工作負載而異。
3 大全球區域
低延遲
在 APAC、北美與歐洲提供單一租戶容量。可依需求進行區域釘選以降低 TTFT,或進行區域鎖定以符合資料駐留要求 — 配合你的市場量身打造部署方式。
業界領先
從設計上就具備彈性
突發容量會自動吸收尖峰流量,離峰時段則自動收縮以節省成本。我們已經克服多數平台難以解決的差距,並持續加快佈建速度。
預留容量能直接呼應實際的正式環境流量,而針對每個模型的執行階段最佳化更會隨著時間持續累積優勢。
不是通用堆疊,而是針對每個模型最佳化的核心、排程與路由。你只需選擇模型,引擎部分交給我們處理。
預留 GPU 會預先載入權重並維持暖機狀態,每一次呼叫都能立即執行 — 沒有冷啟動延遲,也沒有首個 token 的抖動。
GPU 完全保留給你的工作負載。沒有吵雜的鄰居、沒有負載下的競用,也不會有共用方案常見的意外狀況。
支援任何開源、微調或自有權重。可從 Hugging Face、S3 或自己的儲存空間載入,並執行於專為服務該模型而打造的執行階段上。
我們的推理工程師會持續調校最常被部署的開源模型背後的執行階段 — 當你選好模型時,核心層的最佳化工作其實已經完成。
vLLM、TensorRT-LLM 與 SGLang 已依不同 GPU 等級預先調校。量化可彈性設定,多 GPU 編排也由我們處理。
可將端點釘選在指定區域以降低首個 token 延遲,或鎖定區域以符合資料駐留要求。
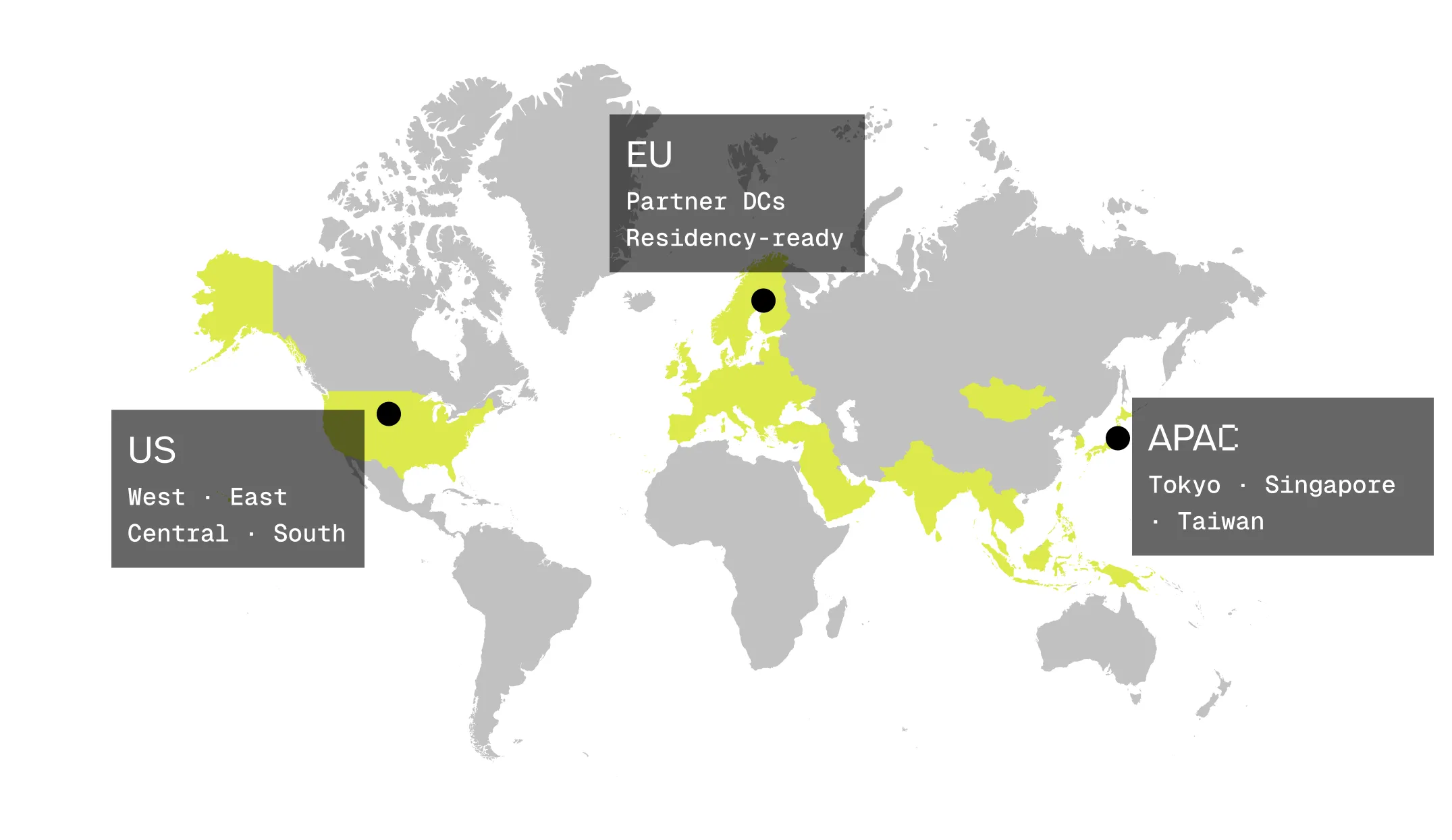
東京 · 新加坡 · 台灣 — 服務成長最快速的 AI 市場。
美國西部、東部、中部與南部 — 適合高吞吐量的正式環境流量。
歐盟合作夥伴資料中心 — 服務具備資料駐留與法遵需求的工作負載。
在你需要穩定效能時提供預留容量;需求突增時提供突發容量;流量下降時自動收縮。你只需為實際使用的部分付費。
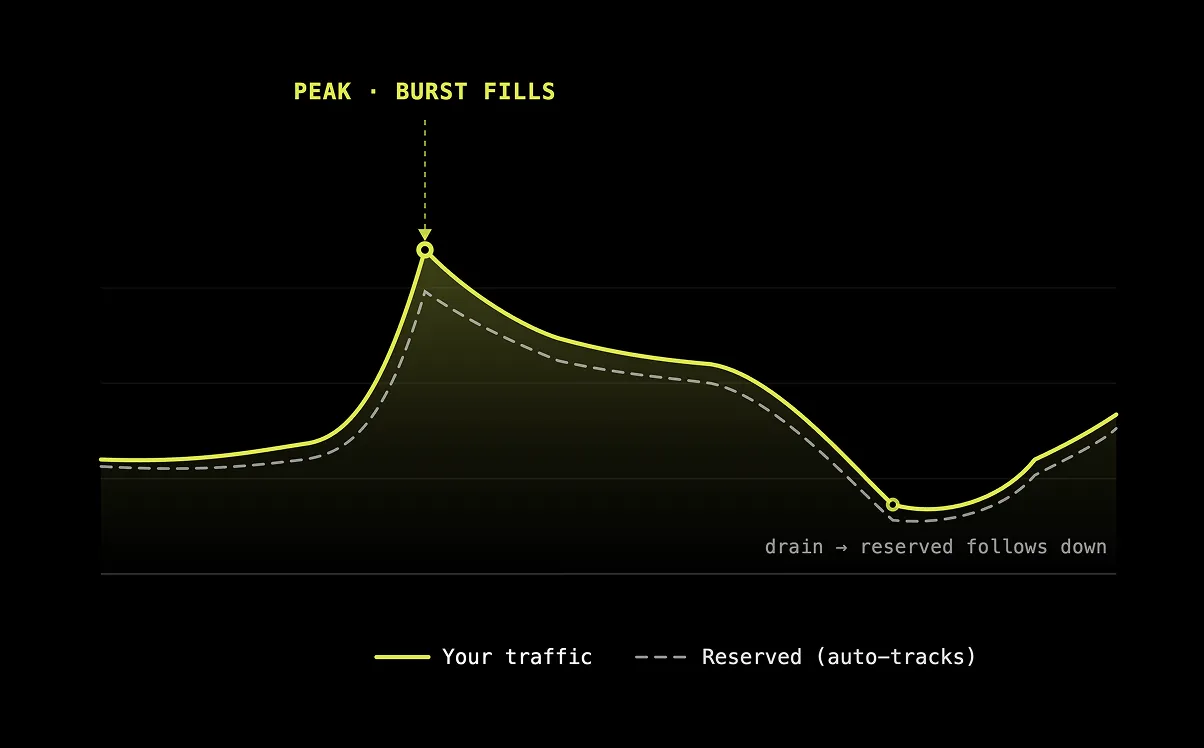
尖峰流量會自動被吸收,不會有排隊、不需要手動擴展,也不會在展示或產品上線時失敗。
離峰時段成本更低。容量會在不中斷進行中的請求的情況下平順縮減。
當主要區域容量達到上限時,流量可從最近的鄰近區域借用容量,維持低延遲與服務不中斷。
選好模型、選好硬體,然後部署。平台會處理模型載入、資源編排與路由 — 從選擇到實際可用的 API,整個過程只要幾分鐘。
任何開源模型、Hugging Face 上的模型,或上傳你自己的權重皆可。
選擇 GPU 類型、每個複本的 GPU 數量、複本數量與目標區域。
可從控制台、CLI 或 API 啟動。端點在幾分鐘內就會上線,不必等好幾天。
監控延遲與吞吐量。流量增加時自動突發、減少時自動收縮。
一鍵部署主流開源模型 — DeepSeek、Kimi、GLM、Llama、NVIDIA 等等。從尖端 LLM 到視覺、語音與多模態 — 選好模型,就能取得正式環境端點。
deepseek-ai
moonshot-ai
zhipu-ai
meta-llama
nvidia
在這些正式環境流量場景中,可預期性、吞吐量與工程協作能將可運作的原型轉變為穩定可靠的產品。
每個任務都會有許多短請求,使用者體驗主要取決於第一次呼叫的延遲。工具呼叫必須穩定,而不只是要求快。
每個代理叢集都有穩定端點 · 暖機容量 · 展示或產品上線時也不會冷啟動。
語音場景無法容忍效能波動。需要持續性的 WebSocket 連線搭配暖機容量,並透過區域釘選縮短往返時間。
首位元組 TTS 低於一秒 · 串流端點 · 不會出現共用方案常見的抖動。
以硬體可承受的吞吐量支撐每日數百萬次查詢,並在長上下文工作負載中維持一致的尾端延遲。
KV-cache 已最佳化 · P95/P99 可控 · 沒有共用資源池的競用。
提供隔離的執行階段、稽核日誌與不留存的服務模式。可區域鎖定,適用於金融、醫療與公部門。
支援歐盟資料駐留 · 單一租戶隔離 · 企業級 SLA。
Hopper、Hopper-refresh 與 Blackwell — 可依記憶體需求、上下文長度或前沿效能需求做選擇。
Hopper · 基準款
主力款 GPU,適合一般 LLM 與多模態推理,是大多數正式環境工作負載的起點。

Hopper 改版
適合記憶體密集型工作負載 — 長上下文、大型 KV-cache、大批次處理。

Blackwell · 前沿款
適合前沿模型、FP4 推理與最高吞吐量需求,是對效能要求極高工作負載的首選。
常見問題

從控制台啟動 Prime Inference 端點 — 或聯絡銷售團隊,瞭解預留容量、客製化調校與試用額度。