
This article examines when renting GPUs delivers better return on investment than buying them outright, breaking down how utilization, workload type and scaling needs shape the real economics of GPU infrastructure.
From this article, you’ll learn:
- the true, often hidden costs of owning on-prem GPU infrastructure
- how usage-based cloud economics change ROI calculations
- why GPU utilization is the single most important ROI driver
- how training and inference workloads differ financially
- when fluctuating inference demand favors cloud GPUs
- which hidden operational and opportunity costs often tilt ROI toward the cloud
- how reserved and on-demand cloud models can be combined effectively
- when buying GPUs still makes economic sense
For AI teams building production systems, GPUs are more than an experimental expense – they are a core input cost that directly affects model performance, iteration speed and business outcomes. As demand for compute grows, organizations inevitably face the same question: does it make more financial sense to buy GPUs outright, or to rent them through a GPU cloud platform?
The answer is rarely obvious. While on-premise GPUs offer a sense of ownership and predictability, cloud GPUs introduce flexibility, speed and access to architectures that may be impractical to maintain in-house. Understanding return on investment requires looking beyond sticker price and examining how GPUs are actually used over time.
The true cost of owning GPUs
The upfront cost of purchasing GPUs is only the most visible part of ownership. Enterprise-grade GPUs require supporting infrastructure: power, cooling, networking, storage and physical space. These costs scale quickly, especially as models grow larger and training and inference workloads become more demanding.
Operational expenses further complicate the picture. Maintaining GPU clusters requires skilled personnel to manage drivers, firmware, scheduling, monitoring and security. Downtime, hardware failures and underutilization all reduce effective ROI. Even well-run on-prem clusters often operate below peak utilization for long periods, silently eroding value.
Ownership also locks teams into specific hardware generations. As new GPU architectures appear, older hardware depreciates rapidly, but replacing it requires another significant capital investment.
Cloud GPUs and usage-based economics
GPU cloud platforms invert this model. Instead of capital expenditure, teams pay for compute as it is consumed. This shifts costs from fixed to variable, aligning spend more closely with actual workload demand.
For inference-heavy systems with fluctuating traffic, this flexibility is critical. Cloud GPUs can scale up during peak usage and scale down when demand subsides, avoiding the cost of idle hardware. Teams also gain immediate access to newer GPU architectures without waiting for procurement cycles or data center upgrades.
The tradeoff is per-hour pricing. Cloud GPUs generally cost more per unit of time than amortized on-prem hardware. However, this comparison is misleading if utilization is not consistently high.
Utilization is the decisive factor
GPU ROI hinges on utilization. A GPU that runs at 90 percent utilization for most of its lifetime delivers strong value, regardless of where it lives. A GPU that sits idle half the time is expensive, even if it was purchased outright.
On-prem environments struggle with utilization because workloads are rarely steady. Training jobs complete, inference traffic fluctuates and capacity planning must account for peak demand. This often leads to overprovisioning and long periods of underuse.
Cloud GPUs excel when utilization is unpredictable. Teams can provision capacity precisely when needed and release it when not, keeping effective utilization high even if raw demand varies.
Training versus inference economics
Training and inference have very different ROI profiles. Training workloads are often bursty but predictable in structure. Large jobs run for days or weeks, then stop. In these cases, on-prem GPUs can make sense if the cluster is consistently busy and models are retrained frequently.
Inference workloads, by contrast, are continuous and volatile. Traffic spikes, seasonal patterns and product launches all affect demand. Provisioning for peak inference load on-prem almost guarantees idle capacity during off-peak periods.
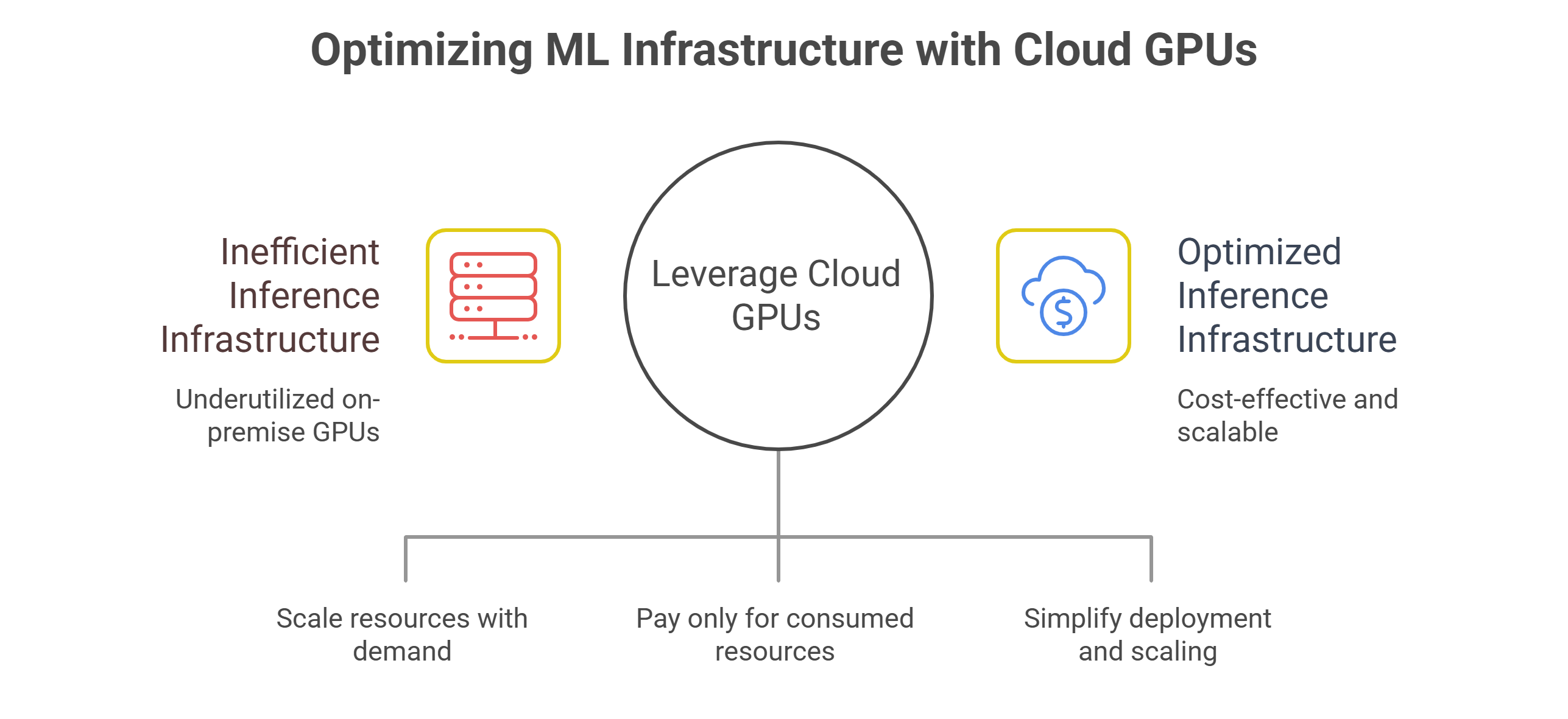
For inference-heavy organizations, cloud GPUs frequently deliver superior ROI because they allow capacity to track demand closely rather than forcing teams to size infrastructure for worst-case scenarios.
Hidden costs that favor cloud
Several costs are often overlooked when evaluating ROI. Hardware refresh cycles consume capital and engineering time. Security and compliance requirements add operational overhead. Geographic distribution introduces latency challenges that require additional infrastructure.
Cloud platforms absorb many of these costs. They handle hardware refresh, physical security and regional availability as part of the service. This allows teams to focus resources on model development and deployment rather than infrastructure management.
There is also an opportunity cost to slow provisioning. Waiting weeks or months to acquire GPUs delays experimentation and product launches. Cloud access eliminates this friction, accelerating iteration and time to market.
Reserved versus on-demand cloud models
GPU cloud ROI is not binary. Many platforms offer both reserved and on-demand pricing models. Reserved capacity reduces per-hour cost in exchange for commitment, while on-demand resources provide flexibility at a premium.
The most efficient strategies combine both. Baseline demand is served by reserved GPUs, ensuring predictable costs, while burst demand is handled by on-demand capacity. This hybrid approach mirrors how workloads actually behave and often outperforms purely owned or purely on-demand models.
ROI improves when teams actively manage this mix rather than defaulting to a single provisioning strategy.
When buying still makes sense
There are scenarios where owning GPUs remains economically sound. Organizations with stable, high-utilization workloads and strong in-house infrastructure expertise can achieve excellent ROI with on-prem clusters. Regulatory constraints or data locality requirements may also favor ownership.
However, these cases require discipline. Clusters must remain well-utilized, refreshed on schedule and integrated into efficient workflows. Without that rigor, ownership quickly becomes a liability.
When renting clearly wins
Renting GPUs typically wins when workloads fluctuate, inference dominates cost or rapid scaling is required. Startups, fast-growing teams and organizations experimenting with new architectures benefit most from cloud flexibility.
Cloud GPUs also make sense when access to cutting-edge hardware matters. Renting allows teams to adopt new GPU generations immediately, avoiding sunk costs in aging infrastructure.
In these environments, ROI is driven less by per-hour pricing and more by speed, adaptability and effective utilization.
ROI as a continuous evaluation
GPU ROI is not a one-time calculation. As models evolve and workloads shift from training to inference, the optimal balance between owned and rented compute changes. Teams that revisit this decision regularly gain a structural advantage.
The most successful organizations treat GPU infrastructure as a portfolio rather than a fixed asset. They combine ownership and cloud strategically, guided by utilization data and business priorities.
Making ROI-driven decisions
The question is not whether renting or buying is universally better. It is whether infrastructure choices align with how GPUs are actually used.
When utilization is high and stable, ownership can pay off. When demand is volatile, scaling matters and inference drives cost, cloud GPUs frequently deliver superior ROI. Teams that understand this distinction avoid dogmatic choices and build infrastructure strategies that evolve with their workloads.
GMI Cloud enables this flexibility by offering both reserved and on-demand GPU capacity, allowing organizations to optimize ROI while maintaining performance and scalability as AI systems grow.
Frequently Asked Questions About GPU ROI: Buying vs. Renting for Production AI
1. What does GPU ROI really depend on when deciding to buy or rent?
It mostly comes down to how much you actually use the GPUs over time. A highly utilized GPU tends to deliver strong ROI whether it’s on-prem or in the cloud, while an idle GPU is expensive even if you own it.
2. What are the hidden costs of owning GPUs beyond the purchase price?
Owning GPUs usually means paying for supporting infrastructure like power, cooling, networking, storage, and physical space, plus the ongoing operational effort of maintaining the cluster. Downtime, hardware failures, and long stretches of underutilization can quietly drag ROI down.
3. Why can cloud GPUs have better ROI even if the hourly price is higher?
Because cloud costs track usage. If your demand isn’t steady, paying more per hour can still be cheaper overall than owning hardware that sits idle during quieter periods.
4. Why is utilization harder to keep high in on-prem GPU environments?
Workloads rarely stay constant. Training jobs finish, inference traffic rises and falls, and capacity is often planned for peak demand, which creates overprovisioning and long periods where GPUs are underused.
5. How do training and inference differ in buy-versus-rent economics?
Training is often bursty but predictable in structure, so on-prem can work well if the cluster stays consistently busy. Inference is continuous and volatile, and provisioning on-prem for peak inference load tends to leave a lot of unused capacity off-peak, which is where cloud flexibility often improves ROI.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
