
This article explains how to deploy multi-modal models as a coordinated cloud pipeline, highlighting the architectural, operational, and scaling challenges that go far beyond serving a single model.
What you’ll learn:
- Why multi-modal deployment should be designed as a pipeline, not around a single “main” model
- How to separate and scale text, vision, audio, and embedding stages independently
- The role of cloud orchestration in managing execution flow and dependencies
- How to reduce latency and cost by minimizing data movement and enabling parallel execution
- Why stage-level scaling, observability, and versioning are critical in production
- How cloud-native pipelines turn multi-modal complexity into a long-term capability
Deploying a multi-modal model is not the same as deploying a single LLM with a few extra inputs. In production, multi-modal systems behave less like a model and more like a coordinated pipeline of specialized components.
Text, vision, audio and embedding models each impose different constraints on compute, memory, latency and scheduling. Bringing them together in a single cloud pipeline requires careful architectural decisions long before the first request reaches a GPU.
Teams that succeed with multi-modal deployment treat the pipeline itself as a first-class system. The goal is not simply to make individual models run fast, but to ensure that the entire workflow remains responsive, scalable and cost-predictable as traffic grows and modalities interact in increasingly complex ways.
Start with the pipeline, not the model
A common mistake is to design multi-modal deployment around a single “main” model and bolt additional components onto it. In reality, multi-modal inference almost always involves multiple execution stages that must be orchestrated explicitly.
A typical request might involve preprocessing an image, generating embeddings, running a text model, invoking a reranker and producing a final response that combines outputs from several modalities. Each step has different execution characteristics and may benefit from different batching, parallelism or GPU types.
Designing the pipeline first forces teams to answer critical questions early: which stages can run in parallel, which must be sequential, where data needs to move and how failures should be isolated. Cloud deployment works best when these decisions are intentional rather than emergent.
Separate concerns across pipeline stages
Multi-modal pipelines become unmanageable when every stage shares the same runtime assumptions. Vision models often require high memory bandwidth and large VRAM. Audio pipelines may be latency-sensitive but lighter on memory. Text generation models typically stress attention mechanisms and benefit from high-memory GPUs.
Deploying all stages on identical infrastructure creates contention and wastes resources. Instead, each stage should be treated as a separate service with its own scaling and scheduling behavior. Cloud environments make this practical by allowing teams to deploy heterogeneous GPU pools under a unified orchestration layer.
This separation also improves resilience. If one modality experiences a spike in demand or a transient failure, it can be scaled or restarted independently without disrupting the rest of the pipeline.
Use orchestration to manage execution flow
Multi-modal deployment relies heavily on orchestration. Requests must be routed through the correct stages, intermediate results passed efficiently and execution coordinated across multiple GPUs.
Container orchestration platforms play a key role here. They allow teams to define explicit execution graphs, manage dependencies and control resource allocation dynamically. More importantly, they enable workload isolation, ensuring that one pipeline does not starve another of GPU resources.
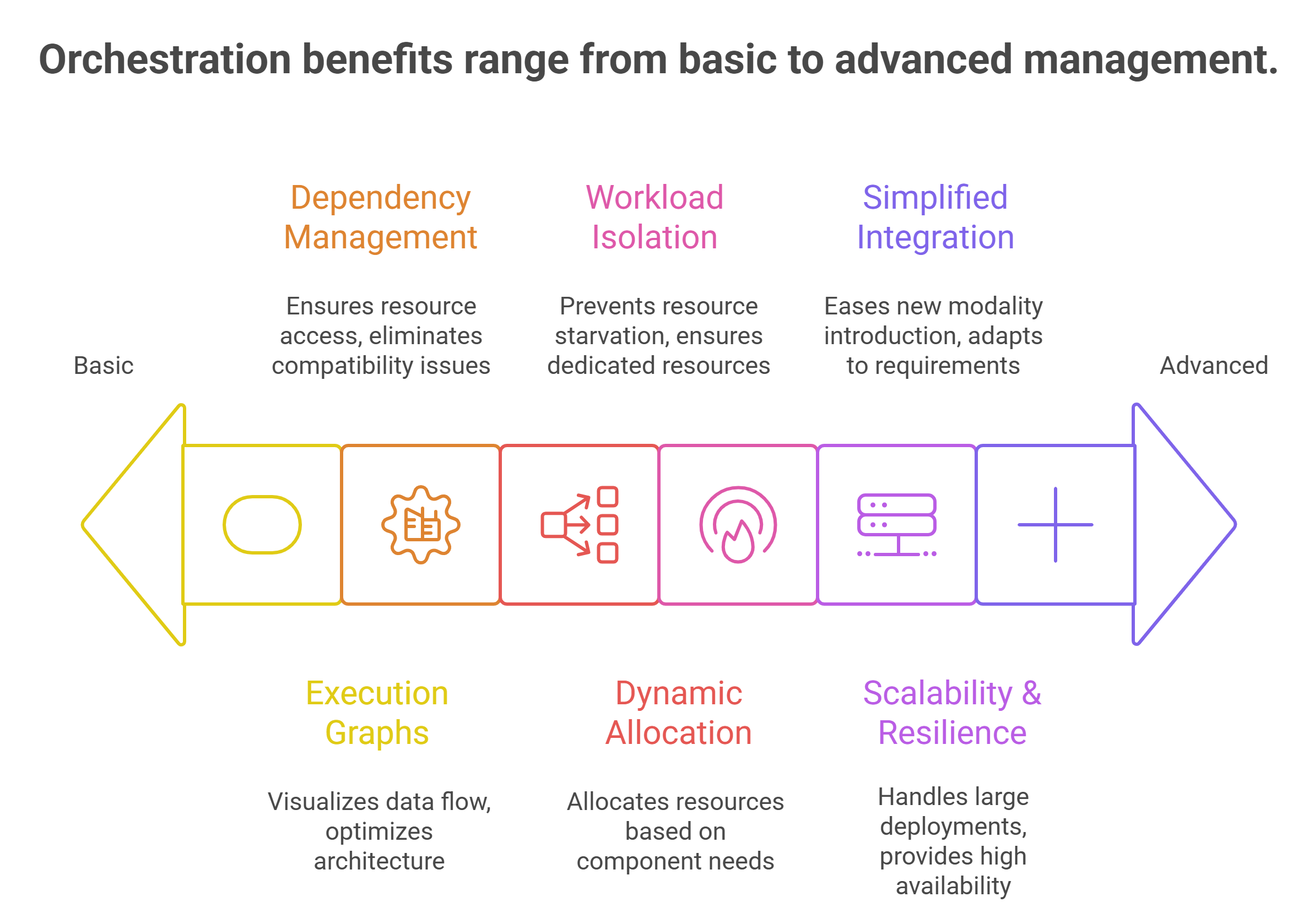
Effective orchestration also makes it easier to introduce new modalities over time. Adding an audio component or a secondary vision model becomes a matter of extending the pipeline rather than rearchitecting the entire system.
Minimize data movement between stages
Data movement is one of the hidden costs of multi-modal deployment. Images, audio streams and embeddings can be large, and unnecessary transfers between CPU and GPU memory or across network boundaries quickly erode performance.
Cloud pipelines should be designed to keep data close to where it is processed. This often means co-locating stages that exchange large intermediate artifacts and using shared memory or high-bandwidth interconnects wherever possible.
Batching strategies also matter. Small batches may reduce latency but increase overhead, while overly large batches can delay downstream stages. The optimal balance depends on the modality and the end-to-end latency target of the pipeline.
Parallelize aggressively where dependencies allow
Multi-modal pipelines often contain natural opportunities for parallel execution. Preprocessing steps, embedding generation and auxiliary model calls can frequently run concurrently with core inference stages.
Failing to exploit this parallelism leads to sequential bottlenecks that dominate end-to-end latency. Cloud GPUs make it possible to fan out work across multiple devices, execute stages concurrently and recombine results efficiently.
The key is understanding dependencies clearly. Parallelization should be applied where outputs are independent or where speculative execution can reduce perceived latency without compromising correctness.
Handle scaling at the stage level, not the pipeline level
Scaling an entire multi-modal pipeline uniformly is rarely efficient. Different stages experience different load patterns depending on user behavior. A spike in image uploads may stress vision encoders while leaving text models underutilized. Agentic workflows may generate bursts of embedding and reranking calls without increasing generation traffic proportionally.
Cloud deployment enables stage-level scaling, where each component responds independently to demand. This keeps GPU utilization high and avoids overprovisioning resources for parts of the pipeline that are not under load.
Autoscaling policies should be informed by modality-specific metrics such as queue depth, latency distributions and GPU memory pressure, rather than generic request counts.
Build observability into the pipeline from day one
Multi-modal systems are difficult to debug without deep visibility. Latency spikes, cost overruns and quality regressions often originate in interactions between stages rather than within a single model.
Production pipelines should expose metrics that reflect the behavior of each modality and the pipeline as a whole. This includes per-stage latency, throughput, error rates and GPU utilization, as well as end-to-end request timing.
Tracing is particularly valuable. Being able to follow a request as it moves through text, vision and audio components helps teams identify bottlenecks and optimize execution paths. Without this visibility, teams are forced to guess where problems originate.
Plan for model versioning and evolution
Multi-modal pipelines evolve continuously. Models are updated, replaced or fine-tuned independently. Deployment strategies must handle this without disrupting the entire system.
Versioning should be handled at the stage level, allowing teams to roll out updates to one modality while keeping others stable. Canary deployments and traffic splitting are especially useful here, enabling teams to validate changes under real traffic before full rollout.
Cloud pipelines support this incremental evolution by decoupling deployment lifecycles from physical infrastructure. Models can be updated or swapped without reconfiguring clusters or provisioning new hardware manually.
Security and isolation across modalities
Each stage in a multi-modal pipeline represents a potential attack surface. Input validation, access control and rate limiting must be applied consistently across modalities, not just at the entry point.
Cloud environments allow teams to enforce isolation between stages, ensuring that compromised components cannot access unrelated models or data. This is particularly important when pipelines process sensitive content or integrate third-party models.
Security should be treated as part of the pipeline design, not an afterthought layered on top.
Why cloud pipelines outperform static deployments
Static deployments struggle with the variability inherent in multi-modal workloads. Fixed GPU assignments, rigid scaling rules and limited observability make it difficult to adapt as pipelines grow more complex.
Cloud pipelines, by contrast, are designed for heterogeneity and change. They allow teams to mix GPU types, adjust scheduling dynamically and evolve pipelines without downtime. This flexibility is what enables multi-modal systems to scale from prototypes to production-grade services.
For teams deploying multi-modal models today, the cloud is not just a convenience – it is the only practical way to manage the operational complexity that comes with combining modalities in a single system.
Turning complexity into capability
Deploying multi-modal models in one cloud pipeline is undeniably harder than serving a single model. But that complexity is also what unlocks richer interactions, more capable systems and better user experiences.
Teams that design multimodal systems around cloud-native pipelines and intelligent orchestration scale faster and more reliably. Without this foundation, infrastructure limits emerge long before model capability does.
Frequently Asked Questions about Deploying Multi-Modal Models in One Cloud Pipeline
1. What makes deploying a multi-modal model different from deploying a single LLM?
Multi-modal deployment behaves less like “one model with extra inputs” and more like a coordinated cloud pipeline of specialized components. Text, vision, audio, and embedding models all have different requirements for compute, memory, latency, and scheduling, so you have to design for the whole workflow—not just one endpoint.
2. Why should teams start with the pipeline design instead of the “main model”?
Because multi-modal inference almost always includes multiple execution stages that need explicit orchestration. If you design around a single main model and bolt everything else on later, you usually end up with unclear dependencies, inefficient execution, and weak failure isolation. Starting with the pipeline forces you to decide early what runs in parallel, what must be sequential, where data moves, and how failures are handled.
3. Should each modality run as its own service in the pipeline?
Yes—treating each stage as a separate service makes the pipeline easier to scale, schedule, and operate. Vision stages may need high memory bandwidth and large VRAM, audio stages may be latency-sensitive, and text generation often benefits from high-memory GPUs. Separating stages also improves resilience because one stage can be restarted or scaled without disrupting the rest of the pipeline.
4. How do you reduce latency in a multi-modal cloud pipeline?
Two big levers are minimizing data movement and parallelizing wherever dependencies allow. Moving images, audio, and embeddings across CPU/GPU boundaries or networks can quietly dominate latency. At the same time, many steps (like preprocessing, embedding generation, and auxiliary model calls) can often run concurrently instead of sequentially—reducing end-to-end response time.
5. What’s the right way to scale a multi-modal pipeline in the cloud?
Scale at the stage level, not the pipeline level. Different modalities get different demand patterns—vision may spike while text generation stays flat, or embedding/reranking can surge without proportional increases in generation traffic. Stage-level scaling keeps utilization higher and avoids overprovisioning parts of the workflow that aren’t under load.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
