Retraining vs. incremental learning: which is more efficient for LLMs?
January 09, 2026

Keeping large language models up to date has become a strategic challenge for engineering teams. Data shifts constantly, product requirements evolve and domain expertise changes faster than traditional training cycles can accommodate. Shipping a model is just the beginning; real reliability comes from how quickly teams can update, correct and extend it as their data and requirements evolve.
The debate often centers on two paths: full retraining and incremental learning. Each offers clear advantages, hidden tradeoffs and very different implications for cost, alignment, performance and operational workflow. Understanding these differences requires looking beyond GPU hours and examining how LLMs absorb new knowledge and how serving architectures behave when weights change.
This article explores both approaches and why many teams ultimately combine them.
Understanding what “retraining” really means for LLMs
Retraining an LLM typically involves taking the original model architecture and running it through a new training cycle, either from scratch or from an earlier checkpoint. For foundation models, this can mean thousands of GPU hours across distributed clusters, massive datasets and intricate data preprocessing pipelines. For smaller domain-specific LLMs, the cost may be lower, but the operational burden remains high.
Retraining offers one major advantage: consistency. The model’s parameters are updated in a unified way, ensuring that new knowledge is integrated throughout the network instead of layered on top. This produces a smoother distribution of internal representations, more stable long-context performance and better alignment when new behaviors need to be deeply fused into the model.
But retraining becomes impractical when:
- the dataset is extremely large
- updates must be delivered weekly or daily
- model architectures evolve between training runs
- inference workloads depend on extremely low latency
- cost constraints make long training cycles unrealistic
For teams working with foundation-scale models, retraining is increasingly viewed as the gold standard for quality – but also the biggest source of delay, expense and infrastructure pressure.
What incremental learning solves
Incremental learning describes methods that allow a model to absorb new information without reprocessing the entire dataset. In the LLM world, this usually appears in three forms:
- Continual fine-tuning: The model is trained on new examples that represent updated knowledge, behavior corrections or domain-specific improvements.
- Low-rank adaptation (LoRA) and parameter-efficient fine-tuning: Instead of updating the full model, small adapter modules modify a subset of parameters. These modules can be swapped in and out without modifying the base model weights.
- Memory-augmented inference: Instead of changing the weights at all, the system relies on retrieval-augmented generation pipelines that feed updated context to the model at inference time.
Incremental learning excels when teams need:
- rapid iteration cycles
- targeted domain expertise
- reduced training costs
- minimal risk to baseline model quality
- isolated changes that don’t affect core behaviors
For fast-moving products – especially those using retrieval-augmented pipelines or agentic loops – incremental learning dramatically shortens the cycle between discovering an issue and deploying an improved model.
Where incremental learning falls short
The tradeoff with incremental approaches is that they patch the model rather than reshape it. They introduce specialized expertise, but they don’t fully re-optimize the internal representations that determine emergent LLM behavior.
Over time, this can lead to:
- parameter drift, where incremental updates accumulate inconsistently
- over-specialization, especially in narrow domains
- interference, where new behavior subtly conflicts with existing knowledge
- performance regressions, especially in long-context or reasoning tasks
- modular bloat, if many adapters pile up over time
Incremental approaches are also less effective when the goal is broad, foundational improvement – for example, upgrading reasoning capabilities, improving cross-modal performance or adapting to major shifts in language patterns.
Where retraining acts like rebuilding a structure from the ground up, incremental learning is closer to adding new rooms and reinforcing specific beams. Both are valid, but they serve different needs.
Efficiency considerations: it’s not just about GPU hours
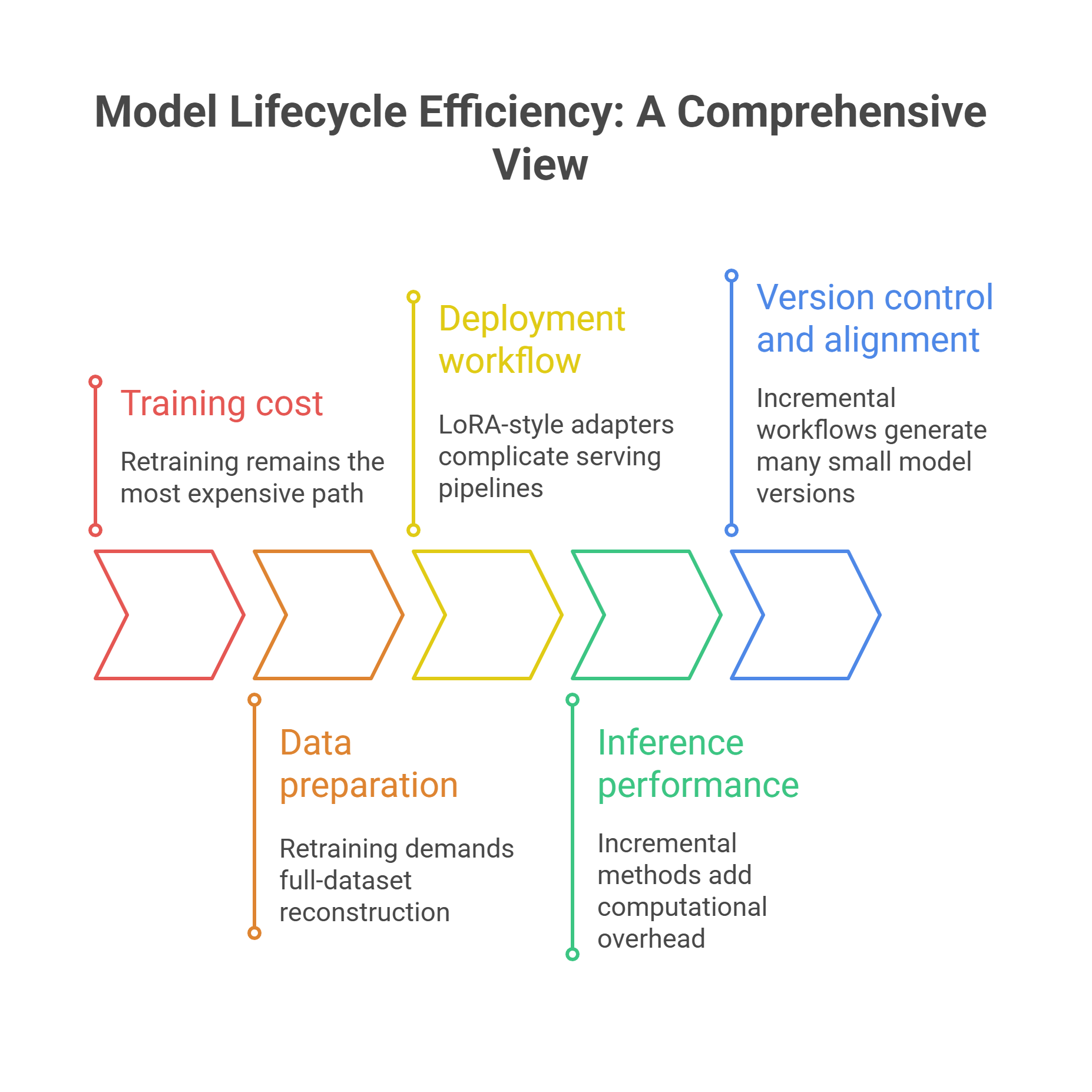
Teams often compare retraining and incremental learning by looking only at training cost – but this is a narrow view. True efficiency spans the entire model lifecycle: data, training, evaluation, deployment and inference.
- Training cost
Retraining remains the most expensive path, especially when datasets are large or when models must be trained across multiple nodes. Incremental methods dramatically reduce training time, sometimes by orders of magnitude.
- Data preparation
Retraining demands full-dataset reconstruction; incremental learning allows selective curation of new examples, which reduces human oversight and preprocessing cycles.
- Deployment workflow
LoRA-style adapters complicate serving pipelines unless platforms support multi-adapter routing. Retrained models are heavier but more straightforward to deploy.
- Inference performance
Incremental methods add computational overhead during inference when multiple adapters or RAG components are involved. Retrained models typically have more consistent latency.
- Version control and alignment
Incremental workflows generate many small model versions that must be tracked, validated and monitored. Retraining keeps versioning simpler but far less frequent.
In practice, the most efficient approach depends heavily on what is changing and how frequently.
When full retraining is worth the cost
Retraining is the better choice when:
- the model must incorporate foundational, cross-cutting improvements
- its reasoning, safety or alignment properties need to be upgraded
- domain shifts require broad re-optimization of representations
- performance regressions from many incremental patches are accumulating
- the LLM is core business infrastructure with strict correctness requirements
Many enterprise teams that rely on mission-critical LLM outputs (finance, medical analysis, legal workflows) prefer periodic retraining to ensure stability, safety and consistent behavior under edge-case inputs.
For these groups, retraining is not just a technical choice, but a governance decision.
When incremental learning wins decisively
Incremental learning outperforms retraining when:
- updates need to be deployed rapidly
- new knowledge is local, not foundational
- GPU budgets are restricted
- different customers require different domain specialties
- personalization or user-specific fine-tuning is required
- inference pipelines rely heavily on retrieval
For SaaS AI companies, agentic applications and fast-moving startups, incremental learning is often the only sustainable pathway.
It enables daily iteration, modular specialization and rapid A/B testing without the operational burden of full retraining cycles.
The most scalable approach: hybrid update strategies
In real production environments, few teams rely exclusively on one method. The emerging best practice is a hybrid approach:
- Incremental learning for rapid updates: Use LoRA modules or targeted fine-tuning for fast iteration, localized corrections and customer-specific customization.
- Periodic retraining for long-term stability: Rebuild the model’s full parameter set at longer intervals to consolidate improvements, eliminate drift and maintain alignment.
This mirrors how human teams learn: quick adjustments day to day, deeper restructuring at longer intervals.
Hybrid strategies also align with modern GPU cloud patterns. Incremental updates run efficiently on small, on-demand GPU pools. Periodic retraining can be scheduled on larger distributed clusters without disrupting latency-critical inference workloads.
Platforms like GMI Cloud support both by offering flexible pricing, high-bandwidth clusters for large-scale training and inference-optimized environments for serving updated models with low latency.
The bottom line
There is no universal winner between retraining and incremental learning – only the right choice for a given workload, update frequency and operational constraint. Retraining provides deeply integrated improvements and long-term stability. Incremental learning delivers fast iteration, lower cost and targeted specialization.
Engineering leaders increasingly choose a blended strategy: incremental updates for agility, periodic retraining for robustness. With LLMs evolving quickly and product cycles accelerating even faster, the future belongs to teams that can combine both approaches efficiently, supported by infrastructure that scales to match their learning loop.
Frequently Asked Questions
1. Why is keeping large language models up to date such a challenge?
Large language models operate in environments where data, product requirements, and domain knowledge change continuously. Traditional training cycles cannot keep pace with this speed of change. Deploying a model is only the first step—long-term reliability depends on how quickly teams can update, correct, and extend the model as conditions evolve.
2. What does retraining an LLM actually involve?
Retraining typically means running the same model architecture through a full training cycle, either from scratch or from an earlier checkpoint. This process updates all parameters in a unified way, leading to more consistent internal representations, better long-context performance, and stronger alignment. However, it requires significant computational resources, time, and operational effort.
3. What problems does incremental learning solve?
Incremental learning allows models to absorb new information without reprocessing the entire dataset. This includes continual fine-tuning, parameter-efficient methods like LoRA, and retrieval-augmented inference. These approaches enable rapid iteration, lower training costs, targeted domain updates, and minimal risk to the base model’s core behavior.
4. Where do incremental learning approaches fall short?
Incremental methods tend to patch the model rather than fully reshape its internal representations. Over time, this can cause parameter drift, over-specialization, interference between behaviors, performance regressions in reasoning or long-context tasks, and growing complexity from accumulating adapters or modules.
5. Why do many teams adopt a hybrid update strategy?
Most production teams combine both approaches to balance speed and stability. Incremental learning is used for fast updates, localized fixes, and customization, while periodic retraining consolidates improvements, removes drift, and restores alignment. This hybrid strategy offers agility in the short term and robustness over the long term.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
