Scaling AI training with hybrid GPU clusters: Combining cloud and on-prem compute
December 09, 2025

This article explores how hybrid GPU clusters—combining stable on-prem hardware with elastic cloud capacity—enable AI teams to scale training faster, reduce costs, and improve throughput across modern ML workflows.
What you’ll learn:
- Why hybrid GPU environments solve challenges that cloud-only or on-prem-only setups can’t
- When hybrid clusters deliver the most training value: base training, fine-tuning bursts, distributed scaling, secure data workflows
- Core architectural requirements: unified orchestration, optimized data movement, intelligent scheduling, consistent runtimes, shared observability
- How hybrid GPU strategies improve cost efficiency and overall resource utilization
- Why GMI Cloud complements on-prem clusters as a seamless elastic extension for large-scale AI training
Training modern AI models pushes infrastructure to its limits, and no single environment can keep up with the shifting demands of large-scale experimentation. One week you need long-running, cost-efficient on-prem GPUs; the next, you need to spin up dozens of cloud GPUs to accelerate fine-tuning or distributed training.
This variability is exactly why hybrid GPU clusters are becoming a strategic advantage. By combining stable on-prem hardware with elastic cloud capacity, ML teams scale training dynamically without sacrificing control or efficiency.
The question isn’t whether hybrid clusters make sense – it’s how to use them to unlock faster iteration and higher throughput at scale.
Why hybrid GPU clusters solve problems that single-environment setups can’t
On-prem GPU infrastructure has its advantages. It provides high availability for core workloads, strong data-governance guarantees and predictable long-term cost structures once the hardware is amortized. But on-prem alone rarely keeps pace with the fluid demands of AI development. Training cycles often require short bursts of massive compute followed by periods of lighter usage – a pattern that on-prem hardware isn’t designed to absorb efficiently.
Cloud GPU platforms solve the opposite side of the problem: rapid elasticity, instant provisioning and access to the latest hardware without long capital cycles. Yet relying exclusively on cloud resources can create volatility in budget planning, and certain workloads – such as those tied to sensitive datasets – are better suited to local environments.
Hybrid clusters bridge these gaps. Stable, long-running training jobs stay on-prem. Elastic cloud GPUs absorb spikes during hyperparameter tuning, large-scale fine-tuning cycles or distributed training runs that benefit from extra parallelization. When orchestrated well, the result is greater throughput, better cost efficiency and an infrastructure strategy that evolves with the organization – rather than locking teams into rigid capacity limits.
When hybrid GPU clusters deliver the most training value
Hybrid setups are not just about overflow capacity. They enable more strategic pipeline design. Some examples:
- Long-duration base training stays on-prem: Teams with large internal clusters can dedicate local GPUs to foundational or multi-week training runs where cost predictability matters more than rapid scaling.
- Cloud GPUs accelerate fine-tuning and experimentation: Sudden training bursts for domain-specific adaptation, LoRA fine-tuning or experimental architectures can be handled by cloud capacity without disrupting core workloads.
- Distributed training becomes easier to scale: When scaling from 8 to 64+ GPUs is needed temporarily, hybrid clusters serve as an extension of on-prem systems rather than a replacement.
- Data-sensitive workloads stay local while compute-intensive tasks burst out: Data preprocessing, filtering or secure training loops can stay in-house, while heavy gradient computation shifts to cloud GPUs.
- Model evaluation and regression testing use cloud GPUs to speed iteration: Running dozens of training variants in parallel becomes feasible without overloading the internal cluster.
In short, hybrid training provides a flexible foundation that adapts to workload patterns rather than forcing ML teams to compromise on performance or cost.
Architecture considerations that make hybrid clusters work
A hybrid environment is only as effective as the infrastructure that connects the pieces. Several architectural pillars determine whether hybrid training is truly scalable:
1. Unified orchestration
Training pipelines should behave identically whether they run on-prem or in the cloud. Kubernetes-native orchestration helps teams standardize container images, job definitions and dependency graphs across environments.
This ensures consistency in scheduling, logging, autoscaling and model tracking – eliminating the “two separate systems” problem that slows down hybrid adoption.
2. Network bandwidth and data movement optimization
Training on cloud GPUs while data lives on-prem creates a bottleneck. High-bandwidth interconnects, smart caching layers and data locality strategies are essential to keep GPUs fully saturated. Efficient synchronization of weights, gradients and checkpoints also prevents cross-environment lag.
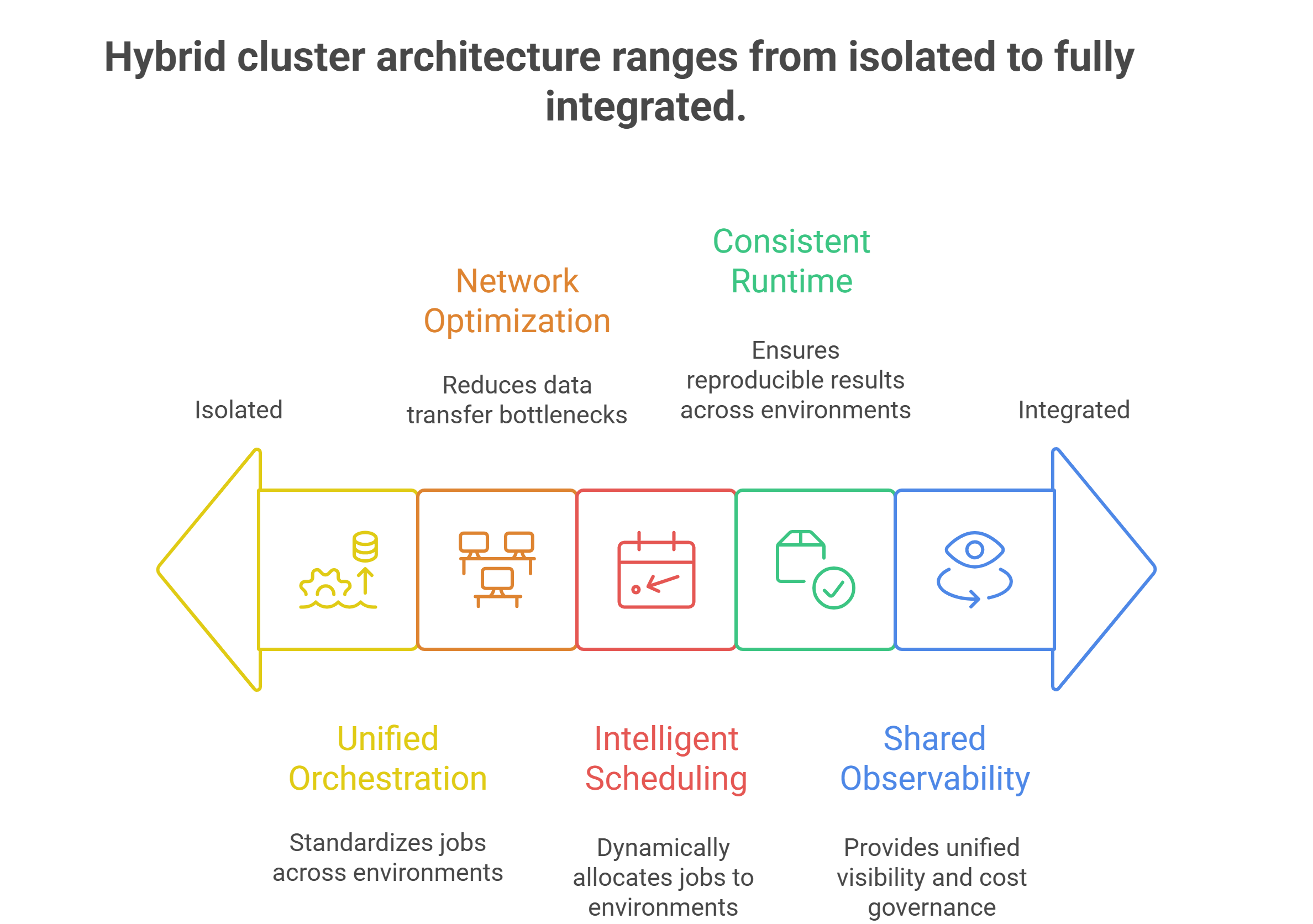
3. Scheduling and resource planning
Hybrid scheduling requires intelligence. Bursting to the cloud should be automatic when local queues build up, not a manual engineering decision. Resource managers must consider GPU availability, job priority, cost and latency to choose the best environment dynamically.
4. Consistent runtime environments
Training jobs should use identical frameworks, drivers, libraries and environment configurations across both clusters. This prevents “works in cloud but not on-prem” issues and preserves reproducibility.
5. Shared observability and cost governance
Teams need visibility into GPU utilization, throughput and spend across both environments. Without unified observability, hybrid setups drift into inefficiency.
These considerations make hybrid clusters function more like a single, elastic GPU environment instead of a patchwork of incompatible systems.
How hybrid training improves cost efficiency and resource utilization
The financial argument for hybrid clusters often comes down to managing variability. Training workloads aren’t linear; they spike and settle. Pure on-prem environments end up overprovisioned. Pure cloud environments can lead to unpredictable bills.
Hybrid GPU clusters deliver several cost advantages:
- On-prem GPUs handle predictable workloads: Jobs that run daily, weekly or monthly can be mapped to stable local capacity, making total cost of ownership more predictable.
- Cloud GPUs eliminate the need to overprovision hardware: Instead of buying hardware for peak usage, teams burst to the cloud only when needed.
- Utilization increases across the entire fleet: On-prem clusters avoid long idle windows, and cloud GPUs scale precisely with demand.
- Training cycles shorten, reducing overall compute waste: Cloud acceleration ensures that experiments and retraining loops finish sooner, reducing total GPU hours consumed.
Hybrid setups balance capital efficiency with operational efficiency – something neither cloud-only nor on-prem-only environments achieve on their own.
Why GMI Cloud complements on-prem clusters for hybrid AI training
GMI Cloud’s infrastructure is built around the idea that training pipelines shouldn’t be constrained by a single environment. For teams with existing on-prem clusters, GMI Cloud acts as an elastic extension that adds capacity, accelerates experimentation and improves scheduling efficiency without forcing a migration or restructuring.
Key advantages include:
- Inference Engine and Cluster Engine integration, enabling unified scheduling, autoscaling and workload placement across environments.
- High-bandwidth GPU clusters for distributed training that requires fast gradient exchange.
- Support for any MLOps stack, ensuring teams can orchestrate hybrid pipelines without locked-in tooling.
- Flexible pricing, allowing predictable on-prem workloads to remain local while cloud costs scale with actual demand.
- Full lifecycle support, so training, fine-tuning, validation and inference can all run on the same cloud architecture.
This lets ML organizations treat cloud GPUs not as a separate system but as a seamless continuation of their existing cluster.
Conclusion
Hybrid environments give AI teams the elasticity of cloud compute without abandoning the performance, governance and cost stability of on-prem hardware. As models grow larger and training pipelines become more complex, hybrid clusters provide a balanced infrastructure strategy that supports both rapid iteration and predictable long-term scaling.
For ML teams balancing speed, cost and flexibility, combining cloud and on-prem GPUs is no longer a fallback – it’s the foundation of scalable AI development.
Frequently Asked Questions About Scaling AI Training with Hybrid GPU Clusters
1. What is a hybrid GPU cluster and why is it useful for large scale AI training?
A hybrid GPU cluster blends on premises GPUs with cloud GPUs so training jobs can run where they perform best. Stable, long running workloads stay local, while sudden spikes in compute needs are handled in the cloud. This flexibility improves throughput and keeps costs under control.
2. When does a hybrid training setup provide the biggest advantages?
Hybrid setups are most valuable when training demand varies. Long duration base training stays on premises, while cloud GPUs accelerate fine tuning, experiments or distributed jobs. Sensitive preprocessing remains local, and evaluation or variant testing can scale out to the cloud for faster iteration.
3. What infrastructure elements are important for a successful hybrid GPU environment?
Effective hybrid clusters depend on unified orchestration, optimized data movement, intelligent scheduling, consistent runtime environments and shared observability. These ensure that workloads behave the same whether they run locally or in the cloud.
4. How does hybrid AI training help reduce costs and improve resource utilization?
Predictable workloads use on premises GPUs with stable costs. Cloud GPUs are used only when needed, avoiding overprovisioning hardware. This increases utilization across both environments and shortens training cycles, reducing total GPU hours consumed.
5. Why is GMI Cloud a strong complement to existing on premises GPU clusters?
GMI Cloud acts as an elastic extension to local infrastructure. It offers unified scheduling, high bandwidth GPU clusters for distributed training, compatibility with any MLOps stack and flexible pricing. This allows teams to scale training without restructuring their existing systems.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
