The future of AI compute economics: why inference clouds are replacing training-first architectures
December 09, 2025

This article examines how AI compute economics are shifting toward inference-first architectures, explaining why modern AI workloads demand elastic scaling, parallel generation, multi-model orchestration, and cost-per-query optimisation rather than traditional training-centric infrastructure.
What you’ll learn:
- Why inference now dominates AI budgets and operational constraints
- How token economics, multimodal workloads and real-time traffic shape compute decisions
- The limitations of training-first clusters under modern inference demands
- Why single-GPU workflows bottleneck iteration speed and product development
- How inference clouds provide elastic scaling, efficient routing and lower cost-per-generation
- The economic risks of closed-source LLMs and the benefits of hosting open-source models
- Industry trends showing broad adoption of inference-optimised platforms
- How composable, multi-stage inference pipelines represent the future of AI infrastructure
AI infrastructure used to be built around one central goal: training increasingly large models. Clusters were architected for massive parallelization, long-running jobs and maximizing throughput on dense compute nodes.
But as organizations shift from model development to real-world deployment, the economics of AI have changed dramatically. Training still matters – but inference now dominates budgets, dictates user experience, and determines whether an AI product is viable at scale.
This transition is reshaping how enterprises think about compute. Instead of investing primarily in training-first architectures, companies are adopting inference-optimized cloud platforms that deliver predictable performance, lower cost-per-query and the flexibility to scale applications in real time. The shift isn’t theoretical – it’s already happening across the industry, driven by token economics, multimodal generation workloads and the operational realities of delivering production-grade AI.
In this article, we explore how AI compute economics are evolving – and why inference clouds are quickly becoming the backbone of modern AI systems.
The imbalance between training cost and inference demand
Enterprises used to train a model, deploy it, and run inference predictably over time. Today’s reality is different. Organizations rely on a growing ecosystem of models – open-source, fine-tuned or fully proprietary – where training is often a one-time cost, but inference is continuous.
Two dynamics now define budgets:
- Inference volume grows exponentially with product success: A model trained once may serve billions of queries over its lifetime. For customer-facing products, inference is the real cost engine.
- Training costs are predictable; inference is not: Training is a scheduled event. Inference demand spikes with traffic, new product features, seasonality or business growth.
This imbalance explains why companies that originally built infrastructure around training are rethinking their approach. A training-first cluster may sit idle most of the time – while inference workloads continually push capacity limits and drive operational costs.
Why inference workloads now dominate compute usage
Inference once meant generating a few hundred tokens from a text model. Now it includes:
- long-context LLM reasoning
- multimodal embeddings
- image, video and audio generation
- streaming inference for agents
- background vector processing
- model chains and pipelines
These tasks operate at massive scale, often running 24/7.
Token economics and cost-per-generation drive infrastructure decisions
The cost drivers are no longer just FLOPs – they are tokens served, images rendered, videos generated, embeddings created and latency guarantees.
For frontier LLM apps, latency and cost-per-query determine the product's margins. For multimodal systems, cost-per-generation becomes even more important. Video models or image diffusion pipelines can cost 10–50x more per output than text generation.
Training expenses matter – but inference now dictates profit margins.
Why training-first architectures fail under inference load
Training environments are built for large batch sizes, heavy synchronization and long-running jobs. Inference has completely different priorities:
- ultra-low latency
- small batches
- unpredictable traffic bursts
- high parallelism
- routing across multiple models
- high availability
- multi-tenant workloads
As a result, training-first clusters hit bottlenecks quickly.
The workflow limitations of single-GPU inference
One of the biggest real-world constraints is surprisingly simple: workflows that only use a single GPU slow teams down dramatically.
Teams increasingly rely on iterative generation workflows that cycle through steps such as generating an output, evaluating and regenerating it, expanding and refining content before upscaling and rerendering, embedding and reranking results, or generating an item and then captioning and augmenting it.
If these steps must run serially on a single GPU, iteration velocity collapses.
This is where inference clouds change the equation: parallel workloads become the default, not the exception. Companies can request multiple generations simultaneously instead of waiting for one GPU to free up.
The bottleneck is no longer compute – it becomes human time, the most expensive resource.
How inference-first clouds solve modern AI requirements
Inference clouds differ from training platforms in several important ways:
1. Elastic scaling for unpredictable demand
Inference workloads spike. Training workloads don’t. Inference-optimized platforms scale in seconds, not hours.
2. Routing and load-balancing built for multi-model environments
Companies increasingly deploy multiple LLMs, embedding models, rerankers, diffusion pipelines, speech models and agents. Training environments aren’t built for this kind of orchestration.
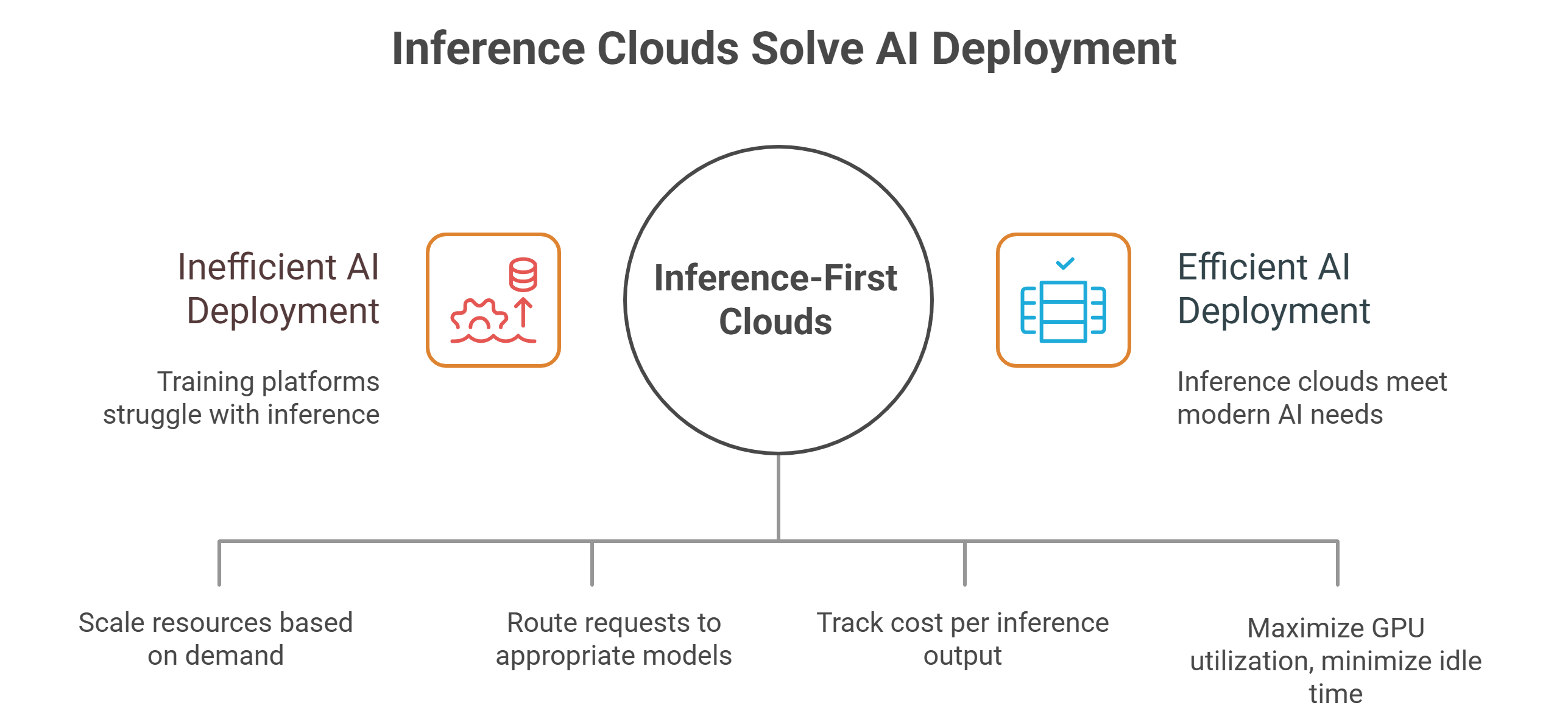
3. Cost-per-inference is the new economic metric
Where training looks at cost per FLOP, inference focuses on:
- cost per token
- cost per image
- cost per second of video
- cost per embedding
- cost per agent step
Inference clouds optimize for these output-level economics.
4. High-throughput generation with no idle GPUs
Inference platforms reduce underutilization by:
- batching compatible queries
- routing to the right GPU type
- parallelizing workloads
- using fractional GPUs
- scaling to zero when idle
This is essential for ROI.
Closed-source proprietary models add economic pressure
Using proprietary closed-source LLMs may simplify early development – but inference costs can quickly overwhelm budgets. Many companies start with API-based inference and end up paying 10–100x more than if they served their own models.
Inference clouds change this equation by allowing teams to:
- host open-source or fine-tuned models
- optimize token-level cost
- exploit batching and parallelism
- run customized routing logic
- avoid per-query pricing altogether
This shift ultimately defines whether a product is economically scalable.
Real-world movement toward inference-first architectures
Industries adopting inference-first cloud strategies include:
- generative AI startups
- e-commerce and personalization platforms
- search and recommendation engines
- gaming and simulation
- robotics systems
- media, entertainment and design tools
- financial analytics and fraud detection
Across these sectors, the same pattern emerges: training is essential, but inference determines operational viability.
Organizations are standardizing around inference-first platforms because they support multi-model deployments, scale elastically with demand, lower cost-per-query, accelerate team iteration, prevent GPU idling and substantially reduce operational overhead.
And most importantly – they remove friction from the product lifecycle.
What the future holds: composable inference and on-demand scaling
The next generation of AI products will rely on composable inference, where systems chain multiple models together, route tasks based on workload type, blend text, vision, audio and structured reasoning, and leverage agents that execute several steps per user query.
Supporting this requires infrastructure that can spin up GPUs instantly, orchestrate multi-stage workflows, route intelligently across diverse models, run highly parallel workloads and maintain predictable cost-per-query even as demand scales.
Inference clouds are built exactly for this future. Training-first systems are not.
Expect enterprises to adopt hybrid strategies where:
- training happens on scheduled clusters
- inference runs on elastic, workflow-driven GPU clouds
- model versions are deployed continuously
- cost economics are tracked per generation, not per GPU hour
This shift is already underway – and accelerating.
The bottom line
AI compute economics now revolve around inference, not training. As model usage scales, so does the cost-per-query, cost-per-generation and latency expectations that define user experience. Inference clouds solve the challenges that training-first architectures were never built to handle: elastic demand, parallel workflows, multi-model routing and tight cost controls.
The winning AI platforms of the next decade will be those that deliver faster iteration, predictable economics and end-to-end control over inference scale.
Frequently asked questions about AI inference clouds and training first architectures
1. Why are companies shifting from training first architectures to inference first clouds?
Because in real products, training is usually a scheduled, one time or occasional cost, while inference runs nonstop and scales with user growth. As models start serving millions or billions of queries, inference dominates both compute usage and budget, so infrastructure has to be optimized around cost per query and latency, not just peak training FLOPs.
2. What is the main economic difference between training and inference workloads?
Training costs are predictable and tied to planned jobs, while inference demand is continuous and spiky, driven by traffic, new features and seasonality. That means inference volume – tokens, images, videos or agent steps generated – becomes the real driver of margins and infrastructure choices.
3. Why do training first GPU clusters struggle with modern inference workloads?
Training clusters are tuned for large batches, heavy synchronization and long running jobs, but inference needs ultra low latency, small batches, unpredictable bursts, multi model routing and high availability. As a result, training first setups often hit bottlenecks, leave GPUs idle and make it hard to serve parallel, multi stage workflows efficiently.
4. How do inference optimized clouds reduce the cost per inference?
Inference clouds are built to batch compatible queries, route traffic to the right GPU type, use fractional GPUs, scale elastically and even scale to zero when idle. Instead of thinking in cost per GPU hour, they optimize around cost per token, cost per image, cost per second of video or cost per agent step.
5. What kinds of AI workloads benefit most from inference first cloud platforms?
Workloads like long context LLM reasoning, multimodal generation, streaming agents, search and recommendation, personalization, fraud detection and media tools all run at high volume, often 24/7. For these use cases, the ability to chain models, run parallel generations and handle multi model pipelines efficiently is far more important than occasional peak training speed.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
