How Managed Inference Platforms Speed Up LLM Inference in Production? (2026 Guide)
Managed inference platforms accelerate Large Language Model (LLM) production workloads not merely by providing hardware, but by implementing a sophisticated stack of kernel-level optimizations. GMI Cloud’s Inference Engine integrates Continuous Batching , PagedAttention , and FP8
February 21, 2026
In production environments, the speed of LLM inference is defined by two metrics: Time to First Token (TTFT), which impacts the user's perceived responsiveness, and Tokens Per Second (TPS), which dictates the total system throughput. Optimizing these metrics requires deep engineering across the entire stack, from the GPU memory controller to the API gateway.
Self-hosting models using raw Docker containers often leaves significant performance on the table. Managed platforms like GMI Cloud abstract away the complexity of CUDA kernel tuning, memory management, and request scheduling. This guide dissects the specific engineering mechanisms used by these platforms to achieve superior performance.
The Anatomy of Inference Latency
To understand acceleration, one must first understand where time is lost. An inference request consists of two distinct phases:
- Prefill Phase (Compute Bound): Processing the input prompt to generate the initial KV cache. This phase is highly parallelizable and depends heavily on the GPU's TFLOPS capability. For long prompts (e.g., RAG contexts), this can cause significant "Head-of-Line Blocking."
- Decode Phase (Memory Bound): Generating output tokens one by one. Since each token generation requires loading the entire model weights and the specific request's KV cache from HBM (High Bandwidth Memory), this phase depends almost entirely on Memory Bandwidth (HBM3e speed).
Managed platforms utilize different strategies to optimize each phase. For example, GMI Cloud utilizes the H200's Transformer Engine to accelerate the prefill phase via FP8 tensor operations, while using PagedAttention to maximize bandwidth efficiency during the decode phase.
Core Acceleration Technologies
Modern managed inference platforms integrate advanced serving engines (such as optimized forks of vLLM or TensorRT-LLM) that implement the following key technologies. These features are standard in our Inference Engine.
Continuous Batching (Iteration-Level Scheduling)
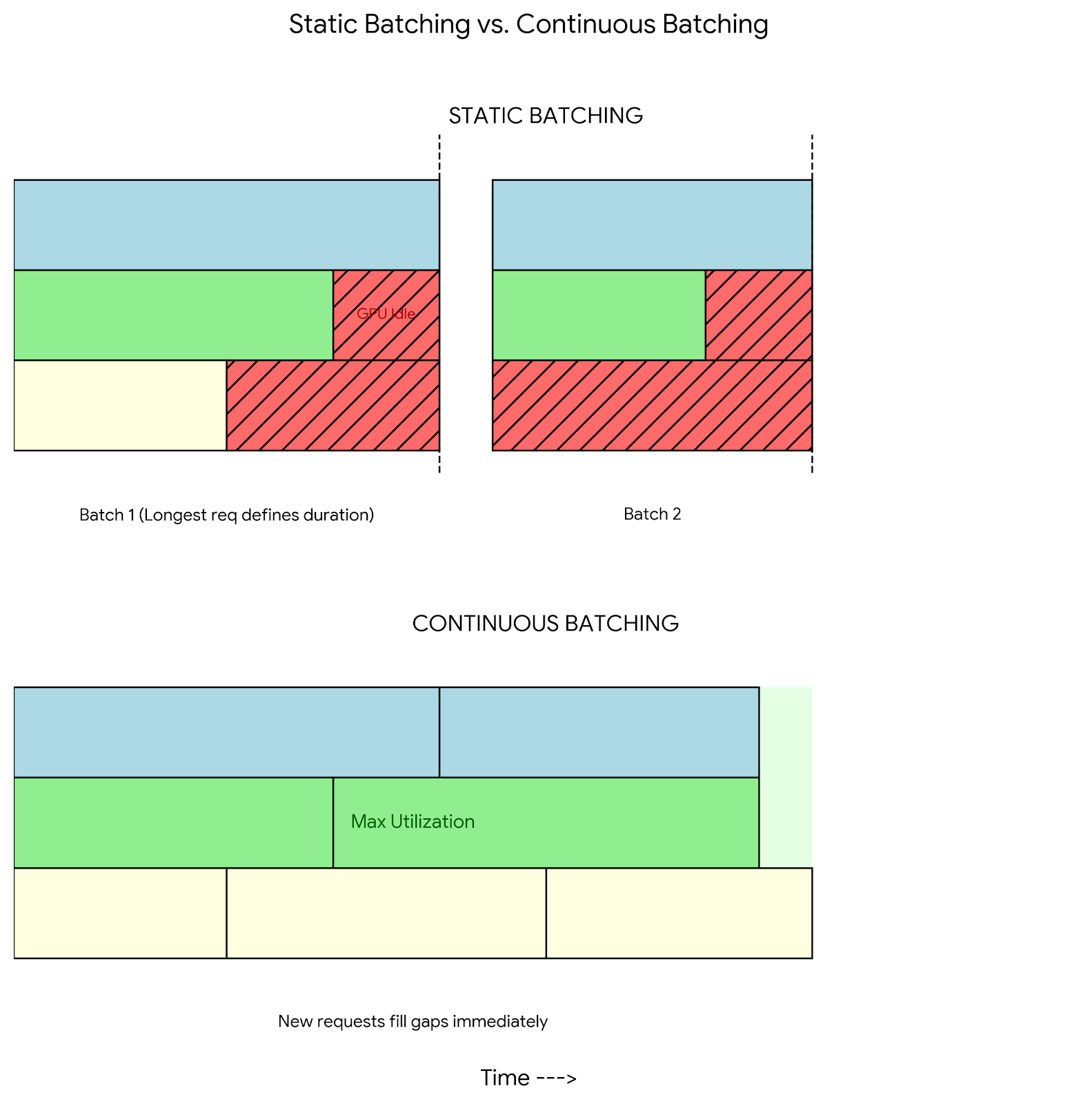
Traditional "Static Batching" waits for all requests in a batch to finish before processing new ones. If a batch contains one short request (10 tokens) and one long request (500 tokens), the GPU effectively idles for the duration of the 490 tokens, wasting cycles.
Continuous Batching (also known as cellular batching) solves this by scheduling at the iteration level. Once a sequence emits an "End of Sequence" (EOS) token, the inference engine immediately ejects it from the batch and inserts a new prefill request from the queue. This ensures that the GPU Compute Units (SMs) remain fully saturated at all times.
Impact: On GMI Cloud's H200 clusters, Continuous Batching increases GPU utilization from ~40% (static) to >90%, effectively doubling throughput without adding hardware. This efficiency is a key driver in reducing cost per token.
PagedAttention: Solving Memory Fragmentation
LLM inference is memory-hungry, primarily due to the KV-Cache (Key-Value Cache), which stores attention context for each token. In standard deployments, memory must be pre-allocated contiguously based on the maximum possible sequence length. This leads to significant fragmentation and waste (up to 30% of VRAM), known as "internal fragmentation."
Inspired by OS virtual memory paging, PagedAttention allows the KV-Cache to be stored in non-contiguous memory blocks. The inference engine maintains a "Block Table" that maps logical tokens to physical memory blocks. This allows GMI Cloud to fit significantly larger batches into the H200's 141GB memory, reducing the frequency of memory swapping and increasing maximum concurrency.
Chunked Prefill
For workloads involving RAG (Retrieval Augmented Generation) with long context windows (e.g., 32k or 128k tokens), the prefill phase can take hundreds of milliseconds, blocking the GPU from performing decoding steps for other users. This creates "latency spikes" for other concurrent requests.
Managed platforms implement Chunked Prefill. Instead of processing a massive prompt in one go, the engine splits the prompt into smaller chunks (e.g., 512 tokens). It processes a chunk, then performs a decode step for other users, then processes the next chunk. This time-slicing approach ensures that a single heavy request does not degrade the P99 latency for the entire cluster.
Hardware Acceleration: The Role of H200 and FP8
Software optimization can only go so far without the right hardware. Managed platforms leverage the specific features of the NVIDIA Hopper architecture found in our GPU Instances.
FP8 Quantization and The Transformer Engine
The NVIDIA H100 and H200 GPUs introduce native support for FP8 (8-bit Floating Point) data types. Unlike INT8 quantization which requires complex calibration, FP8 is supported natively by the hardware's Transformer Engine. By quantizing model weights and activations from FP16 to FP8, managed platforms achieve:
- 2x Reduction in Memory Footprint: Allowing 2x larger models or batch sizes to fit in VRAM. This is crucial for serving 70B+ models on fewer GPUs.
- 2x Increase in Theoretical TFLOPS: Utilizing the Transformer Engine's FP8 tensor cores to accelerate matrix multiplications.
- Reduced Memory Bandwidth Pressure: Since weights are half the size, they load twice as fast from HBM.
GMI Cloud's Model Library serves models like Llama 3 70B in FP8 by default. We perform rigorous offline calibration to ensuring that the PPL (Perplexity) degradation is negligible (<1%).
Advanced Acceleration: Speculative Decoding
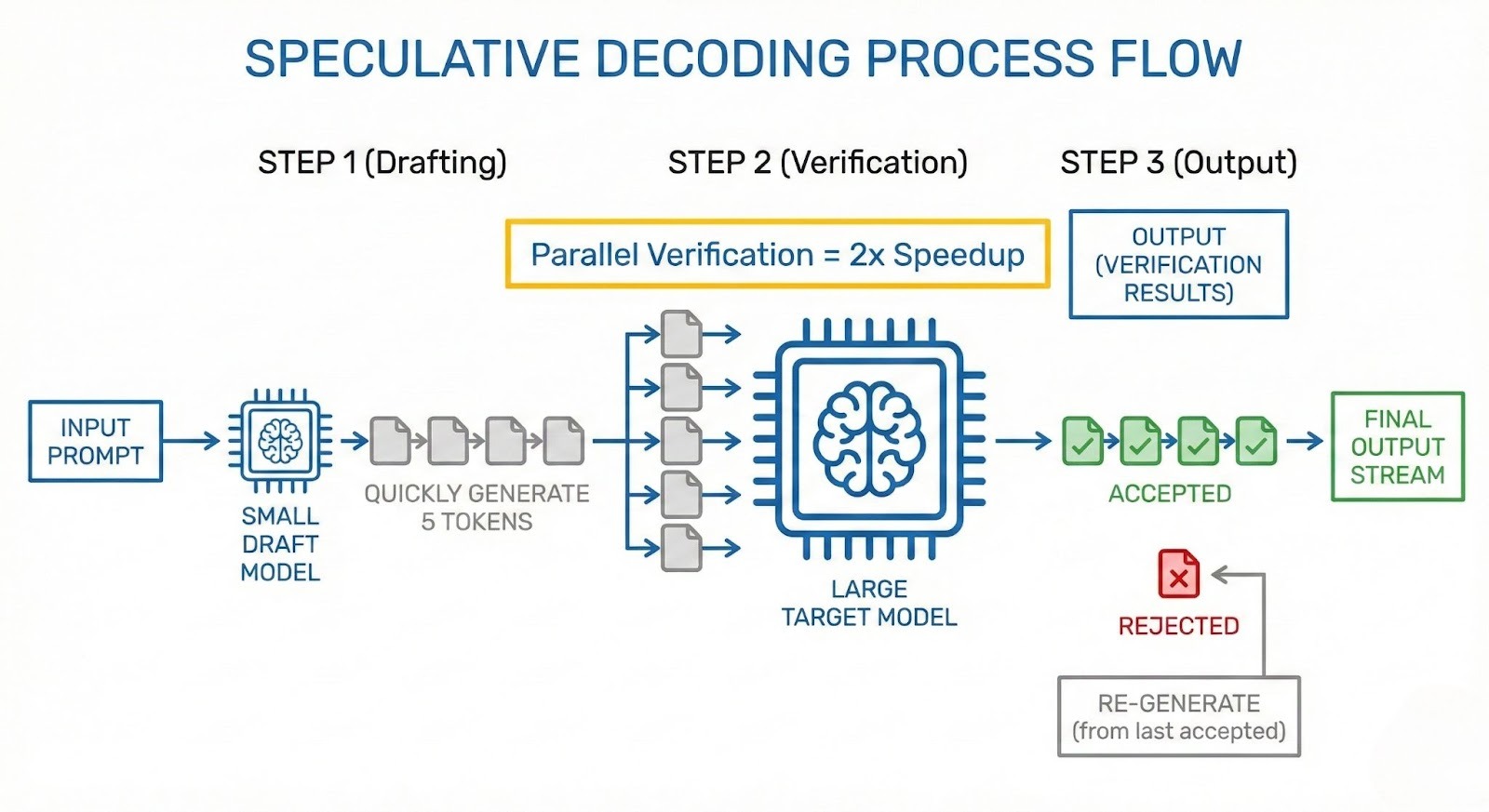
For applications requiring ultra-low latency (e.g., voice assistants or real-time coding agents), Speculative Decoding is a game-changer. This technique breaks the serial dependency of auto-regressive generation.
It uses a smaller, faster "draft model" (e.g., Llama 3 8B) to generate a sequence of tokens speculatively (e.g., 5 tokens). The larger "target model" (e.g., Llama 3 70B) then verifies these tokens in a single parallel step. Because the target model can verify 5 tokens in roughly the same time it takes to generate 1 token, successful speculations lead to massive speedups.
GMI Cloud's infrastructure is optimized to co-locate draft and target models on the same H200 GPU, ensuring zero PCIe latency between the two models during the verification step. This is far more efficient than splitting them across devices.
Configuration for Speed
The following example shows how GMI Cloud configures the serving engine for maximum speed using Speculative Decoding:
# Server-side configuration for GMI Inference Engine
model_config:
name: llama-3-70b-instruct
backend: tensorrt-llm
parameters:
speculative_decoding_mode: draft_model
draft_model_name: llama-3-8b-instruct
num_draft_tokens: 5
quantization: fp8
max_batch_size: 128
Network Optimization: RDMA and Bare Metal
For models that span multiple GPUs (Tensor Parallelism), the communication between GPUs becomes a critical path. In a 70B model spread across 4 GPUs, every token generation requires an "All-Reduce" operation to synchronize partial results.
Managed platforms on Hyperscalers often use virtualized networking (overlay networks), which adds latency to every packet. GMI Cloud utilizes Bare Metal instances connected via 3.2 Tbps InfiniBand.
GPUDirect RDMA
This technology allows GPUs to exchange tensor data directly with the Network Interface Card (NIC), bypassing the host CPU and OS kernel entirely. This reduces inter-tensor communication latency from microseconds to nanoseconds. For multi-node inference (e.g., DeepSeek 671B), this network advantage is the difference between a usable 20 TPS and an unusable 5 TPS.
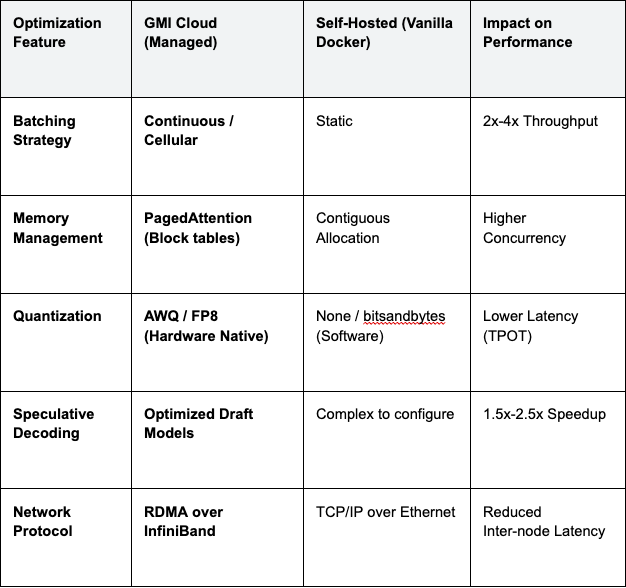
Architecture Comparison: Managed vs. Self-Hosted
The table below compares the performance features available out-of-the-box on a managed platform versus a typical self-hosted setup.
Table 1: Inference Stack Capabilities
Operationalizing Performance: Metrics That Matter
To maintain high speed in production, you must monitor the right signals. GMI Cloud exposes granular metrics via our observability stack.
KV Cache Utilization
This metric tells you how full your GPU memory blocks are. If this hits 100%, the engine must evict requests, causing massive latency spikes (re-computation). We recommend auto-scaling when KV Cache utilization hits 85%.
Inter-Token Latency (ITL)
For streaming applications, ITL is the "smoothness" metric. Users perceive jitter if ITL variance is high. Bare Metal isolation ensures ITL remains consistent by removing "noisy neighbor" interference from the CPU.
FAQ: Inference Performance
Q: Does FP8 quantization degrade model accuracy?
No, generally negligible. For most generative tasks, FP8 quantization results in less than 1% degradation in perplexity scores while delivering 2x performance gains. GMI Cloud validates all quantized models against standard benchmarks (MMLU, HumanEval) before release to the Model Library.
Q: How does Continuous Batching affect per-user latency?
It improves P99 latency. While it focuses on throughput, by preventing "head-of-line blocking" where short requests wait for long requests, it significantly reduces the tail latency (P99) for all users in the system.
Q: Can I use custom CUDA kernels on GMI Cloud?
Yes. On our Dedicated Bare Metal instances, you have full root access to install custom CUDA drivers and compile bespoke kernels (e.g., using Triton DSL) to optimize for your specific model architecture.
Q: What is the fastest instance type for Llama 3 70B?
The H200. Due to the memory bandwidth bottleneck of the 70B model, the H200 (4.8 TB/s) significantly outperforms the H100 (3.35 TB/s) and A100 (2.0 TB/s), offering the lowest TPOT. Check Pricing for availability.
What's next
- Benchmark your model on our Demo Apps to see acceleration in real-time.
- Read the Inference Engine Documentation for integration details.
- Explore Pricing Options for Bare Metal H200 clusters.
Colin Mo
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
