We Benchmarked the Best Video AI Models
We present a commercial-grade, multi-dimensional evaluation pipeline leveraging GMI Cloud’s large-scale dataset and RAG annotation. The framework evaluates six key dimensions—aesthetic quality, background consistency, dynamic degree, imaging quality, motion smoothness, and subject consistency—producing both aggregate scores and detailed diagnostic insights.
December 08, 2025

This is a technical overview of our upcoming ModelMatch feature, scheduled to be released alongside GMI Studios (coming soon!)
Credits go to main researcher: Chaos Hong, MLE researcher at GMI Cloud
Technical Overview editor: Colin Mo, Head of Content at GMI Cloud
Abstract
We present a commercial-grade, multi-dimensional evaluation pipeline leveraging GMI Cloud’s large-scale dataset and RAG annotation. The framework evaluates six key dimensions—aesthetic quality, background consistency, dynamic degree, imaging quality, motion smoothness, and subject consistency—producing both aggregate scores and detailed diagnostic insights.
Key Takeaways:
- Veo3 achieves the highest overall score with consistent, balanced performance.
- Kling-Image2Video-V2-Master excels in specialized dimensions, ideal for targeted, high-fidelity applications.
- Multi-dimensional metrics provide a nuanced understanding of model capabilities, enabling data-driven, customer-specific deployment decisions.

1. Introduction
As AI-generated video rapidly transforms advertising, entertainment, and social media, the real challenge for businesses is identifying which models deliver reliable, high-quality results at scale.
Video generation is moving into commercial applications, from content creation to personalized media. With access to a large-scale generated video dataset, GMI Cloud provides a unique platform to benchmark models under realistic, production-level conditions.
Evaluating video generation remains challenging:
- Caption-to-video alignment is imperfect, limiting the reliability of text-based metrics.
- Existing benchmarks are single-dimensional, often ignoring motion, consistency, or imaging quality.
- Diagnostic insights are limited, making it difficult to understand why a model succeeds or fails.
Our goal is to build the first commercial-grade, multi-dimensional evaluation pipeline for AI video generation. This framework delivers robust, multi-aspect metrics and actionable insights, enabling model selection and customer-specific optimization.
All evaluations were conducted using GMI Cloud’s elastic GPU clusters and inference pipelines—the same infrastructure available to customers for real-time video AI deployment. This ensures that benchmark results directly reflect the performance businesses can achieve in production.
1.1 Industry Impact
This benchmark provides tangible benefits across the AI video ecosystem:
- Model developers gain insights to fine-tune performance across multiple dimensions.
- Content creators and enterprises receive data-driven guidance for selecting the right AI video model for their needs.
- GMI positions itself as a neutral, commercial-grade evaluator, bridging the gap between academic benchmarks and real-world business requirements.
1.2 About GMI cloud
GMI Cloud provides next-generation AI infrastructure for builders, offering scalable GPU clusters, inference engines, and model evaluation pipelines. Our platform enables anyone to build, evaluate, and deploy AI at scale, removing technical barriers and accelerating commercial adoption.
2. Methodology
2.1 Data Collection
We collected a large-scale dataset of generated videos along with their corresponding prompts from GMI Cloud. The dataset is representative of real-world generation scenarios, providing a solid foundation for evaluating model performance under practical conditions.
2.2 Annotation and Labeling
We annotated video samples using two AI-assisted tools: RAG (Retrieval-Augmented Generation) and DeepSeek.
- RAG helps us quickly gather relevant reference information. It uses a predefined list of prompts that combines examples from VBench, Video-Bench, and Eval-Craft, making sure our videos cover a wide variety of scenarios—different styles, motions, and content types.
- DeepSeek works alongside RAG to analyze the videos themselves, helping to automatically assign labels or scores to different quality dimensions, such as motion, aesthetics, and consistency.
Together, these tools allow us to efficiently annotate large datasets while maintaining diverse coverage and reliable dimension-level evaluations, without needing to manually watch and score thousands of videos.
Takeaway: This hybrid approach combines the strengths of reference-based retrieval (RAG) and direct video analysis (DeepSeek), giving us a scalable, automated way to annotate and evaluate generated video content.
2.3 Evaluation Framework
Our evaluation builds on VBench/F-Bench/VM-Bench, with extensions designed for commercial-scale video generation:
- Supports multi-GPU parallel computation for efficient large-scale evaluation.
We assess video quality along six key dimensions:
- Aesthetic Quality – overall visual appeal of frames (how visually pleasing the video is; measured using a LAION aesthetic predictor: CLIP + regressor/MLP).
- Background Consistency – stability and coherence of background across frames (how well the scene environment stays consistent; measured via CLIP).
- Dynamic Degree – richness and diversity of motion (how much activity and movement the model generates; measured with RAFT optical flow).
- Imaging Quality – resolution, sharpness, and absence of noise or artifacts (technical quality; measured using MUSIQ trained on SPAQ).
- Motion Smoothness – temporal continuity and fluidity (how smooth and natural the motion appears; measured with VBench’s frame interpolation model).
- Subject Consistency – preservation of key objects or subjects across frames (whether the main characters or objects stay consistent; measured using DINO features).
Note: using vllm(tarsier-7b) is also applicable, new benchmarks in ICCV 2025 coming soon.
2.4 Statistical Scoring
Scoring and Aggregation Methodology
- Score Normalization: All dimension scores are scaled to a 0–1 range, so readers can easily interpret high vs. low performance.
- Outlier Removal: To avoid skewed results, we discard the top 5% and bottom 5% of scores for each dimension. This ensures that extremely good or bad cases don’t distort the evaluation.
- Dimension-Level Scoring: Each video is scored separately for each of the six dimensions (aesthetic quality, background consistency, dynamic degree, imaging quality, motion smoothness, subject consistency).
- Aggregate Score: After dimension-level scoring, an overall total score is computed using weighted combination of the dimensions.
- Outputs: The evaluation produces tables, charts, and summaries, enabling both quick quantitative comparisons and actionable insights for model selection.
3. Results
3.1 Overall Model Ranking
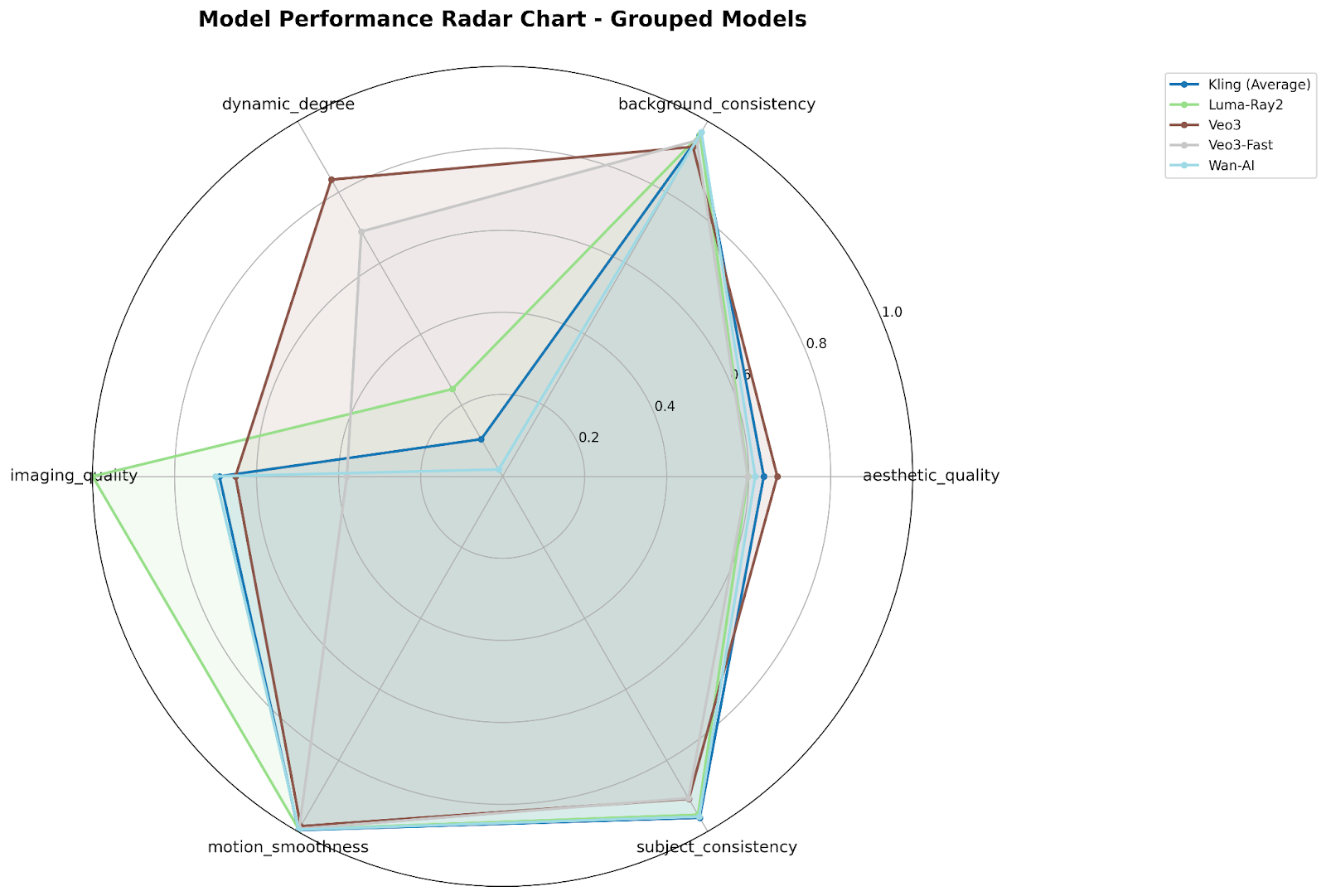
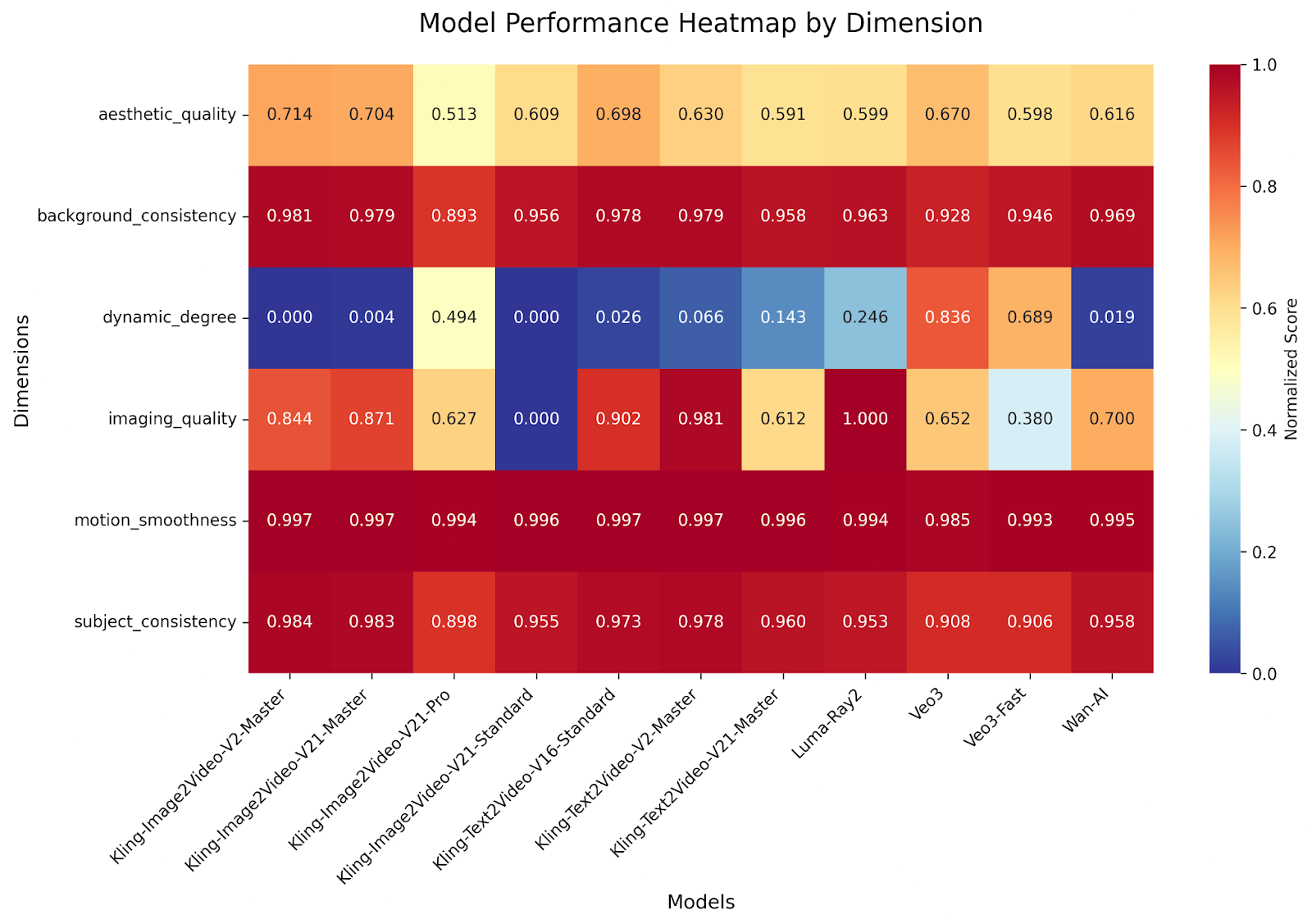
We evaluated 271 videos generated by five major model families on GMI Cloud infrastructure, scoring them across six key dimensions: background consistency, aesthetic quality, subject consistency, dynamic degree, imaging quality, and motion smoothness. Each dimension was normalized between 0–1 and weighted (dynamic degree=0.1, others=1.0) to produce an overall ranking that informs practical decision-making.
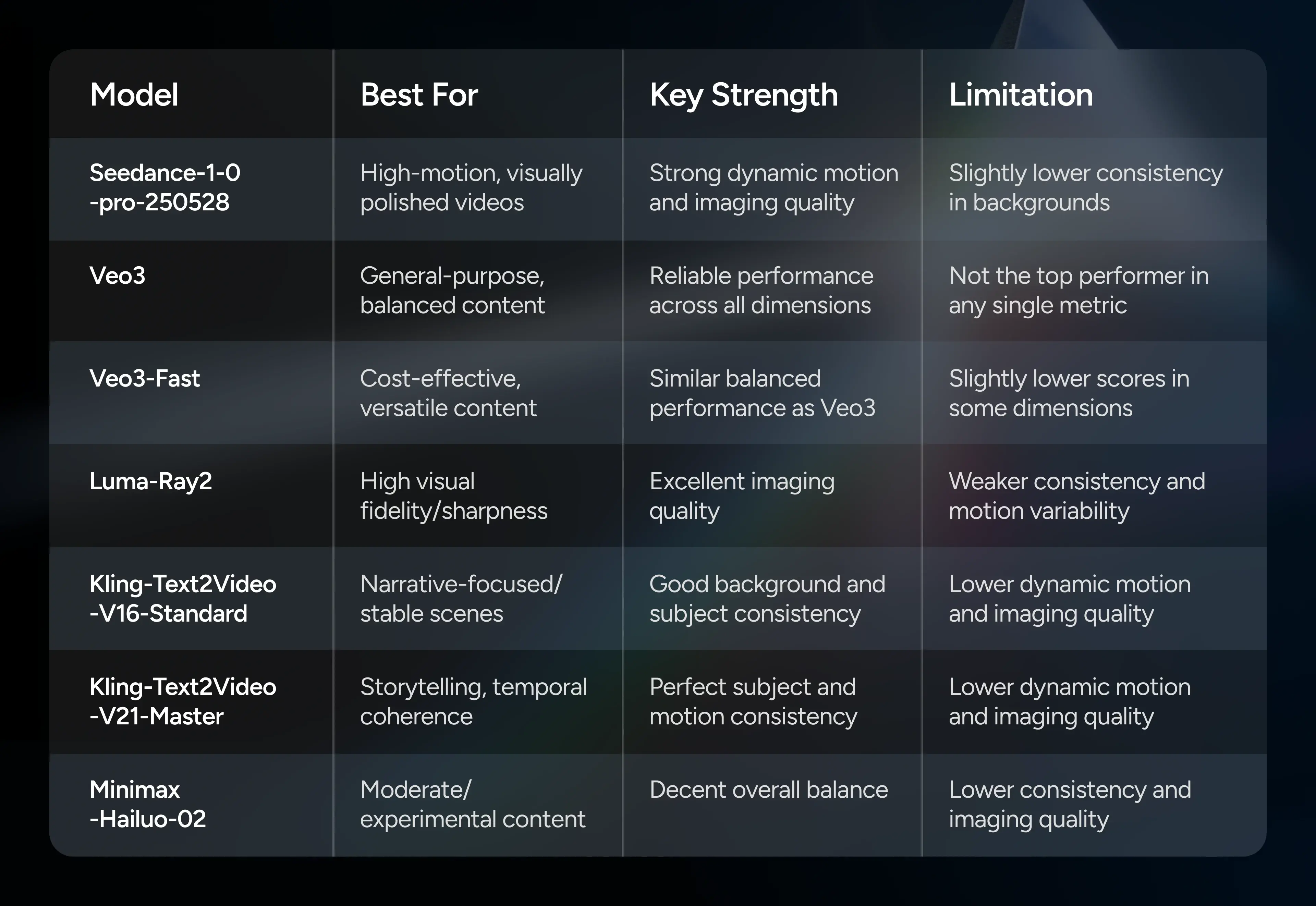
- seedance-1-0-pro-250528 led with a score of 12.8784, excelling in motion energy and imaging quality, making it ideal for high-action, visually polished content.
- Veo3 scored 12.0860, offering balanced performance across all dimensions, suitable for versatile, general-purpose video generation.
- Veo3-Fast closely followed at 12.0829, providing a lighter, cost-effective alternative with similar capabilities.
- Luma-Ray2 achieved 12.0080, strong in dynamic motion but slightly weaker in consistency.
- Kling variants (Text2Video-V16-Standard and V21-Master) ranked 5th–6th, demonstrating specialized strengths in consistency and motion smoothness.
- Minimax-Hailuo-02 scored 11.3902, with lower consistency and imaging quality, making it less suitable for high-demand scenarios.
Takeaway: Seedance-1-0-pro-250528 delivers peak performance for high-motion and technically demanding videos, while Veo3 offers a balanced, reliable choice for a broad range of applications.
3.2 Best Performing Model by Dimension
Breaking down performance by dimension highlights which models excel for specific business needs:
- Background Consistency: Kling-Text2Video-V21-Master (1.000) ensures perfect environmental stability.
- Aesthetic Quality: seedance-1-0-pro-250528 (1.000) produces highly polished, visually appealing outputs.
- Subject Consistency: Kling-Text2Video-V21-Master (1.000) keeps characters or key objects stable across frames.
- Dynamic Degree: seedance-1-0-pro-250528 (1.000) generates the most energetic, engaging motion.
- Imaging Quality: seedance-1-0-pro-250528 (1.000) ensures crisp, high-resolution output.
- Motion Smoothness: Kling-Text2Video-V21-Master (1.000) delivers fluid, natural movement.
Takeaway: Multi-dimensional evaluation reveals complementary strengths, guiding clients to choose models based on specific priorities—motion, stability, or overall polish.
3.3 Performance Consistency Analysis
Consistent performance across diverse prompts is critical for production reliability and scalability:
- seedance-1-0-pro-250528 shows strong consistency in dynamic degree and imaging quality, but slightly lower in background and motion smoothness.
- Kling-Text2Video-V21-Master excels in background and subject consistency, but lower in motion energy and imaging quality.
- Veo3 and Veo3-Fast maintain balanced stability across all dimensions, making them reliable for general-purpose deployment.
- Luma-Ray2 and Minimax-Hailuo-02 show trade-offs, e.g., Luma-Ray2 excels in motion but is less consistent; Minimax-Hailuo-02 performs moderately across the board.
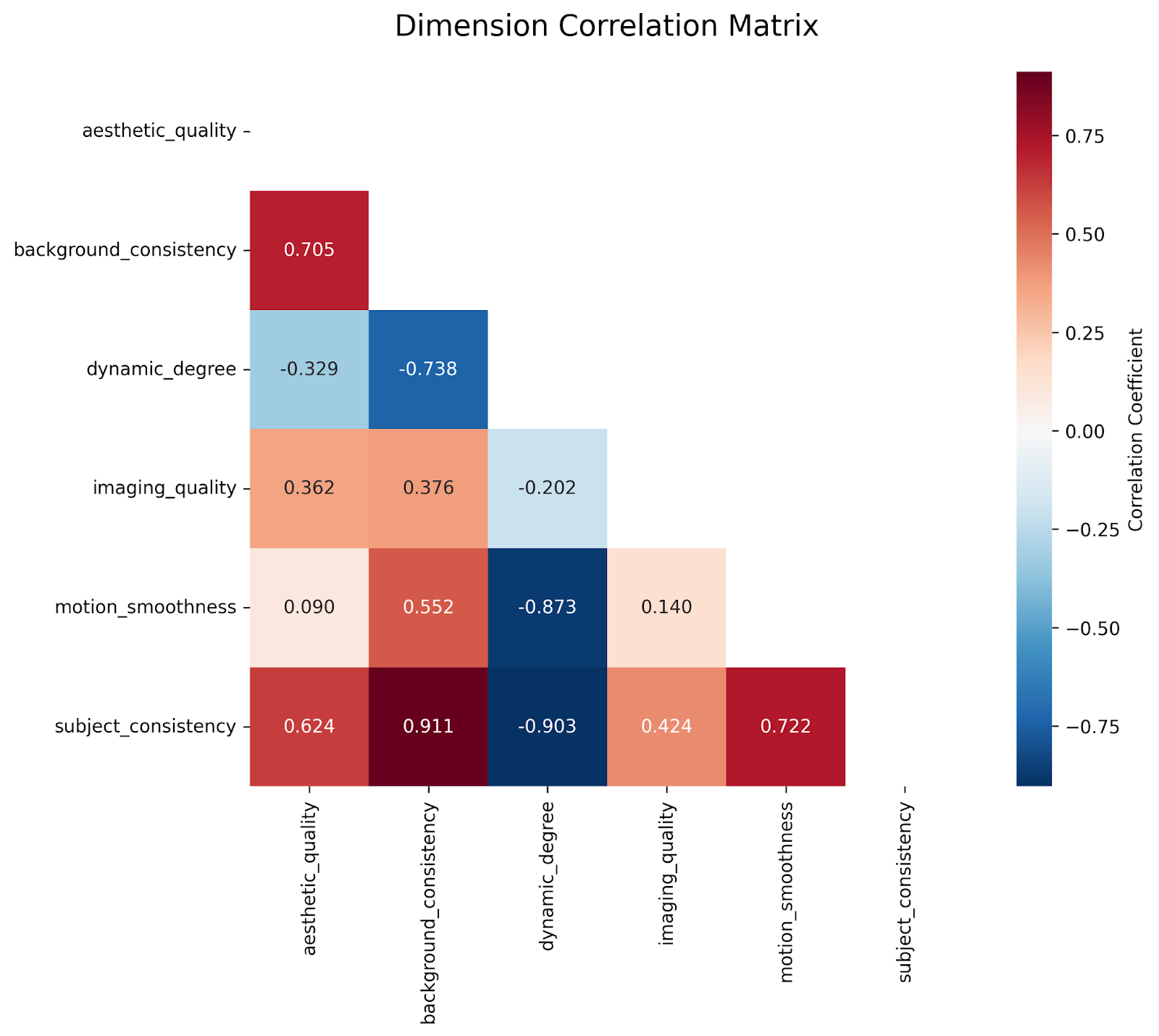
3.4 Correlation Analysis
A correlation heatmap was generated across the six evaluation dimensions to examine interdependencies between metrics. Preliminary observations include:
- Strong correlation between motion smoothness and background consistency, indicating models that handle temporal coherence well also maintain stable backgrounds.
- Aesthetic quality shows moderate correlation with imaging quality but weak correlation with dynamic degree, highlighting that visual appeal is not always tied to motion richness.
4. Limitations & Future Work
Limitations:
- Current evaluation dimensions (background, motion, aesthetic, etc.) may not fully reflect how humans judge videos, e.g., narrative coherence or emotional impact.
- Correlating AI evaluation scores with human preferences is not straightforward; traditional correlation metrics are insufficient, requiring more advanced mathematical approaches.
- Current multimodal LLMs are not yet strong enough to provide fully automated, reliable human-like evaluations.
Future Work:
- Explore human-in-the-loop evaluation to validate and refine AI-based scoring.
- Develop LLM-powered evaluators capable of assessing complex narrative and semantic aspects automatically.
- Leverage this benchmark to build autonomous video optimization agents, akin to automatic Photoshop workflows, that iteratively improve video quality for specific business scenarios.
Takeaway: Addressing these limitations will enhance evaluation fidelity, alignment with human perception, and practical deployment, positioning this benchmark as a foundation for next-generation AI video tools.
5. Discussion and Conclusion
5.1 Discussion
Our evaluation of 271 videos across five major model families reveals several practical insights for model selection:
Overall Performance vs. Dimension-Specific Strengths
- Veo3 leads in overall score, offering balanced, reliable performance across all six dimensions.
- Kling-Image2Video-V2-Master, though slightly lower overall, excels in background consistency, motion smoothness, and subject fidelity, making it ideal for applications requiring specific quality attributes.
Performance Consistency Matters
- Models such as Veo3 and Kling-Image2Video-V21-Pro exhibit low score variability, ensuring stable performance across diverse prompts.
- Some models with high individual scores show higher variance, signaling potential reliability issues in production.
Performance Patterns Across Dimensions
- Kling-Image2Video-V2-Master shines in temporal coherence and subject stability.
- Luma-Ray2 achieves top imaging quality, perfect for scenarios prioritizing visual fidelity.
- Veo3 remains the go-to general-purpose solution for balanced, all-around performance.
Model Recommendations by Use Case
- High-motion, dynamic content: Choose models with high dynamic degree and motion smoothness (e.g., Kling-Image2Video-V2-Master).
- Visual fidelity-focused tasks: Select Luma-Ray2 for sharpness and resolution.
- Balanced, multi-purpose applications: Veo3 delivers reliable results across all dimensions
Takeaway: Selecting the right model depends on specific business needs, and multi-dimensional evaluation enables task-driven, customer-specific recommendations.
5.2 Conclusion
- For Content Creators: Provides quantitative guidance for choosing models that balance visual aesthetics, motion realism, and scene stability for storytelling and advertising.
- For Enterprises: Delivers a transparent, data-driven foundation for integrating generative video into commercial pipelines—from marketing automation to personalized media.
- For the AI Ecosystem: Establishes a reproducible, standardized evaluation protocol aligned with real-world content quality expectations, accelerating model maturity and responsible deployment.
- For Benchmarking Trends: Shifts the focus from subjective human scoring to automated, multi-dimensional analytics, marking a new phase in AI evaluation transparency and scalability.
Forward-Looking Commentary
Future iterations will incorporate human perceptual scoring, prompt-style diversity tests, and support for multiple new benchmarks presented at ICCV 2025, establishing a foundation for the world’s first end-to-end commercial Video AI Benchmark. This roadmap enables continuous improvements in model design, evaluation methodology, and business-tailored AI video solutions, while keeping GMI Cloud at the forefront of commercial video AI evaluation and deployment.
Frequently Asked Questions
1. What is the purpose of GMI Cloud’s video AI benchmarking framework?
The framework is designed to provide a commercial-grade, multi-dimensional evaluation of AI video generation models under real-world, production conditions. Its goal is to help businesses, creators, and developers identify which models deliver reliable, high-quality results at scale, beyond what single-dimensional or academic benchmarks can offer.
2. What dimensions are used to evaluate video AI models?
The benchmark evaluates six key dimensions: aesthetic quality, background consistency, dynamic degree, imaging quality, motion smoothness, and subject consistency. Each video is scored across these dimensions, normalized, and aggregated to provide both overall rankings and detailed diagnostic insights.
3. How are videos annotated and evaluated at scale?
GMI Cloud uses a hybrid annotation approach combining Retrieval-Augmented Generation (RAG) and DeepSeek. RAG provides diverse, reference-based prompts drawn from existing benchmarks, while DeepSeek analyzes the generated videos directly to assign dimension-level scores. This enables scalable, automated evaluation without manual scoring.
4. Which models performed best in the benchmark results?
Seedance-1-0-pro-250528 achieved the highest overall score, excelling in motion energy and imaging quality. Veo3 delivered the most balanced performance across all dimensions, making it suitable for general-purpose use. Kling variants excelled in background and subject consistency, while other models showed strengths in specific dimensions but higher variability.
5. Why does multi-dimensional evaluation matter for real-world deployment?
Single aggregate scores can hide important trade-offs. Multi-dimensional evaluation reveals complementary strengths and weaknesses across models, allowing businesses to choose models based on specific needs such as motion realism, visual fidelity, or consistency. This approach supports task-driven, customer-specific deployment decisions and more reliable production outcomes.
Colin Mo
Head of Content
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
