
H100
Hopper · ベースライン
- メモリ
- 80 GB HBM3
- 推論性能
- 1.0×(ベースライン)
主力モデル。汎用 LLM とマルチモーダル推論向け。ほとんどの本番ワークロードはここから始まります。
Prime Inference は、モデルごとに最適化された予約済み GPU 容量と、動くプロトタイプを本番システムへと進化させるエンジニアリングパートナーシップを提供します。
H100 · H200 · Blackwell
NVIDIA 認定ハードウェア
99.9% 稼働率
本番 SLA

パフォーマンス、リーチ、そして弾力性 — 実際の本番トラフィック向けに設計され、あらゆる規模に対応します。
スループット 2 倍
トップパフォーマンス
カーネル、スケジューリング、ルーティングを含むモデルごとのランタイム最適化により、主要なオープンソースモデルで汎用スタックの最大 2 倍の持続的スループットを実現します。
参考ベンチマーク。実際のパフォーマンスはモデルとワークロードにより異なります。
3 大リージョン
低レイテンシ
APAC、北米、ヨーロッパに展開するシングルテナント容量。低 TTFT のためのリージョンピン、データレジデンシーのためのリージョンロック — 市場に合わせた最適なデプロイを実現します。
業界最高水準
弾力性を前提に設計
バーストでスパイクを吸収し、閑散時はドレインしてコストを削減。他のプラットフォームが解決できない課題をすでに克服し、プロビジョニングのさらなる高速化も進行中です。
予約済み容量は実際の本番トラフィックに報い、モデルごとのランタイム最適化が時間とともにその優位性を積み重ねます。
汎用スタックではなく、モデルごとのカーネル、スケジューリング、ルーティング最適化。モデルを選べば、エンジン部分は私たちが担当します。
予約済み GPU は重みをプリロードしてウォーム状態を維持。すべてのコールが即座にヒット — コールドスタートの遅延も、ファーストトークンのジッターもありません。
あなたのワークロード専用に予約された GPU。騒がしい隣人も、負荷時の競合も、共用ティアの想定外も発生しません。
オープンソース、ファインチューニング済み、独自のいずれの重みにも対応。Hugging Face、S3、または独自のストレージから読み込み — それを適切に提供するために構築されたランタイム上で。
私たちの推論エンジニアが最も多くデプロイされているオープンソースモデルのランタイムを継続的にチューニング — モデルを選んだ瞬間、カーネル作業はすでに完了しています。
vLLM、TensorRT-LLM、SGLang を GPU クラスごとに事前最適化。量子化は設定可能。マルチ GPU オーケストレーションにも対応。
ファーストトークン遅延のためにエンドポイントをリージョンピン、またはデータレジデンシーのためにリージョンロック。
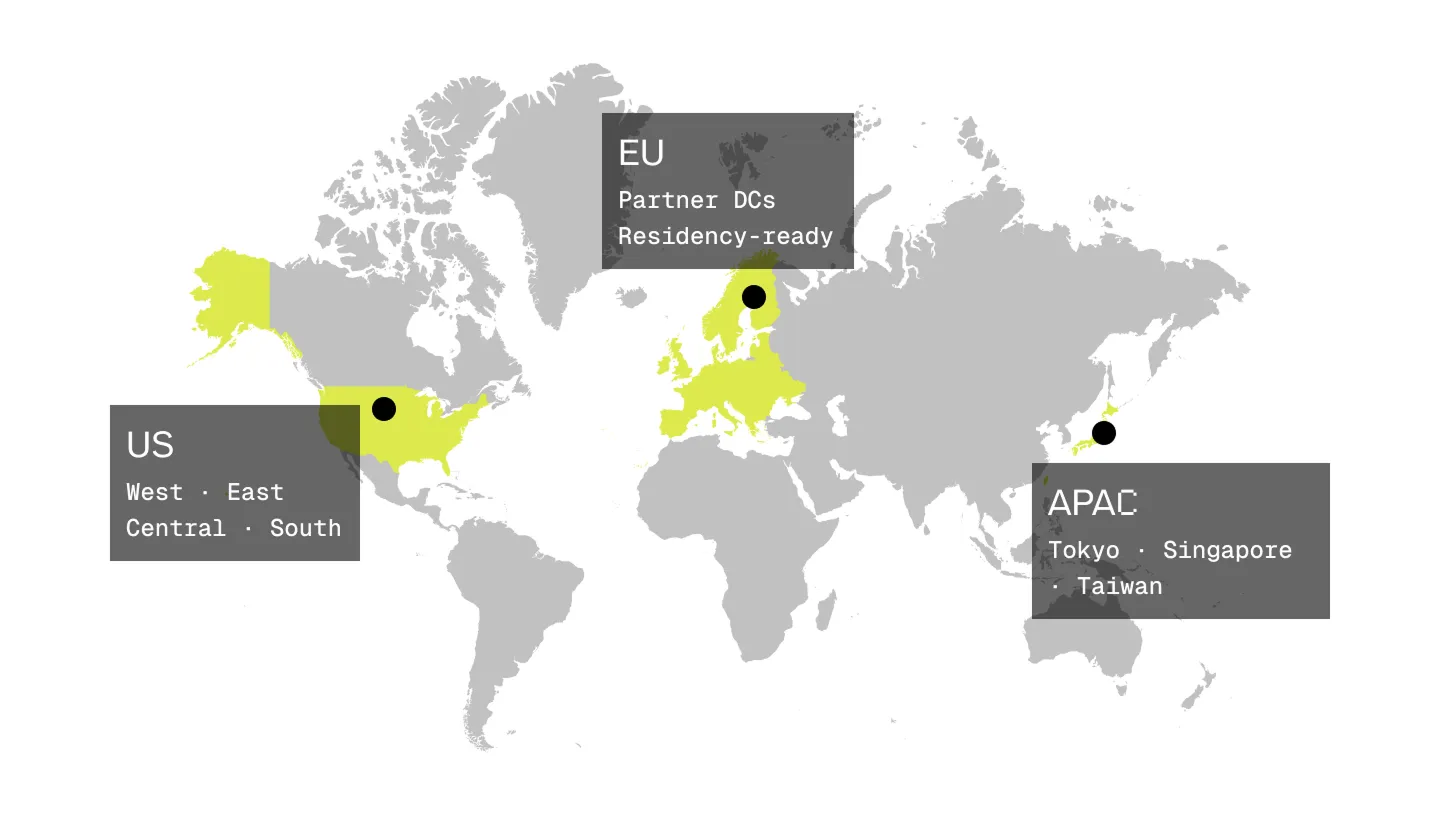
東京 · シンガポール · 台湾 — 最も急成長する AI 市場に対応。
米国 西部、東部、中部、南部 — 高スループットの本番トラフィック向け。
EU パートナーデータセンター — レジデンシーとコンプライアンス要件のあるワークロード向け。
保証されたパフォーマンスが必要なときは予約容量、需要が急増したらバースト容量、減少したらドレイン。実際に使った分だけお支払いください。
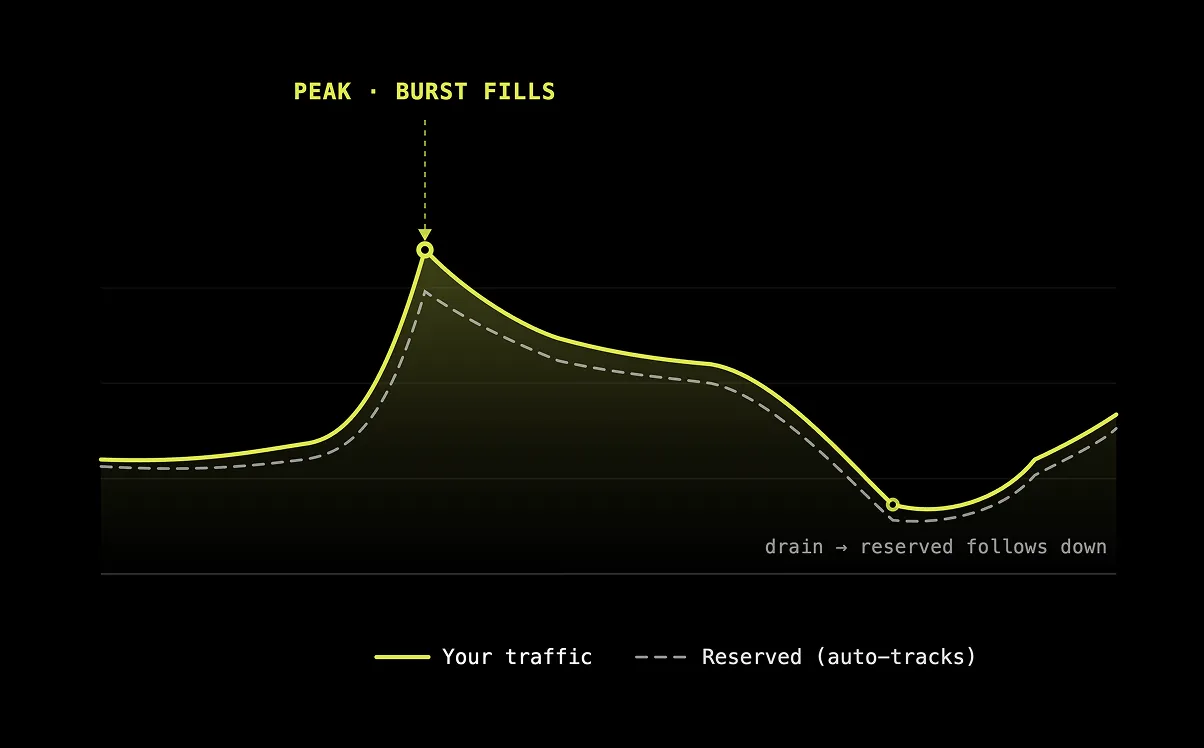
スパイクは自動的に吸収されます。キューイングなし、手動スケーリングなし、デモやリリース時のリクエスト失敗もありません。
閑散時間帯はコストが下がります。実行中のコールを中断することなく、容量がスムーズに縮小されます。
ホームリージョンが容量上限に達した場合、トラフィックは最も近いリージョンから容量を借りて、低遅延とサービス継続性を維持します。
モデルを選び、ハードウェアを選び、デプロイ。プラットフォームがモデルの読み込み、リソースのオーケストレーション、ルーティングを処理 — 選択から稼働中の API まで数分で到達します。
任意のオープンソースモデル、Hugging Face のあらゆるモデル、または独自の重みをアップロード。
GPU タイプ、レプリカあたりの GPU 数、レプリカ数、ターゲットリージョンを指定。
コンソール、CLI、または API から起動。エンドポイントは数日ではなく数分でライブに。
レイテンシとスループットを監視。トラフィック急増時はバースト、減少時はドレイン。
DeepSeek、Kimi、GLM、Llama、NVIDIA など、主要なオープンソースモデルをワンクリックでデプロイ。フロンティア LLM からビジョン、音声、マルチモーダルまで — モデルを選べば、本番エンドポイントが手に入ります。
deepseek-ai
moonshot-ai
zhipu-ai
meta-llama
nvidia
予測可能性、スループット、エンジニアリングパートナーシップが、動くプロトタイプを信頼できるプロダクトへと変える本番トラフィックパターン。
タスクあたり多数の短いコール。最初のコールのレイテンシがユーザー体験を左右します。ツール利用は速いだけでなく信頼性も必要です。
エージェントフリートごとに安定したエンドポイント · ウォーム容量 · デモやリリース時のコールドスタートなし。
音声はばらつきを許容しません。ウォーム容量上での持続的な WebSocket セッション。短いラウンドトリップのためにリージョンピン。
1 秒未満のファーストバイト TTS · ストリーミングエンドポイント · 共用ティアによるジッターなし。
ハードウェア性能の上限まで活用して、毎日数百万のクエリを維持。長文コンテキストのワークロードでも一貫したテール遅延を確保。
最適化された KV キャッシュ · P95/P99 を制御 · 共用プールでの競合なし。
分離されたランタイム、監査ログ、ゼロリテンション配信。金融、ヘルスケア、公共部門のためのリージョンロック。
EU レジデンシー対応 · シングルテナント分離 · エンタープライズ SLA。
Hopper、Hopper リフレッシュ、そして Blackwell — メモリフットプリント、コンテキスト長、フロンティア性能ニーズに応じて選択。
Hopper · ベースライン
主力モデル。汎用 LLM とマルチモーダル推論向け。ほとんどの本番ワークロードはここから始まります。

Hopper リフレッシュ
メモリを多用するワークロード向け — 長文コンテキスト、大きな KV キャッシュ、大きなバッチサイズ。

Blackwell · フロンティア
フロンティアモデル、FP4 推論、最大スループット。性能が重要なワークロード向け。
よくあるご質問

コンソールから Prime Inference エンドポイントを立ち上げ — または予約容量、カスタムチューニング、トライアルクレジットについて営業までお問い合わせください。