



This article explains why multimodal inference is significantly more complex than single-model serving, and how cloud GPU platforms are designed to handle the coordination, latency, and scaling challenges involved.
What you’ll learn:
- Why multimodal inference involves orchestrating multiple specialized models, not just one
- How latency compounds across text, vision, and audio pipelines
- Why different modalities require different GPU types and configurations
- How data movement and scheduling become major bottlenecks in multimodal systems
- Why multimodal workloads amplify cost and reliability issues
- How cloud GPUs enable parallelism, specialization, elasticity, and resilient production inference
Multimodal models promise richer interactions by combining text, vision, audio and structured data into a single system. In practice, however, serving these models in production is significantly more complex than running a single-modality LLM. Multimodal inference introduces coordination challenges that stress infrastructure in ways many teams underestimate until systems are already live.
The difficulty is not simply that multimodal models are larger. It is that they behave differently at runtime. They trigger multiple inference paths, operate on heterogeneous data types and depend on tightly coupled pipelines where latency compounds across stages.
Cloud GPUs have emerged as the most effective way to manage this complexity – not just because of raw compute power, but because of how they enable scheduling, parallelism and resource specialization at scale.
Multimodal inference is not one model, but many
A common misconception is that multimodal inference involves a single unified model handling all inputs. In reality, most production systems rely on a collection of specialized components working together.
A user request may first be processed by a vision encoder, then passed through a text model, followed by an embedding or reranking step, and finally routed to a generation model. Audio pipelines may add speech-to-text and text-to-speech stages. Each step has distinct compute, memory and latency characteristics.
This makes multimodal inference fundamentally different from single-model serving. Performance is determined by how well these components are orchestrated, not just how fast any individual model runs. If one stage stalls, the entire pipeline slows down.
Latency compounds across modalities
Latency in multimodal systems is cumulative. A few extra milliseconds at each stage quickly add up to noticeable delays at the user level. This is especially problematic for interactive applications such as conversational agents, real-time vision systems or multimodal search.
Traditional inference setups often process stages sequentially, routing outputs from one model to the next. When this happens on limited infrastructure, GPUs can spend significant time idle between steps while waiting for downstream processing.
Cloud GPUs make it possible to parallelize stages where appropriate, overlap computation and reduce end-to-end latency. Instead of forcing all modalities through a single execution path, workloads can be distributed intelligently across multiple GPUs, minimizing wait time and keeping pipelines flowing.
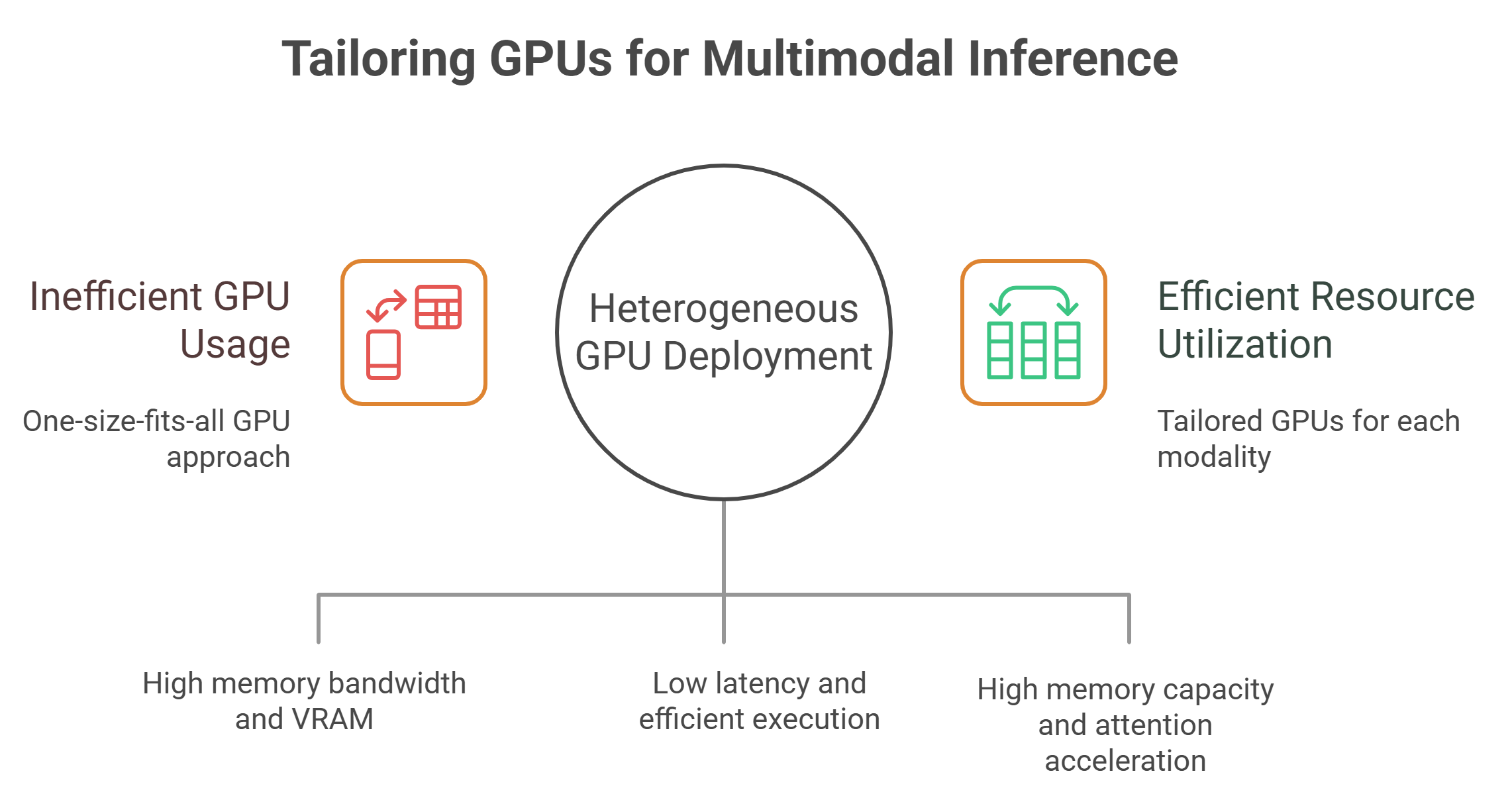
Different modalities demand different GPU characteristics
Not all inference workloads stress GPUs in the same way. Vision models often require high memory bandwidth and large VRAM for processing high-resolution inputs. Audio models tend to be latency-sensitive but lighter in memory usage. Large language models demand both high memory capacity and efficient attention computation.
Routing all of these workloads to the same GPU type is inefficient. It increases contention, inflates cost and can degrade performance for every modality involved.
Cloud GPU platforms enable heterogeneous deployments, where each stage of a multimodal pipeline runs on the GPU best suited to its needs. Embedding models may run on dense-throughput GPUs, while generation models use high-memory instances. This specialization is difficult to achieve in static, on-prem environments but becomes practical in the cloud.
Data movement becomes a bottleneck before compute does
In multimodal inference, moving data between stages can be more expensive than computation itself. Images, audio streams and intermediate embeddings all need to flow between models quickly and reliably.
Poorly designed infrastructure introduces serialization, network congestion and unnecessary copies between CPU and GPU memory. These inefficiencies silently erode performance and make systems harder to scale.
Cloud GPU environments designed for AI workloads invest heavily in high-bandwidth networking and optimized data paths. By keeping data close to where it is processed and minimizing transfers between components, they reduce overhead that would otherwise dominate multimodal pipelines.
Scheduling complexity increases dramatically
Single-model inference can often rely on straightforward request batching and autoscaling. Multimodal inference breaks these assumptions.
Requests may fan out into multiple sub-requests, each with different execution times. Some stages benefit from batching, others do not. Traffic patterns become uneven, with bursts concentrated on specific modalities depending on user behavior.
Effective scheduling in this context requires real-time awareness of queue depth, GPU availability and pipeline dependencies. Cloud GPU platforms with intelligent scheduling systems can adapt dynamically, ensuring that no single stage becomes a bottleneck that starves the rest of the pipeline.
Multimodal systems amplify cost inefficiencies
Because multimodal pipelines involve multiple models, inefficiencies multiply quickly. An idle GPU at one stage wastes compute not just for that model, but for every downstream component waiting on it.
Teams often discover that multimodal inference costs grow faster than expected, even when request volumes are modest. This is rarely due to model size alone; it is usually the result of poor utilization, overprovisioned instances or sequential execution patterns.
Cloud GPUs help mitigate this by allowing fine-grained scaling. Individual stages can scale independently based on demand, rather than forcing teams to scale entire pipelines uniformly. This keeps cost per request predictable even as workloads become more complex.
Reliability and failure handling are harder across modalities
Multimodal inference pipelines have more failure points. A vision encoder crash, an audio preprocessing timeout or a generation model slowdown can all break the user experience.
In tightly coupled systems, these failures cascade unless the infrastructure can isolate and recover individual stages. Cloud GPU platforms support this through workload isolation, health checks and rapid rescheduling. Failed components can be restarted or rerouted without taking down the entire pipeline.
This resilience is critical for production deployments where uptime and consistency matter as much as raw performance.
Why cloud GPUs are better suited than traditional setups
Traditional VM-based or on-prem GPU setups struggle to meet the demands of multimodal inference. They are often static, difficult to scale dynamically and limited in their ability to mix GPU types or adjust scheduling policies.
Cloud GPU platforms are built around the assumption that workloads are dynamic and heterogeneous. They support elastic scaling, intelligent routing and deep observability – all of which are essential for running multimodal systems efficiently.
As multimodal models evolve to include more modalities and deeper interactions, these capabilities become less optional and more foundational.
Designing multimodal inference for the long term
Multimodal inference introduces real operational complexity, and that complexity is only increasing as models blend text, vision, audio and structured reasoning.
Infrastructure that cannot support parallelism, specialization and dynamic scaling quickly becomes a bottleneck.
Cloud GPUs make it possible to run these systems efficiently, allowing teams to focus on improving capabilities and user experience rather than compensating for infrastructure limits.
Frequently Asked Questions about Why Multimodal Inference Is Harder – and How Cloud GPUs Solve It
1. Why is multimodal inference harder than serving a single-modality LLM?
Because multimodal inference isn’t just “a bigger model.” In production, it usually behaves like a tightly coupled pipeline with multiple inference paths, different data types (text, vision, audio, structured data), and stage-by-stage dependencies where delays compound across the system.
2. Is multimodal inference really one model handling everything?
Not usually. Most production setups are a collection of specialized components working together—like a vision encoder, a text model, an embedding or reranking step, and a generation model. Audio can add speech-to-text and text-to-speech stages. Performance depends on orchestration, not just how fast one model runs.
3. Why does latency get worse in multimodal systems?
Because latency is cumulative. A few extra milliseconds at each stage can stack into noticeable end-to-end delays—especially in interactive use cases like conversational agents, real-time vision systems, or multimodal search. If stages run sequentially, GPUs can also sit idle while waiting for downstream steps.
4. Why do different modalities need different kinds of GPUs?
Because each modality stresses hardware differently. Vision workloads can need high memory bandwidth and large VRAM for high-resolution inputs, audio tends to be latency-sensitive but lighter in memory, and LLM generation needs high memory capacity plus efficient attention. Putting everything on one GPU type increases contention, cost, and performance issues.
5. Why does data movement become a bottleneck before compute?
Multimodal pipelines move heavy and varied data between stages—images, audio streams, intermediate embeddings. If infrastructure causes serialization, network congestion, or extra CPU↔GPU copies, performance quietly degrades and scaling becomes harder. Keeping data close to where it’s processed and minimizing transfers reduces that overhead.



