
Revisiting DeepSeek’s Impact: Half a Year Later
TL;DR
DeepSeek’s cut‑rate model rattled tech markets in January, yet compute demand has only climbed, open‑source models keep improving, and inference token burn (the rate of token consumption) has jumped up almost 500% in half a year. Instead of a bubble that’s burst, we’re seeing a wave that’s only just starting.
Let’s revisit what’s happened.
Flashback to January’s Panic
On 27 January DeepSeek released a low‑cost, open‑source model that sent shockwaves through Wall Street. Commentators declared the ‘AI bubble’ had popped as AI-related stocks collectively shed over half a trillion dollars in value.
What happened? People panicked about DeepSeek’s R-1 model being able to compete with top closed-source proprietary models despite utilizing only simple computing power for training. They erroneously believed that since models could utilize new techniques designed for minimal computing power needs, then that would result in no further growth in demand for compute power.
However, demand for GPUs never slowed because builders kept inventing new use‑cases once model costs dropped. Demand for inference shot up as a result of DeepSeek’s open-source model, which still required computing infrastructure to run. Capital followed utilization, not headlines, and the hardware supply chain is still catching up to demand.
So, what actually happened with that fiasco? And, where is compute demand going from here?
The Quality Delta Has Collapsed Between Open‑Source vs Closed
- DeepSeek, Qwen, LlaMa, and now even ERNIE are directly competitive to top closed-source performance when it comes to intelligence benchmarks. They might not be explicitly better (leaderboards change every week at this point), but then there’s an ROI question…
- Wrappers around closed‑source APIs are discovering that “technically better” rarely justifies higher operating costs. At time of writing, GPT-5 (high) is a mere 10 points more intelligent than Qwen3-235B (or about 18% difference) while having about a 90-97% difference in cost. Unless every single query pushes the limits of intelligence, it’s just burning money!
- Strategic risk sits with any team that cannot control the price of its own inference stack. A single price increase from a closed-source provider can slash gross margin overnight, making it a Sword of Damocles hanging above every roadmap. “Assuming our closed-source model provider doesn’t change their pricing model…” will become a staple in front of every financial forecast.
AI Is Just Beginning
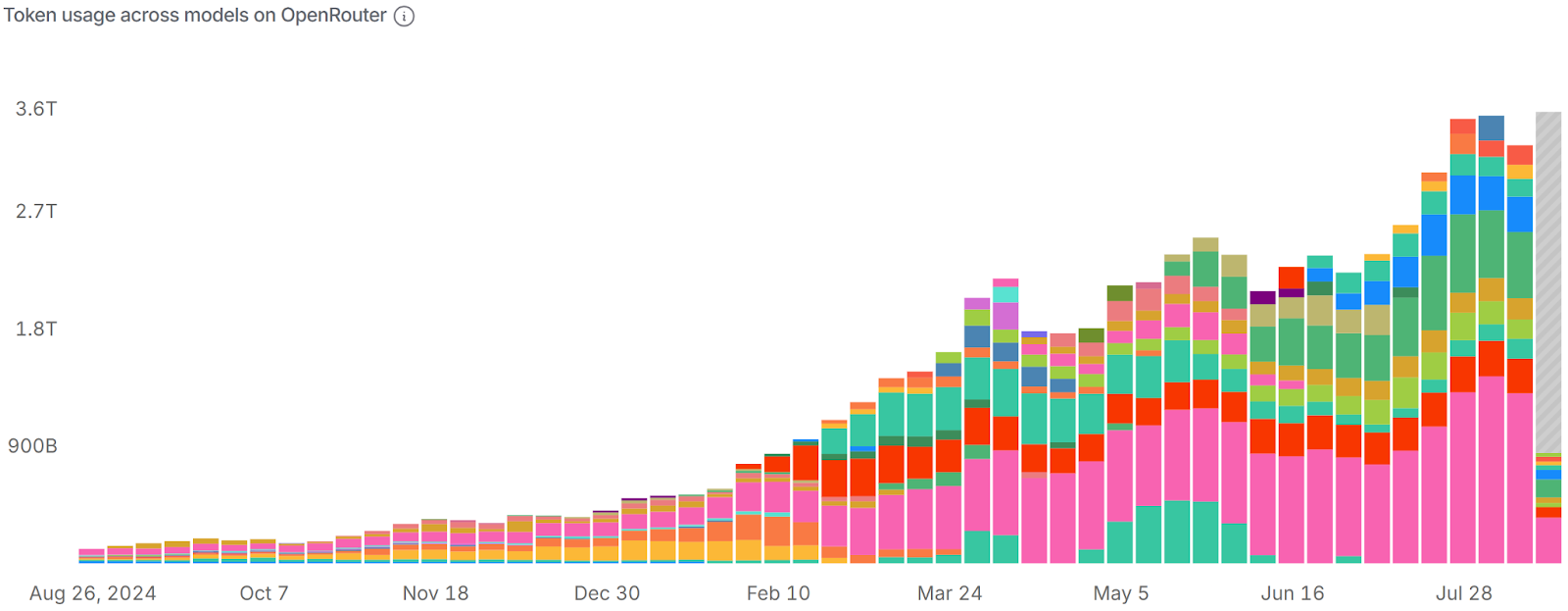
Since Jan 27, token burn on OpenRouter alone went from 572B to 3.41T on Jul 28, representing 496% growth in 6 months. While OpenRouter isn’t the full picture of inference consumption, we expect the global demand chart to look similar if not even more drastic.
This tells us: Demand for compute never went away, it merely shifted downstream from machine learning training into inference.
When roads get paved the question quickly shifts from asphalt to automobiles. Having a good model was the barrier-to-entry; now that open-source is competitive, the underlying prices have fallen while the number of cars on the road exploded. Anyone can now drive, so competition moves up‑stack to what you build on top of cheap inference: vertical copilots, embodied agents, synthetic data pipelines, and real‑time multimodal interfaces.
We've seen unprecedented growth in compute demand for inference alone. As the focus shifts into people and companies building new use-cases for the end-result of AI — currently, inferencing — we're constantly slammed with demand, averaging a greater than 95% usage capacity for any given time of note. Data centers cannot be built fast enough to supply computing needs, and our own new Denver data center expansion came online and sold out immediately, many ask why we didn’t set out plans to build more in this time period.
How much is the current demand for AI? We can’t share our full internal dashboard yet, but OpenRouter’s public stats are directionally similar. Take a look at our growth in token-burn on OpenRouter alone despite being a new inference provider that launched in March 2025.
In the last 24 hours alone (snapshot 9/15), the most requested models on our platform were:
- DeepSeek-V3-0324 — 54.89%
- DeepSeek-v3.1 — 16.86%
- Qwen3-Coder-480B-A35B-Instruct-FP8 — 8.05%
- Qwen3-235B-A22B-Instruct-2507-FP8 — 3.99%
- Qwen3-Next-80B-A3B-Instruct — 3.38%
- Kimi-K2-Instruct-0905 — 2.99%
- Gpt-oss-120b — 2.73%
- Llama-4-Maverick-17B-128E-Instruct-FP8 — 2.36%
- Llama-4-Scout-17B-16E-Instruct — 1.52%
- The rest is other models
In fact, you may already be using the end products utilizing our token assembly lines!
The View from a Provider
Whether training or running inference, you still need computing.
At GMI Cloud, we serve demand for production-scale workloads on our GPU cloud, recognized as a NVIDIA Reference Cloud Platform Provider. Whenever we find ourselves with excess computing capacity, we feed it into our own inference engine to provide an inference API for customers who just want Model-as-a-Service.
We’re seeing builders move fast, ship agent copilots, experiment with retrieval-heavy use cases, and run multimodal pipelines with open checkpoints. And they choose us because we run hot, stay stable, and support the open models they care about.
Every rack we add plugs into a broader thesis: that AI Factories won’t look like generic clouds pivoting to serve the needs of AI builders. The hyperscaler refugees escaping vendor-lock are looking for specialized AI assembly lines tuned for vertical jobs, and few things look worse on the burn sheet than hyperscaler bills once the free credits run dry.
The Value of Compute Going Forward
As costs per token fall, aggregate demand for computing only grows given newly viable business models. The companies that secure predictable, affordable GPU supply are saving money while they unlock entirely new categories of products. Reliable compute allows for:
- Faster iteration: builders can test, fine‑tune, and ship without worrying about runaway costs.
- Vertical specialization: compute tuned to specific industries (finance, biotech, media) makes models more useful and defensible.
- Long‑term advantage: just as electricity defined industrial winners, GPU capacity will define AI winners.
The economic numbers don’t lie: unit prices are trending downward, but aggregate consumption is compounding upward. Compute is the foundation for every AI factory line being built today.
Looking forward 6–12 months, the arrival of Blackwell and expanded H200 deployments will further reshape economics. These chips are designed for inference throughput, pushing cost per token even lower while allowing workloads once reserved for training clusters to run in real time. As inference demand begins to structurally outpace training, the bottleneck shifts from model quality to compute availability. The winners will be those who lock in reliable supply early and turn it into differentiated products.
We recently launched On-Demand Bare Metal as a Service on our Cluster Engine to bring operational agility to companies at affordable prices.
Build AI Without Limits.
Frequently Asked Questions
1. Why did DeepSeek’s January release trigger fears of an AI bubble bursting?
DeepSeek released a low-cost, open-source model that appeared competitive with top closed-source models while using relatively modest training compute. This led to the mistaken belief that future AI progress would require less computing power, causing panic in public markets and a sharp sell-off of AI-related stocks.
2. Did DeepSeek’s release actually reduce demand for GPU compute?
No. Compute demand continued to rise. Lower model costs enabled more builders to deploy AI in production, which sharply increased inference usage. Instead of reducing demand, DeepSeek shifted compute consumption downstream from training into large-scale inference workloads.
3. How has inference demand changed since January?
Inference demand has surged dramatically. Token burn on OpenRouter alone grew from 572 billion tokens to 3.41 trillion tokens in six months, representing nearly 500% growth. This indicates that inference, not training, has become the dominant driver of compute demand.
4. Why are open-source models increasingly favored over closed-source APIs?
The performance gap between open-source and closed-source models has narrowed significantly, while cost differences remain extreme. Many teams find that modest intelligence gains from closed-source models do not justify 90%+ higher inference costs or the strategic risk of pricing changes they cannot control.
5. What does this shift mean for the future value of compute?
As per-token costs fall, total compute consumption continues to compound. Reliable and affordable GPU supply is becoming a long-term competitive advantage, enabling faster iteration, vertical specialization, and new AI-driven business models. The bottleneck is increasingly compute availability, not model quality.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
FAQ
