




AI 活用を拡大する企業にとって、選択肢は「オンプレかクラウドか」だけではありません。
近年、多くの先進企業が採用しているのが オンプレミスとクラウド GPU を併用するハイブリッド戦略 です。
ハイブリッド GPU 環境は、コスト・柔軟性・運用制御のバランスを取りながら、オンプレの予測可能性とクラウドの弾力性を両立させます。AI ワークロードが複雑化し変動幅が大きくなるなか、単一のインフラ戦略では対応が難しくなっています。学習と推論の需要は大きく揺れ動き、用途によって最適な基盤も変わるためです。
ハイブリッド戦略は、企業が無理にどちらかに固定されることなく、「必要なときに必要な場所で」スケールできる実用的なアプローチです。
なぜハイブリッド GPU 戦略が注目されているのか
AI の計算需要は一定ではありません。
実験段階では比較的少ないリソースで足りますが、大規模学習や本番推論へ移行すると、短期間で計算需要が急増することがあります。
ピーク需要に合わせてオンプレ GPU を過剰に購入すると、多くの時間はアイドル状態となり、投資が無駄になります。
一方、クラウド GPU は伸縮性に優れていますが、一定のワークロードをクラウドだけで処理し続けるとコストが高騰します。
そこで効果的なのがハイブリッドです。
- 安定した基幹ワークロードはオンプレで処理
- 短期的なピークや特殊用途はクラウドにオフロード
この組み合わせにより、無駄なハードウェア投資を避けつつ、必要なときにスケールさせることができます。既にオンプレ GPU を保有する企業にとって、クラウドを計算能力の「拡張レイヤー」として活用するメリットは特に大きいといえます。
コスト最適化:ハイブリッドの最も分かりやすい利点
ハイブリッド環境の最大の強みの一つが コスト制御 です。
- オンプレ GPU:初期投資は必要だが、継続コストが低い(安定需要向け)
- クラウド GPU:初期投資不要だが、長時間利用すると高コスト(変動需要向け)
そのため、多くの企業は以下の方法を採用しています:
オンプレは平常時のワークロードに合わせて最適化し、ピーク時のみクラウドを利用する。
これにより、ハードウェアを遊ばせず、必要なときにだけコストを支払う運用が可能になります。
また、クラウドの予約インスタンスとオンデマンドを併用することで、さらに細かいコスト最適化もできます。
ハイブリッド環境における性能面での判断
性能を最大化するには、「適材適所」でワークロードを配置する必要があります。
- 低レイテンシ・データ量の大きい処理 → オンプレ
(データ移動を最小化できるため) - 分散学習・ハイパーパラメータ探索・バースト向け推論 → クラウド
(並列処理と弾力性が強い)
ただし、オンプレとクラウド間のデータ転送が遅いと性能が低下するため、高速ネットワークや効率的なデータパイプライン設計が重要です。
セキュリティ・コンプライアンス・ガバナンス
金融・医療など規制の厳しい業界では、敏感データを外部に出せないケースが多く、オンプレ運用が必須です。
しかし、ハイブリッド構成なら:
- 機密データはオンプレで処理
- 一般的な学習や推論はクラウドで処理
といった “ワークロードの分離” ができ、セキュリティと柔軟性を両立できます。
暗号化、アクセス制御、監査ログなどにより、安全なデータ移動も可能です。
ハイブリッドを活かしたインテリジェントなスケーリング
オンプレは安定性があるものの、即時拡張は難しい。
クラウドは瞬時に拡張できるが、長期間利用は高コストになりがち。
両者を組み合わせることで:
- 基幹処理はオンプレで安定稼働
- 急増する需要はクラウドの自動スケーリングで対応
という理想的な構成が実現します。
新規プロジェクトや新地域展開にも迅速に対応でき、調達リードタイムを気にする必要がありません。
運用:可視化・スケジューリング・オーケストレーションの重要性
ハイブリッド環境を効率的に動かすには:
- すべての GPU(オンプレ+クラウド)の可視化
- コスト・性能の一元管理
- 賢いジョブスケジューリング
- データ所在に応じた実行場所の自動判断
が欠かせません。
Kubernetes のような基盤を使えば、オンプレとクラウド GPU を 単一のコントロールプレーンで統合管理 できます。
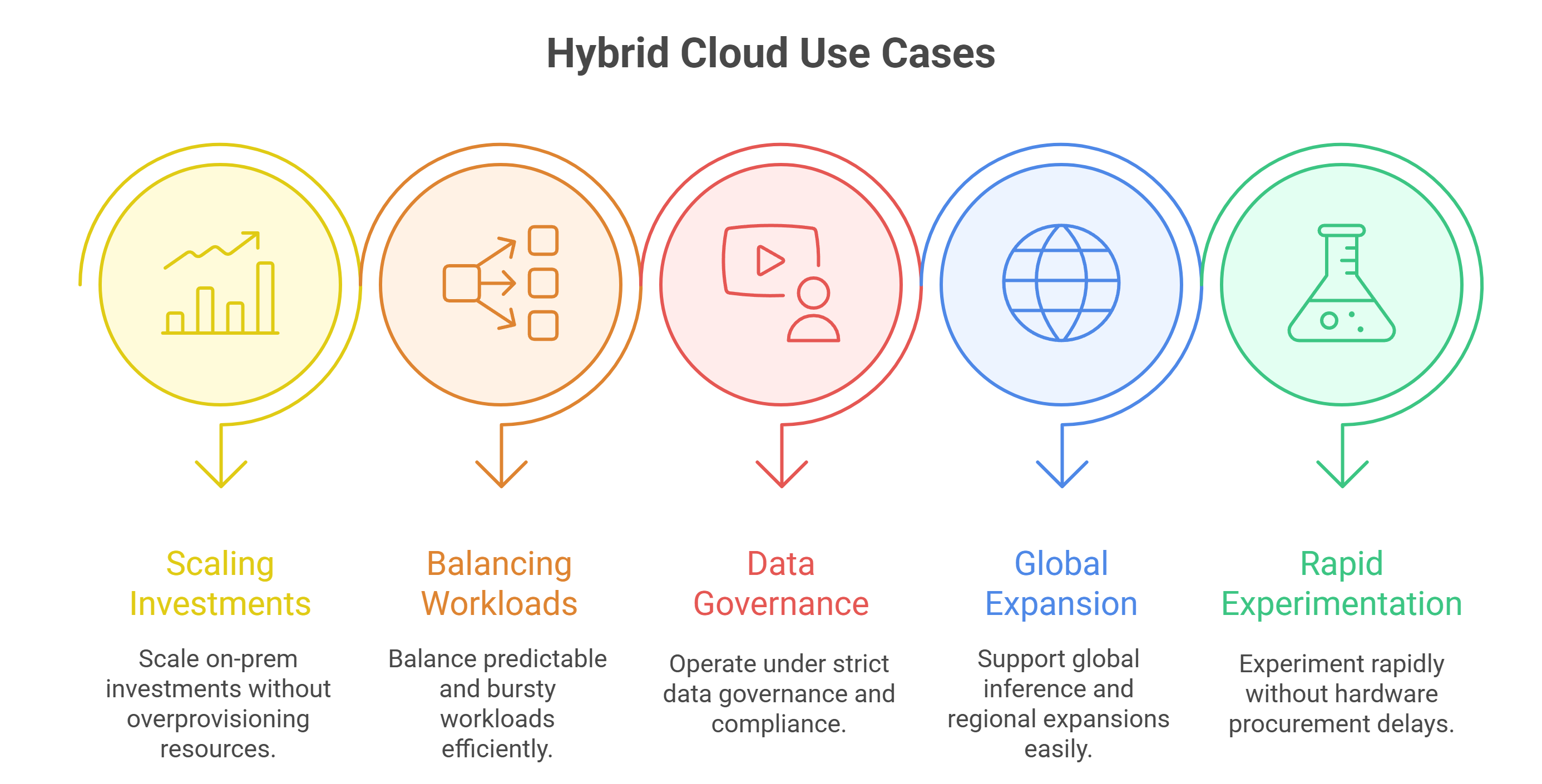
ハイブリッド GPU が最適となるケース
ハイブリッドは万能ではありませんが、以下の状況では特に相性が良いです:
- 既存のオンプレ資産を活かしつつ拡張したい
- 安定 workload と突発 workload を両方抱えている
- データガバナンスが厳しい
- グローバル推論を提供したい
- ハードウェア調達を待たずに迅速に実験したい
GMI Cloud が実現するハイブリッド展開
GMI Cloud は、オンプレ GPU とクラウド GPU をシームレスに統合できるよう設計されています。
- オンプレ環境とのスムーズな統合
- 高帯域ネットワーク接続
- オートスケーリング
- コストと利用状況の可視化
- 予約+オンデマンド GPU の柔軟な組み合わせ
- ガバナンス・監査・性能ツールの標準搭載
これにより、企業は 安全で、スケールしやすく、コスト効率の高いハイブリッド GPU 基盤 を構築できます。
まとめ:AI 時代に求められる “二者択一ではない” インフラ戦略
オンプレとクラウドのハイブリッド運用は、両者の長所を最大限に活かすアプローチです。
- コンプライアンス維持
- コスト最適化
- 高速なスケールアウト
- グローバル展開
- 俊敏な実験環境
これらを同時に実現できるのがハイブリッド GPU 戦略です。
いま重要なのは 「オンプレかクラウドか」ではなく、「どう組み合わせるか」。
適切なオーケストレーションとパートナーを選ぶことで、ハイブリッドは一時的な妥協策ではなく、企業 AI の強力で持続的な基盤となります。



